Catalog
1.import and from … import Module variables 、 Method reference difference
2.python It appears that ' 'int' object is not callable' Error of
3.seaborn.heatmap( Parameter Introduction )
4. pd.date_range()
5.pd.Series()
6.ARIMA Modeling steps
7.python in with usage
8.Python In bag __init__.py effect
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --user tensorflow==1.15
How to install each package , The above image is from Tsinghua University , --user If you don't add it, you will sometimes report an error
This is python Xiaobai recorded , I started to learn this , If the great God has any doubt , Please criticize and correct me
from pandas import DataFrame from…import // Just use the function name directly
import pandas as pd import // modular . function
a.import…as
import: Import a module ; notes : Equivalent to importing a folder , It's a relative path
import A as B: Give tool library A A simple nickname B , Can help memory . example :import torch.nn as nn;import torch as t
b.from…import
from…import: Imported a function in a module ; notes : Equivalent to importing files in a folder , It's an absolute path .
example : Such as from A import b, amount to
import A
b = A.b
import // modular . function , The import module , Every time you use a function in a module, you must decide which module it is .
from…import // Just use the function name directly
from…import* // Is to import all functions in a module ; notes : amount to : It is equivalent to importing all files in a folder , All functions are absolute paths .
Example :
modular support.py:
def print_func( par ):
print "Hello : ", par
return# The import module
import support
# Now you can call the functions contained in the module
support.print_func("Runoob")
Can't be used directly print_func() Implementation calls , The imported module name must be treated as an object , Call the method under the module object print_func, Only then can the call be realized
====================================================
# The import module
from support import *
# Now you can call the functions contained in the module
print_func("Runoob")
You can use it directly print_func() Implementation calls Generally speaking , Recommended import sentence , Avoid using from … import, Because it makes your program easier to read , You can also avoid name conflicts .
https://blog.csdn.net/yucicheung/article/details/79445350
=======================================================================
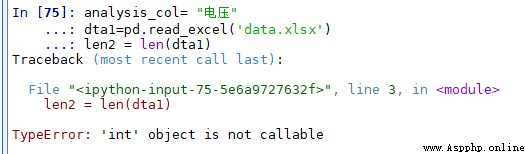
In use spyder Write python when , In a certain line len Prompt at function ’int’ object is not callable Error of .
reason Is in Variable explorer There is a named len The variable of , This len Variables are defined when running other scripts , After clearing this variable , The program can run normally .
So when you run the program later , It is necessary to cultivate the habit of Variable explorer Medium Variables are cleared before running The habit of .
=======================================================================
import seaborn as sns
fig, ax = plt.subplots(figsize=(9, 9))
sns.heatmap(pd.DataFrame(res),
annot=True, vmax=1, vmin=0, xticklabels=True, yticklabels=True, square=True, cmap="YlGnBu")
ax.set_title('test', fontsize=18)
plt.show()
import seaborn as sns
import numpy as np
data = np.array([[1,2,3],[4,5,6],[7,8,9]])
sns.heatmap(data,annot=True)seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)
It's better to use the simplest , In fact, it is also the core , there data Is the most complex parameter , The others are just for Decoration heat map Of , So what is this heat map for ,
Is to visualize the existing numbers , Got res = data.corr(method='spearman') It has a strong visual effect
What do the parameters mean
