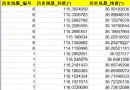
import pandas as pddata=pd.read_table('D:/機器學習課程設計/noteData.txt',sep='\t',header=None,nrows = 10000,names=["標簽","短信內容"])data.head()import jiebajieba.setLogLevel(jieba.logging.INFO)data['分詞後數據']=data["短信內容"].apply(lambda x:' '.join(jieba.cut(x)))data.head()X = data['分詞後數據']y = data['標簽']f = open('D:/機器學習課程設計/my_stop_words.txt','r')my_stop_words_data = f.readlines()f.close()my_stop_words_list=[]for each in my_stop_words_data: my_stop_words_list.append(each.strip('\n')) X = data['分詞後數據'] y = data['標簽']from sklearn.model_selection import StratifiedKFoldfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import Pipelineskf = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)for train_index, test_index in skf.split(X, y): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] pipeline = Pipeline([ ('vect', TfidfVectorizer(stop_words=my_stop_words_list)), ('clf', MultinomialNB(alpha=1.0))]) pipeline.fit(X_train, y_train) # 進行預測 predict = pipeline.predict(X_test) score = pipeline.score(X_test, y_test) print(score)data["數據類型"] = pipeline.predict(X) #lambda x:x+1 if not 2==1 else 0data['數據類型']=data["數據類型"].apply(lambda x:"垃圾短信" if x==1 else "正常短信")data.head()

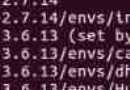
可以幫我看一下這段代碼嗎 總是出現這樣的報錯 有什麼辦法可以解決嗎?