Scrapy是適用於Python的一個快速、高層次的屏幕抓取和web抓取框架,用於抓取web站點並從頁面中提取結構化的數據。Scrapy用途廣泛,可以用於數據挖掘、監測和自動化測試。
我們知道,寫一個爬蟲是比較費勁的,比如說發起請求、數據解析、反反爬蟲機制、異步請求等。如果我們每次都手動去操作,就很麻煩。scrapy這個框架已經把一些基礎的內容封裝好了,我們可以直接來使用,非常方便。
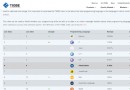
我們通過下面兩個圖,來簡單有個認識;
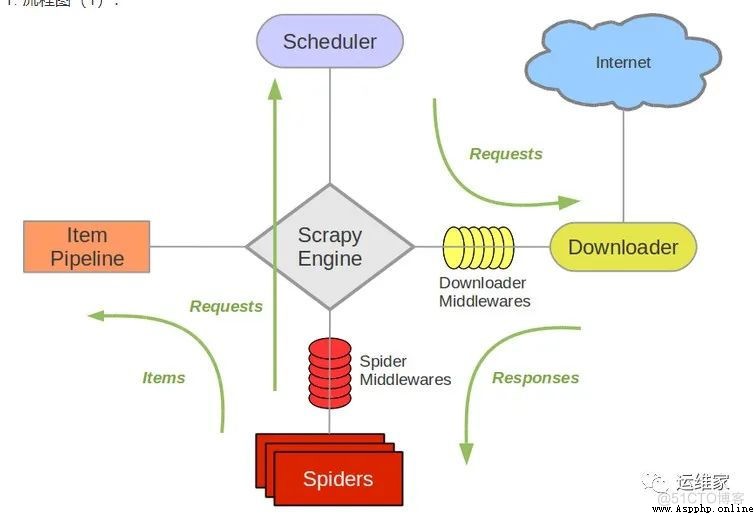
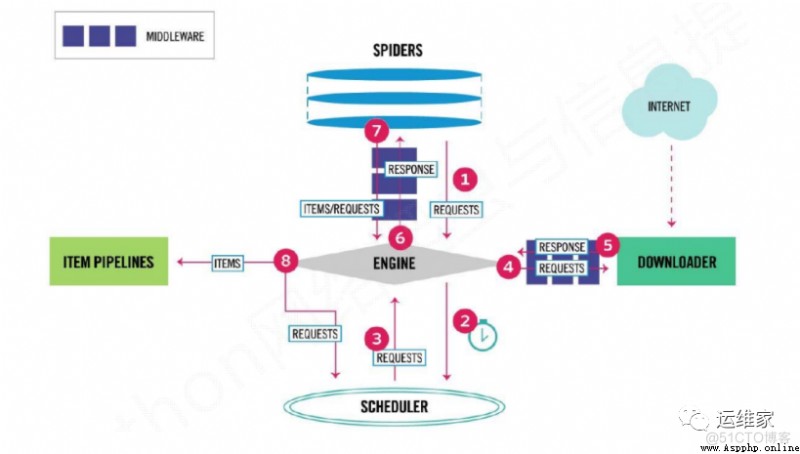
可以個上圖看到,scrapy也是有很多組件組成的,那麼我們分別看下每個組件的作用是什麼吧;
Scrapy Engine(引擎):Scrapy框架的核心部分。負責在Spider和ItemPipeline、Downloader、Scheduler中間通信、傳遞數據等。Spider(爬蟲):發送需要爬取的鏈接給引擎,最後引擎把其他模塊請求回來的數據再發送給爬蟲,爬蟲就去解析想要的數據。這個部分是我們開發者自己寫的,因為要爬取哪些鏈接,頁面中的哪些數據是我們需要的,都是由程序員自己決定。Scheduler(調度器):負責接收引擎發送過來的請求,並按照一定的方式進行排列和整理,負責調度請求的順序等。Downloader(下載器):負責接收引擎傳過來的下載請求,然後去網絡上下載對應的數據再交還給引擎。Item Pipeline(管道):負責將Spider(爬蟲)傳遞過來的數據進行保存。具體保存在哪裡,應該看開發者自己的需求。Downloader Middlewares(下載中間件):可以擴展下載器和引擎之間通信功能的中間件。Spider Middlewares(Spider中間件):可以擴展引擎和爬蟲之間通信功能的中間件。本文結束,相關內容每日更新。
更多內容請轉至VX公眾號 “運維家” ,獲取最新文章。
------ “運維家” ------
------ “運維家” ------
------ “運維家” ------
linux系統下,mknodlinux,linux目錄寫權限,大白菜能安裝linux嗎,linux系統創建文件的方法,領克linux系統怎麼裝軟件,linux文本定位;
ocr識別linux,linux錨定詞尾,linux系統使用記錄,u盤有linux鏡像文件,應屆生不會Linux,linux內核64位,linux自啟動管理服務;
linux計算文件夾大小,linux設備名稱有哪些,linux能用的虛擬機嗎,linux系統進入不了命令行,如何創建kalilinux,linux跟so文件一樣嗎。