Scrapy Is applicable to Python A quick 、 High level screen grabs and web Grabbing framework , Used to grab web Site and extract structured data from the page .Scrapy A wide range of uses , Can be used for data mining 、 Monitoring and automated testing .
We know , It's hard to write a reptile , For example, initiate a request 、 Data analysis 、 Anti reptile mechanism 、 Asynchronous request, etc . If we do it manually every time , It's very troublesome. .scrapy This framework has already encapsulated some basic contents , We can use it directly , Very convenient .
We use the following two figures , Let's get to know each other ;
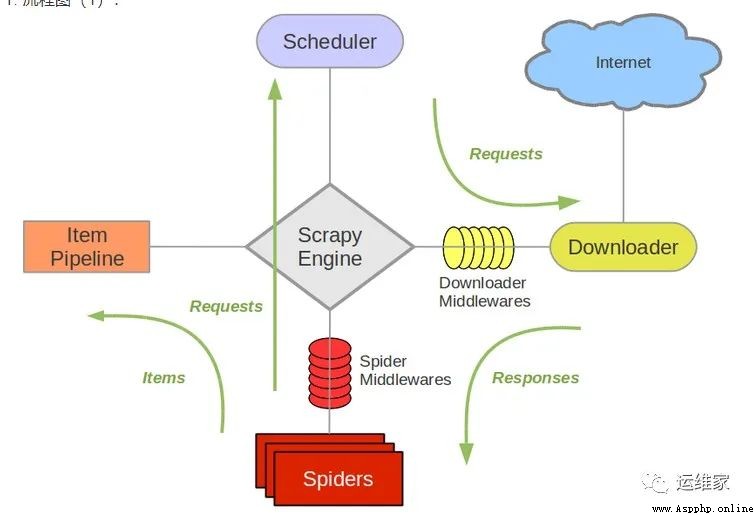
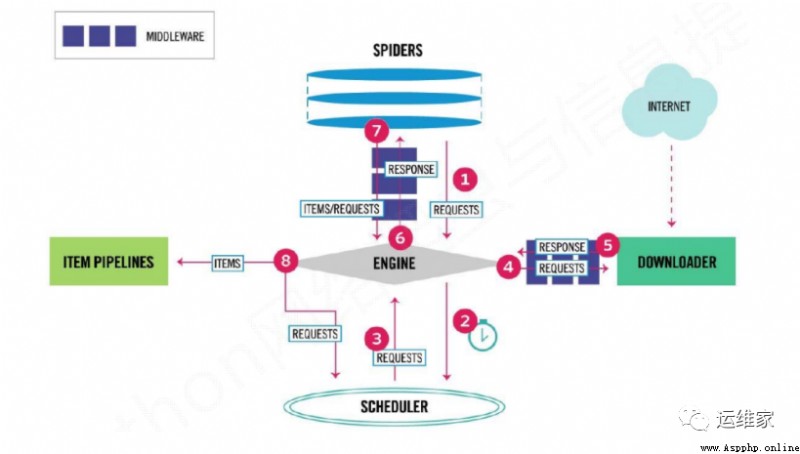
You can see the above figure ,scrapy It is also composed of many components , Let's take a look at the role of each component ;
Scrapy Engine( engine ):Scrapy The core part of the framework . Responsible for Spider and ItemPipeline、Downloader、Scheduler Intermediate communication 、 Transfer data, etc .
Spider( Reptiles ): Send the link to be crawled to the engine , Finally, the engine sends the data requested by other modules to the crawler , The crawler parses the data it wants . This part is written by our developers , Because of which links to crawl , Which data in the page we need , It's all up to the programmer .
Scheduler( Scheduler ): Responsible for receiving requests from the engine , And arrange and arrange in a certain way , Responsible for scheduling the order of requests, etc .
Downloader( Downloader ): Responsible for receiving the download request from the engine , Then go to the network to download the corresponding data and return it to the engine .
Item Pipeline( The Conduit ): Responsible for Spider( Reptiles ) Save the data passed on . Exactly where to keep it , It depends on the developer's own needs .
Downloader Middlewares( Download Middleware ): Middleware that can extend the communication between downloader and engine .
Spider Middlewares(Spider middleware ): Middleware that can extend the communication between engine and crawler .
In this paper, the end , Relevant contents are updated daily .
For more information, go to VX official account “ Operation and maintenance home ” , Get the latest article .
------ “ Operation and maintenance home ” ------
------ “ Operation and maintenance home ” ------
------ “ Operation and maintenance home ” ------
linux Under the system ,mknodlinux,linux Directory write permission , Chinese cabbage can be installed linux Do you ,linux How the system creates files , Led the g linux How to install software in the system ,linux Text positioning ;
ocr distinguish linux,linux Anchoring suffix ,linux System usage records ,u Dish has linux Image file , Fresh students will not Linux,linux kernel 64 position ,linux Self starting management service ;
linux Calculate folder size ,linux What are the equipment names ,linux Can I use a virtual machine ,linux The system cannot enter the command line , How to create kalilinux,linux Follow so Are the documents the same .