當我們開始學習Python時,我們會養成一些不良編碼習慣,而更可怕的是我們連自己也不知道。
我們學習變成的過程中,大概有會這樣的經歷: 寫的代碼只能完成了一次工作,但後來再執行就會報錯或者失敗,令人感到懊惱,
或者偶然發現一個內置函數可以讓你的工作更輕松時,瞬間豁然開朗。
我們中的大多數人仍然有很多使用Python的壞習慣,這些習慣在我們學習python的前期就存在,今天你可以通過下面的章節來解
決它們。
當我們為了省事,我們臨時加載包,使用:
1.from xyz import *
這不是一個好習慣,原因很多。僅舉幾個例子:
1.效率低下。如果該模塊有大量的對象,需要等待很長時間,直到所有的object都被導入。
2.可能導致變量名之間的沖突。當你使用 *時,我們不知道導入哪些對象以及它們的名字。
如何處理這個問題?導入你打算使用的特定對象
1.# Using import *
python學習交流Q群:906715085###
3.from math import *
5.print(floor(2.4))
7.print(ceil(2.4))
9.print(pi)
11.# Good
13.import math
15.from math import pi
17.print(math.floor(2.4))
19.print(math.ceil(2.4))
21.print(pi)
我已經忽略這個問題很長時間了~
在Pycharm中寫python時候,總是提示我錯誤,嗯,你懂的,就是那些丑陋的下劃線。我不應該使用 裸except。PEP 8指南中並
不推薦 裸except。
裸except的問題是它會捕捉SystemExit和KeyboardInterrupt異常,從而不能使用Control-C來中斷程序。
下次你使用try/except時,在 except子句中會報錯。
1.# Try - except
3.# 錯誤寫法
5.try:
7.driver.find_element(...)
9.except:
11.print("Which exception?")
13.# 提倡寫法
15.try:
17.driver.find_element(...)
19.except NoSuchElementException:
21.print("It's giving NoSuchElementException")
23.except ElementClickInterceptedException:
25.print("It's giving ElementClickInterceptedException")
提倡我們主動使用已經成熟包,這樣寫可以使Python更簡潔、更有效率。
其中最應該用於數學計算的包是Numpy。Numpy可以幫助你比 for循環更快地解決數學運算。
假設我們有一個 random_scores數組,我們想得到沒有通過考試的人的平均分數(分數<60)。讓我們嘗試用 for循環來解決這個問題。
1.import numpy as np
3.random_scores = np.random.randint(1, 100, size=10000001)
5.# bad (solving problem with a for loop)
7.count_failed = 0
9.sum_failed = 0
11.for score in random_scores:
13. if score < 70:
15. sum_failed += score
17. count_failed += 1
19.print(sum_failed/count_failed)
現在讓我們用Numpy來解決這個問題。
1.# Good (solving problem using vector operations)
3.mean_failed = (random_scores[random_scores < 70]).mean()
5.print(mean_failed)
如果你同時運行兩者,你會發現Numpy更快。為什麼呢?因為Numpy將我們的操作向量化了。
大家都知道的好做法是,我們用Python打開的每個文件都必須關閉。
這就是為什麼我們每次處理文件時都要使用 open, write/read, close。這很好,但是如果 write/read方法拋出一個異常,文件就不會被關閉。
為了避免這個問題,我們必須使用 with語句。這樣,即使有異常,也會關閉該文件。
1.# Bad
3.f = open('dataset.txt', 'w')
5.f.write('new_data')
7.f.close()
9.# Good
11.with open('dataset.txt', 'w') as f:
13.f.write('new_data')
PEP8是一份每個學習Python的人都應該閱讀的文件。它提供了關於如何編寫Python代碼的指南和最佳實踐(本文中的一些建議來
自PEP8)
對於那些剛接觸Python的人來說,這個准則可能會讓他們感到擔心,不過大可不必擔心,一些PEP8規則被納入IDE中(我就是這
樣知道 裸except規則的)。
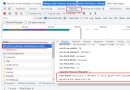
假設你在使用Pycharm。如果你寫的代碼沒有遵循PEP8的准則,你會看到下面圖片中那些難看的下劃線。
如果你把鼠標懸停在下劃線上,你會看到關於如何修復它們的提示。
在我的例子中,我只需要在 ,和 :後面添加一個空格。
1.# Good
3.my_list = [1, 2, 3, 4, 5]
5.my_dict = {
'key1': 'value1', 'key2': 'value2'}
7.my_name = "Frank"
我還把我的變量 x的名字改為 my_name。這不是Pycharm建議的,但PEP8建議使用容易理解的變量名。
我想大多數人都知道在使用字典時, .keys和 .values方法的作用。
如果你不知道的話,讓我們來看看。
1.dict_countries = {
'USA': 329.5, 'UK': 67.2, 'Canada':
2.>>>dict_countries.keys()
