之前做游戲開發時,游戲服務端與前端采用Protobuf來進行數據傳輸,為了避免被人惡意破解,還對Protobuf產生的數據做了簡單的偏移處理。最近又要用到Protobuf了,所以簡單記錄一下相關內容。
我們日常使用最多的數據通信格式應該是JSON,但在一些請求很大的應用上,JSON有2個問題:
1.JSON中有很多業務無關數據,如大括號、中括號等,傳輸時,這些數據浪費帶寬。
2.JSON解碼速度慢,量大時,解碼對服務器資源占用大了一些。
Google遇到了這些問題,然後提出了Protobuf,其核心目的就是解決上述2個問題。
Protobuf選擇二進制編碼的形式,將業務數據編碼到其中,不會有無關數據,甚至連字段名都不會編碼進去,這讓帶寬壓力減小,此外Google自己設計了編碼與解碼算法,以保證資源占用合理且盡量快速的特點。
此外,Protobuf還有一個福作用:人類對編碼後的數據比較難讀。這個副作用從一定程度實現數據保護的效果,一些網站利用這個特性實現了反爬。
因為發展原因,Protobuf分為proto2和proto3兩個版本,兩者是不相兼容的,即使用proto2應用無法與使用proto3的應用通信,本文主要討論proto3,且不會涉及proto2與proto3的比較。
使用Protobuf通信的第一步,便是定義出proto文件,我們先展示一個簡單的proto文件,如下:
message Person{
required string name = 1;
message Info{
required int32 id = 1;
repeated string phonenumber = 2;
}
repeated Info info = 2;
}先思考一下,為啥需要proto文件?為何不能像JSON那樣直接使用呢?
回顧一下Protobuf其中一個優點:只編碼業務相關的數據到待傳輸的二進制流中,以節省帶寬。
Protobuf實現這個特點的原理是:通信雙方手裡都拿著定義好的proto文件。
發送方通過這個proto文件定義發送的內容,這些內容不會需要像JSON那樣,有字段名、有括號這些,接收方收到數據後,再利用手裡的proto文件,按算法直接解析裡面的數據。
我一直強調,JSON傳輸時,會有字段名、有括號,可能有人會比較懵逼,還是舉個例子,如下JSON:
{"name": "ayuliao", "age": 30}這段JSON在傳輸時,name和age這兩個字段名也會被傳輸,但這兩個字段名沒啥業務意義,主要就是用來獲取數據的,假設這段數據使用Protobuf傳輸,Protobuf就不會將name和age編碼到數據流裡,只會將ayuliao與30編碼進去,接收方獲得數據後,手裡有一份與發送方一樣的proto文件,然後按proto文件中的格式進行解碼。
思索一下,要在沒有字段名的情況下,合理的解碼Protobuf數據,就必須要求傳輸數據是按一定規則組織的,比如ayuliao必須在30前,這樣我會先解碼ayuliao,再解碼30,至此,我們引入proto文件的一個語法要求,message結構裡的分配標識號不可重復。
看到上面的proto文件,有兩個messge結構,外部的message結構是Person,Person中有有name與info兩個屬性,其中name的分配標識號為1,info的分配標識號為2,在同一個message中,分配標識號不可重復,否則protobuf無法正常使用。
此外,從上面proto文件中也可以發現,message中不同屬性可以有不同的限定修飾符,有3種:
required:發送方發送的數據中必須包含這個字段的值,接收方接收的數據也必須要能識別該字段,大白話,加上required修飾符,這個字段雙方必須使用,否則報錯。
optional:可選字段,發送方可選擇性地發送該字段,接收方如果能夠識別該字段就進行相應解碼處理,如果不能識別,則直接忽略。
repeated:可重復字段,發送方每次發送都可以包含多個值,類似於傳遞一個數組。
在日常使用protobuf時,有兩個常見的tips:
1.分配標識號一般會按業務劃分,不同業務間字段不按大小順序緊密排序,如:
message data {
optional string name = 10001;
optional int32 age = 10002;
optional string job = 20001;
optional string hobby = 20002;
}上述proto,基礎信息(name、age)以1000開頭,其他信息(job、hobby)以2000開頭,這樣後續要添加時,更加清晰,比如要添加性別這個基本信息 :optional string sex = 10003;。