data: Is the core parameter , Rectangular dataset , Show theme map , Everything else is decoration :
annot: The default is False, by True Words , Numbers will be displayed on the grid
vmax, vmin: The maximum value of the color value of the thermal diagram , minimum value , The default from the data Derivation in
cmap:matplotlib Color bar name or object , Or a list of colors , Optional parameters . Mapping from data value to color space . If not provided , The default value will depend on whether “center” ,cmap="YlGnBu"
xticklabels, yticklabels:“auto”, Boolean value , Class list value , Or shape the value , Optional parameters . If it is True, Then draw dataframe Column name of . If it is False, Column names are not drawn , The default is True
Return value :ax:matplotlib Axes
Axis object of thermal diagram
square: Boolean value , Optional parameters . If True, Set the axis direction to “equal”, To make each cell square , The default is False
There are also many parameters to refer to in this article :https://blog.csdn.net/hongguihuang/article/details/105711115
Here's a bug, Sometimes the drawing is half a display , There is only half of the top and bottom , It is said to be the version used matplotlib Of bug
The solution is as follows :
ax = sns.heatmap(...);
# Just add this directly to the code
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)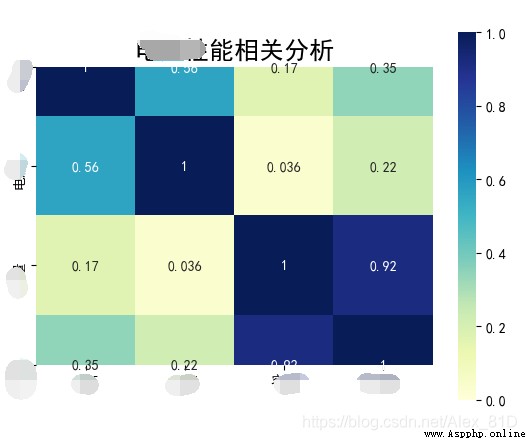

=======================================================================
pd.date_range('1900-1-1', freq="D", periods=len4)
grammar :pandas.date_range(start=None, end=None, periods=None, freq='D', tz=None, normalize=False, name=None, closed=None, **kwargs)
This function is mainly used to generate a fixed frequency time index , When calling the constructor , Must specify start、end、periods Two parameter values in , Otherwise, the report will be wrong .
Description of main parameters :
periods: Fixed period , The value is an integer or None
freq: Date offset , The value is string or DateOffset, The default is 'D' ( God )
normalize: If the parameter is True It means that you will start、end Parameter values are regularized to midnight timestamp
name: The name of the build time index object , The value is string or None
eg: a1 = pd.date_range('1900-1-1', freq="D", periods=10)
DatetimeIndex(['1900-01-01', '1900-01-02', '1900-01-03', '1900-01-04',
'1900-01-05', '1900-01-06', '1900-01-07', '1900-01-08',
'1900-01-09', '1900-01-10'],
dtype='datetime64[ns]', freq='D')
=======================================================================
series It's a one-dimensional array , Is based on NumPy Of ndarray structure .Pandas Will use it silently 0 To n-1 As a series Of index, But you can also specify index( You can put index Understood as a dict Inside key)
Series([data, index, dtype, name, copy, …])
pd.Series([list],index=[list])
import pandas as pd
index = ['a','b','c','f','e']
s=pd.Series([1,2,3,4,5],index)
print(s)a 1
b 2
c 3
f 4
e 5
dtype: int64
=======================================================================
When the error is white noise ,model Just ok 了 , It's predictable
=======================================================================
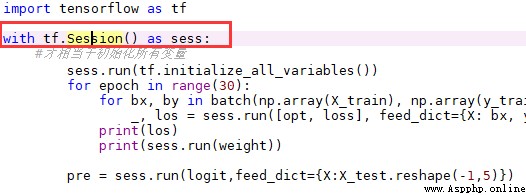
stay Python in , If an object has __enter__ and __exit__ Method , You can go to with Use it in statements .
with At the end of the block, the corresponding __exit__ The code in . therefore , We don't need to write the corresponding code to close, No matter what the reason is with.
with open(...) as f:
print(f.readall())Equivalent to ||
f = open(...)
print(f.readal())
f.close()If not used with, in consideration of f2 It may fail to open or follow-up operations may make errors , We can write like this :
f1 = open(...)
try:
f2 = open(...)
