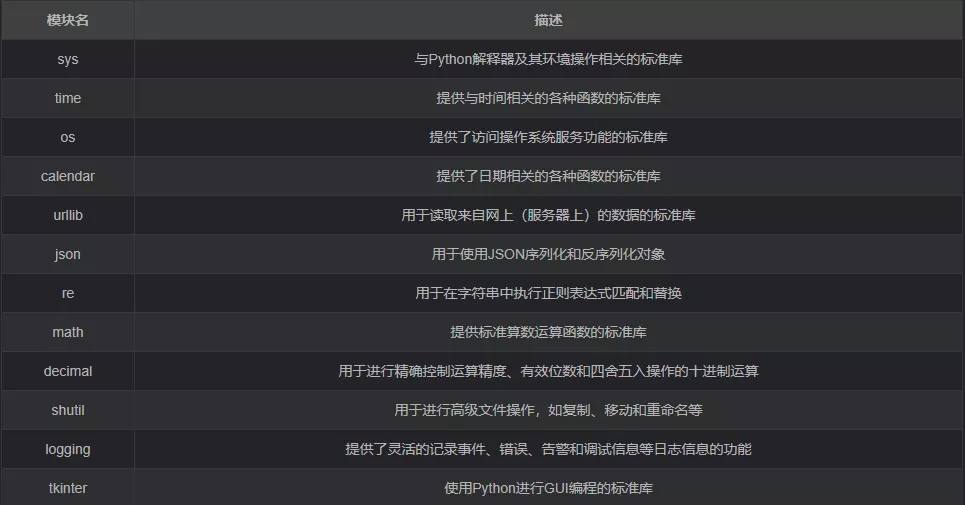
import pandas as pd
import numpy as np
value = np.array([[1, 2, 3, 4], [2, 3, 4, 5], [3, 4, 5, 6]])
index = np.array([10, 20, 30])
column = np.array(['u', 'i', 'r', 'time'])
df = pd.DataFrame(data=value, index=index, columns=column)
''' u i r time 10 1 2 3 4 20 2 3 4 5 30 3 4 5 6 '''
Mainly involves loc and iloc Usage of , The old version of python There's also ix, however ix Has been deprecated by the new edition
.ix is deprecated. Please use
.loc for label based indexing or
.iloc for positional indexing
It's easy to see ,loc Index by attribute name , and iloc Is indexed by column number , Such as df.loc[:, ‘u’] and df.iloc[:, 0] It implements the same function ~
# Filter through a Boolean decision , select time Column greater than 4 The line of
''' u i r time 20 2 3 4 5 30 3 4 5 6 '''
data = df[df.time > 4]
# You can also use to set multiple conditions , If the requirements are added, the score will be 5 The conditions of division
''' u i r time 30 3 4 5 6 '''
data = df[(df.time > 4) & (df.r == 5)]
# Choose the first line ( First line index yes 10)
''' u 1 i 2 r 3 time 4 Name: 10, dtype: int32 '''
data = df.loc[10]
# Select the second and subsequent rows ( Second elements index yes 20)
''' u i r time 20 2 3 4 5 30 3 4 5 6 '''
data = df.loc[20:30]
# perhaps data = df.loc[20:]
# Choose the first column ( In the first column column yes 'u')
''' u 1 i 2 r 3 time 4 Name: 10, dtype: int32 '''
data = df.loc[:, 'u']
# Select the second to fourth columns ( The second column column yes 'i', In the fourth column column yes ‘time’)
''' i r time 10 2 3 4 20 3 4 5 30 4 5 6 '''
data = df.loc[:, 'i':'time']
# Choose the first line
''' u 1 i 2 r 3 time 4 Name: 10, dtype: int32 '''
data = df.iloc[0]
# Select the second and subsequent rows
''' u i r time 20 2 3 4 5 30 3 4 5 6 '''
data = df.iloc[1:3]
# perhaps data = df.iloc[1:]
# Choose the first column
''' u 1 i 2 r 3 time 4 Name: 10, dtype: int32 '''
data = df.iloc[:, 0]
# Select the second to fourth columns
''' i r time 10 2 3 4 20 3 4 5 30 4 5 6 '''
data = df.iloc[:, 1:4]
# Choose the first column ( In the first column column yes 'u')
''' u 1 i 2 r 3 time 4 Name: 10, dtype: int32 '''
data = df['u']
# Use loc
''' u i r 10 1 2 3 20 2 3 4 '''
data = df.loc[10:20, 'u':'r']
# Use iloc
''' u i r 10 1 2 3 20 2 3 4 '''
data = df.iloc[0:2, 0:3]
import pandas as pd
# There are four columns of data , The names are u,i,r and time
#u i r time
#1 3 4 1
#2 1 5 2
#3 1 5 3
#1 3 4 2
#1 3 4 1
df = pd.read_csv('rating.txt', names=['u', 'i', 'r', 'time'])
Obviously , The first data is the same as the fifth data , Data sets need to be de duplicated , The main use is drop_duplicates()
# u i r time
#0 1 3 4 1
#1 2 1 5 2
#2 3 1 5 3
#3 1 3 4 2
data = df.drop_duplicates()
But if you don't think about time , We will find the first 、 Four 、 Five pieces of data are repeated , You can combine the above method of selecting columns to remove duplicates
# u i r
#0 1 3 4
#1 2 1 5
#2 3 1 5
data = df.loc[:, ['u', 'i', 'r']].drop_duplicates()