2.很多使用protobuf通信的系統會將字段的限定修飾符設置為optional,這樣系統在升級時,舊版程序無需升級也可以與新程序進行通信,只是對於新字段無法識別而已,這樣可以做到平滑升級。
這裡從網上摘抄了proto文件可以使用的數據類型以及生成到不同編程語言時,在該編程語言中映射的類型,不需記憶,需要時,到此翻一下就好了。
當下,微服務架構比較流行,Python中在這塊常用的通信技術便是Protobuf+gRPC,本文先簡單介紹Protobuf,後面再以本文為基礎,寫一篇Protobuf+gRPC的使用例子。
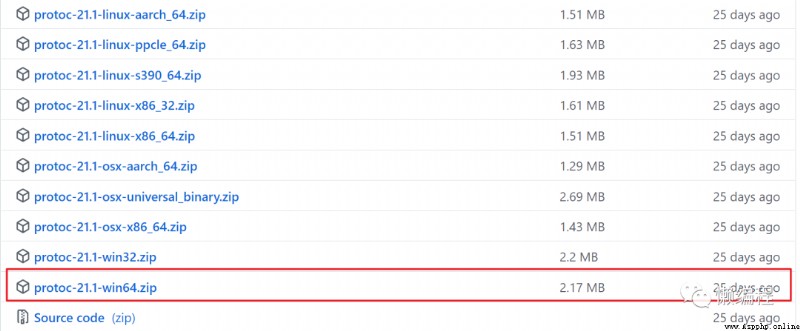
首先,我們需要下載protoc編譯器,通過protoc,我們可以將定義好的proto文件轉成相應編程語言的形式。
下載地址:https://github.com/protocolbuffers/protobuf/releases,如果你跟我一樣,使用的windows 64位的系統,那麼下載win64版本的protoc則可。
隨後,我們定義一個簡單的proto文件,名為demo.proto,內容如下:
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
string email = 3;
string phone = 4;
}通過protoc將demo.proto編譯成Python文件,命令如下(protoc路徑替換成自己的路徑則可):
& "C:\Users\admin\Downloads\protoc-21.1-win64\bin\protoc.exe" --python_out=. demo.proto--python_out用於指定生成Python文件要存放的路徑,隨後緊接demo.proto文件路徑(注意有空格做間隔)。
運行命令後,會生成名為demo_pd2.py的文件。

然後我們導入demo_pd2文件,使用其中的Person類便可以實現Protobuf的編碼與解碼。
通過一段簡單的代碼演示一下:
from asyncore import read
import demo_pb2
R = 'read'
W = 'write'
def fwrb(filepath, opt, data=None):
if opt == R:
with open(filepath, 'rb') as f:
return f.read()
elif opt == W:
with open(filepath, 'wb') as f:
f.write(data)
filepath = './person_protobuf_data'
person = demo_pb2.Person()
person.name = "ayuliao"
person.id = 6
person.email = "[email protected]"
person.phone = "13229483229"
person_protobuf_data = person.SerializeToString()
print(f'person_protobuf_data: {person_protobuf_data}')
fwrb(filepath, W, person_protobuf_data)
data_from_file = fwrb(filepath, R)
parse_person = demo_pb2.Person()
# 沒有數據
print(f'parse_person1 : {parse_person}')
# ParseFromString函數返回解析數據的長度
parse_data_len = parse_person.ParseFromString(data_from_file)
# 解析後,parse_person對象被填充了數據
print(f'parse_person2 : {parse_person}')
print(f'parse_data_len: {parse_data_len}')
print(f'data_from_file lenght: {len(data_from_file)}')上述代碼中,需要注意的是,ParseFromString函數不會直接返回解析後的結果,而是將結果直接填充到調用它的parse_person對象中。
本文討論了protobuf基礎知識,protobuf在通信質量要求比較高的應用中會比較常見,但我個人的觀點依舊是:如無必要勿增實體,如果應用沒有到達需要使用protobuf的地步,還是優先使用HTTP吧。
最後,對於Python入門、Python自動化感興趣的同學,可以入手《Python自動化辦公》這本書籍,目前5折售賣中喲~