...
catch:
pass
else:
f2.close()
f1.close()It's not elegant to write like this , You have to catch exceptions yourself , Manually close flow 、session And so on .
meanwhile , We can also be in a with Statement contains multiple objects :
with open(...) as f1, open(...) as f2:
...
summary :
__init__.py The main function of :
1. Python in package The logo of , Can't delete
2. Definition __all__ Used to blur import
3. To write Python Code ( Not recommended in __init__ Write in python modular , You can create another module in the package to write , Try to make sure that __init__.py Simple )
https://blog.csdn.net/yucicheung/article/details/79445350
https://www.cnblogs.com/AlwinXu/p/5598543.html
loc function : By row index “Index” To get the row data based on the specific value in ( If you take "Index" by "A" The line of )
iloc function : Get line data by line number ( For example, take the data in the second row )
df.iloc["1", :] : All the data in the first row
df.loc['a'] : Index to 'a' The line of
from gensim import corpora
from collections import defaultdict
import jieba
from gensim.corpora import Dictionary
wordslist = [" I am in Yulong Snow Mountain "," I like Yulong Snow Mountain "," I have to go to Yulong Snow Mountain "]
# segment text by words
textTest = [[word for word in jieba.cut(words)] for words in wordslist]
# Generate Dictionary
dictionary = Dictionary(textTest,prune_at=2000000)
for key in dictionary.iterkeys():
print (key,dictionary.get(key),dictionary.dfs[key])
dictionary.filter_extremes(no_below=5, no_above=0.5, keep_n=1000)
for key in dictionary.iterkeys():
print (key,dictionary.get(key),dictionary.dfs[key])
The key API Explain
dictionary.filter_n_most_frequent(N)
Filter out the most frequent N Word
dictionary.filter_extremes(no_below=5, no_above=0.5, keep_n=100000)
1. The number of occurrences is less than no_below Of
2. The number of occurrences is higher than no_above Of . Note that this decimal refers to a percentage
3. stay 1 and 2 On the basis of , Keep the frequency before keep_n 's words
dictionary.filter_tokens(bad_ids=None, good_ids=None)
There are two uses , One is to remove bad_id The corresponding words , The other is to retain good_id The corresponding word and remove the other words . Note that there bad_ids and good_ids It's all in the form of a list
dictionary.compacity()
After performing the previous filtering operation , There may be a gap between the serial numbers of words , Then you can use this function to reorder the dictionary , Remove these gaps .
corpora.Dictionary object
It can be understood as python Dictionary objects in , Its Key It's a dictionary word , Its Val Is the only numeric type corresponding to a word ID
Construction method Dictionary(documents=None, prune_at=2000000)
prune_at Parameters Play the role of controlling the dimension of the vector
https://blog.csdn.net/qq_19707521/article/details/79174533
https://blog.csdn.net/kylin_learn/article/details/83047880
https://blog.csdn.net/xuxiuning/article/details/47720337
http://www.voidcn.com/article/p-mjlmvwmn-pq.html
vector_a = np.mat(emb)
vector_b = np.mat(tp_emb)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
sim = 0.5 + 0.5 * cos# Method 1 :
import numpy as np
def cos_sim(vector_a, vector_b):
"""
Calculate the cosine similarity between two vectors
:param vector_a: vector a
:param vector_b: vector b
:return: sim
"""
vector_a = np.mat(vector_a)
vector_b = np.mat(vector_b)
num = float(vector_a * vector_b.T)
denom = np.linalg.norm(vector_a) * np.linalg.norm(vector_b)
cos = num / denom
sim = 0.5 + 0.5 * cos
return sim# Method 2 :
def cosine_similarity(x, y, norm=False):
""" Calculate two vectors x and y Cosine similarity of """
# method 1
res = np.array([[x[i] * y[i], x[i] * x[i], y[i] * y[i]] for i in range(len(x))])
cos = sum(res[:, 0]) / (np.sqrt(sum(res[:, 1])) * np.sqrt(sum(res[:, 2])))
return 0.5 * cos + 0.5 if norm else cos # Normalize to [0, 1] Within the interval https://www.jianshu.com/p/0c33c17770a0
https://blog.csdn.net/hereiskxm/article/details/52526842
https://blog.csdn.net/zhuzuwei/article/details/80777623