3.dict_keys(['USA', 'UK', 'Canada'])
4.>>>dict_countries.values()
5.dict_values([329.5, 67.2, 38])
這裡的問題,我們沒有理解並正確使用它們。
假設我們想循環浏覽 dictionary 並獲得 keys。你可能會使用 .keys 方法,但是你知道你可以通過在字典中循環獲得鍵嗎?在這種
情況下,使用 .keys 將是不必要的。
1.# Not using .keys() properly
3.# Bad
5.for key in dict_countries.keys():
7. print(key)
9.# Good
11.for key in dict_countries:
13. print(key)
另外,我們可能會想出一些變通的辦法來獲得字典的值,但這可以用 .items()方法輕松獲得。
1.# Not using .items()
3.# Bad
5.for key in dict_countries:
7. print(dict_countries[key])
9.# Good
11.for key, value in dict_countries.items():
13. print(key)
15. print(value)
當你想在一個已經定義好的序列的基礎上創建一個新的序列(列表、字典等)時,comprehension提供了一個更短的語法。
比如說我們想把我們的 countries列表中的所有元素都小寫。
雖然你可以用一個 for循環來做這件事,但你可以用一個列表理解來簡化事情。
理解是非常有用的,但是不要過度使用它們! 記住 Python 的禅宗。“簡單比復雜好”。
1.# Bad
3.countries = ['USA', 'UK', 'Canada']
5.lower_case = []
7.for country in countries:
9. lower_case.append(country.lower())
11.# Good (but don't overuse it!)
13.lower_case = [country.lower() for country in countries]
我們作為初學者最先學習的函數之一是 range和 len,所以難怪大多數人在循環浏覽列表時都有寫 range(len())的壞習慣。
假設我們有一個 countries, populations列表。如果我們想同時遍歷兩個列表,你可能會使用 range(len())。
1.# Using range(len())
3.countries = ['USA', 'UK', 'Canada']
5.populations = [329.5, 67.2, 38]
7.# Bad
9.for i in range(len(countries)):
11. country = countries[i]
13. population = populations[i]
15. print(f'{
country} has a population of {
population} million people')
雖然這可以完成工作, 但你可以使用 enumerate來簡化事情 (或者更好的是, 使用 zip函數來配對兩個列表中的元素)
1.# OK
3.for i, country in enumerate(countries):
5. population = populations[i]
7. print(f'{
country} has a population of {
population} million people')
9.# Much Better
11.for country, population in zip(countries, populations):
13. print(f'{
country} has a population of {
population} million people')
我們在Python中最先學會的東西之一可能是如何用 +運算符連接字符串。
這是在 Python 中連接字符串的一種有用但低效的方法。此外,它也不是那麼好看–你需要連接的字符串越多,你使用的+就越多。
你可以使用 f-string來代替這個運算符。
1.# Formatting with + operator
3.# Bad
5.name = input("Introduce Name: ")
7.print("Good Morning, " + name + "!")
9.# Good
11.name = input("Introduce Name: ")
13.print(f'Good Morning, {
name}')
string最大的特點是,它不僅對連接有用,而且有不同的應用。
如果你把一個可變的值(如list)作為一個函數的默認參數,你會看到一些意想不到的結果。
1.# Bad
2.def my_function(i, my_list=[]):
3. my_list.append(i)
4. return my_list
5.>>> my_function(1)
6.[1]
7.>>> my_function(2)
8.[1, 2]
9.>>> my_function(3)
10.[1, 2, 3]
在上面的代碼中,每次我們調用 my_function函數時,列表my_list都會不斷保存之前調用的值(很可能我們想在每次調用函數時
啟動一個空列表)
為了避免這種行為,我們應該將這個 my_list參數設置為None,並加入下面的if子句。
1.# Good
2.def my_function(i, my_list=None):
3. if my_list is None:
4. my_list = []
5. my_list.append(i)
6. return my_list
7.>>> my_function(1)
8.[1]
9.>>> my_function(2)
10.[2]
11.>>> my_function(3)
12.[3]
最後
今天的這篇文章到這裡就結束了,喜歡的記得點贊收藏,更多的問題可以評論留言,看就就會回復的喲!!!