A crawler is simply a name for the process of using programs to obtain data on the network .
If you want to get data on the network , We're going to give the crawler a web address ( It is usually called URL), The crawler sends a HTTP Request to the server of the target web page , The server returns data to the client ( That is, our reptiles ), The crawler then parses the data 、 Save, etc .
Reptiles can save us time , For example, I want to get the Douban movie Top250 The list , If you don't use reptiles , We need to input the name of Douban movie in the browser first URL , client ( browser ) Search the server of Douban movie web page through parsing IP Address , Then connect to it , The browser creates another HTTP The request is sent to the server of Douban movie , After the server receives the request , hold Top250 The list is presented from the database , Encapsulate into a HTTP Respond to , Then return the response result to the browser , The browser displays the response content , We see data . Our reptiles also follow this process , Just changed to code form .
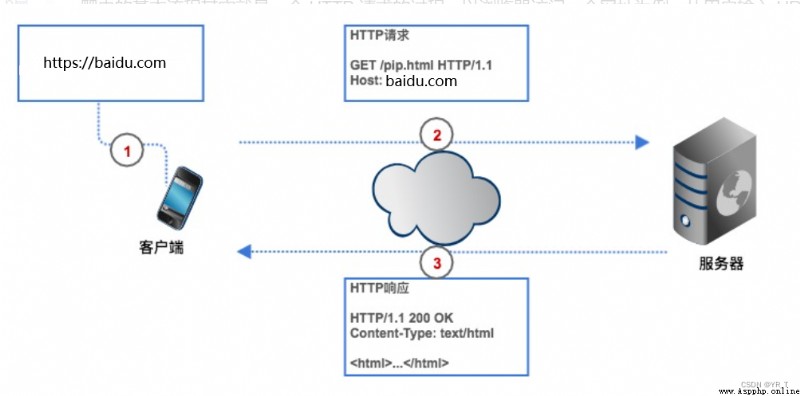
HTTP The request is made by the request line 、 Request header 、 Blank line 、 The request body consists of .
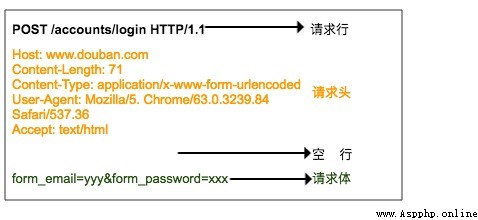
The request line consists of three parts :
1. Request method , Common request methods are GET、POST、PUT、DELETE、HEAD
2. The resource path that the client wants to get
3. It's used by the client HTTP Agreement version No
The request header is the supplementary description of the request sent by the client to the server , For example, explain the identity of the visitor , I'll talk about .
The request body is the data submitted by the client to the server , For example, the user needs to improve the account and password information when logging in . The request header is separated from the request body by a blank line . Not all requests have a request body , For example, general GET Will not have a request body .
The above figure is sent to the server when the browser logs in Douban HTTP POST request , The user name and password are specified in the request body .
HTTP The response format is very similar to the request format , Also by the response line 、 Response head 、 Blank line 、 The response body consists of .
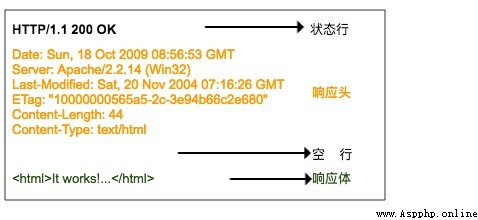
The response line also contains three parts , They are on the server side HTTP Version number 、 Response status code and status description .
There is a table of status codes here , Corresponding to the meaning of each status code



The second part is the response header , The response header corresponds to the request header , Here are some additional instructions for the response from the server , For example, what is the format of the response content , What is the length of the response content 、 When is it returned to the client 、 There are even some Cookie The information will also be placed in the response header .
The third part is the responder , It is the real response data , These data are actually web pages HTML Source code .
Reptiles can use many languages, such as Python、C++ wait , But I think Python It's the simplest ,
because Python Ready to use libraries , Has been encapsulated to almost perfect ,
C++ Although there are ready-made Libraries , But its reptiles are still relatively small , The only library is not enough to be simple , And the code is on various compilers , Even the compatibility of different versions of the same compiler is not strong , So it is not particularly easy to use . So today we mainly introduce python Reptiles .
cmd function :pip install requests , install requests.
And then in IDLE Or the compiler ( Personal recommendations VS Code perhaps Pycharm ) On the input
import requests function , If no error is reported , Proof of successful installation .
The way to install most libraries is :pip install xxx( The name of the library )
requests.head()
obtain HTML Web page header information method , Corresponding to HTTP Of HEAD
requests.post() towards HTML Web submission POST Requested method , Corresponding to HTTP Of POSTrequests.put() towards HTML Web submission PUT Requested method , Corresponding to HTTP Of PUTrequests.patch( ) towards HTML Submit local modification request for web page , Corresponding to HTTP Of PATCTrequests.delete() towards HTML Page submit delete request , Corresponding to HTTP Of DELETEr = requests.get(url)
It includes two important objects :
Construct a... That requests resources from the server Request object ; Returns a... That contains server resources Response object
r.status_code HTTP The return status of the request ,200 Indicates successful connection ,404 It means failure r.textHTTP String form of response content , namely ,url Corresponding page content r.encoding from HTTP header Guess the response content encoding method in ( If header Does not exist in the charset, The code is ISO-8859-1)r.apparent_encoding The response content encoding method analyzed from the content ( Alternative encoding )r.contentHTTP Binary form of response content requests.ConnectionError Network connection error exception , Such as DNS The query fails 、 Refuse to connect, etc requests.HTTPErrorHTTP Error exception requests.URLRequiredURL Missing abnormality requests.TooManyRedirects Exceeded the maximum number of redirections , Generate redirection exception requests.ConnectTimeout Connection to remote server timeout exception requests.Timeout request URL Overtime , Generate timeout exceptionrequests It is the most basic crawler library , But we can do a simple translation
I first put the project structure of a small crawler project I have done on , The complete source code can be downloaded through private chat .
The following is the source code of the translation part
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input(" Please enter the word to be translated ( in / Britain ):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# send out post request
ch = resp.json() # The content returned by the server is directly processed into json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print(" word :"+ch['data'][i]['k']+" "+" Word meaning :"+ch['data'][i]['v'])Code details :
Import requests modular , Set up url Translate the website for Baidu .
And then through post Method to send a request , Then type the returned result into a dic ( Dictionaries ), But at this time, we printed it out and found that it was like this .

This is what a dictionary looks like with a list in it , That's about it
{ xx:xx , xx:[ {xx:xx} , {xx:xx} , {xx:xx} , {xx:xx} ] }
What I marked red is the information we need .
Let's say I have a list in blue n A dictionary , We can go through len() Function to obtain n The numerical ,
And use for Loop traversal , Get the results .
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print(" word :"+ch['data'][i]['k']+" "+" Word meaning :"+ch['data'][i]['v'])Okay , Today's sharing is here , Bye-bye ~
Ah ? Forget one thing , I'll give you a code to crawl the weather !
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
Store weather conditions
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
Date of storage
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
Storage temperature : Maximum and minimum temperatures
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
Store wind
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print(" The temperature today is :"+tem[i]+'\t')
print(" wind :"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print(" The highest temperature :"+tem[i][0]+'\t')
print(" Minimum temperature :"+tem[i][1] + '\t')
print(" wind :"+wind[i]+'\t')
print('\n')
Okay , This is really good-bye , See you tomorrow ~