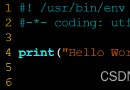
import pandas as pddata=pd.read_table('D:/ Machine learning course design /noteData.txt',sep='\t',header=None,nrows = 10000,names=[" label "," Content of short message "])data.head()import jiebajieba.setLogLevel(jieba.logging.INFO)data[' Data after word segmentation ']=data[" Content of short message "].apply(lambda x:' '.join(jieba.cut(x)))data.head()X = data[' Data after word segmentation ']y = data[' label ']f = open('D:/ Machine learning course design /my_stop_words.txt','r')my_stop_words_data = f.readlines()f.close()my_stop_words_list=[]for each in my_stop_words_data: my_stop_words_list.append(each.strip('\n')) X = data[' Data after word segmentation '] y = data[' label ']from sklearn.model_selection import StratifiedKFoldfrom sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import Pipelineskf = StratifiedKFold(n_splits=10, random_state=1, shuffle=True)for train_index, test_index in skf.split(X, y): X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] pipeline = Pipeline([ ('vect', TfidfVectorizer(stop_words=my_stop_words_list)), ('clf', MultinomialNB(alpha=1.0))]) pipeline.fit(X_train, y_train) # To make predictions predict = pipeline.predict(X_test) score = pipeline.score(X_test, y_test) print(score)data[" data type "] = pipeline.predict(X) #lambda x:x+1 if not 2==1 else 0data[' data type ']=data[" data type "].apply(lambda x:" Spam messages " if x==1 else " Normal SMS ")data.head()

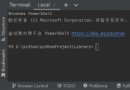
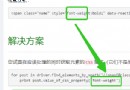
Can you help me look at this code There are always such errors Is there any way to solve it ?