我們在做數據分析的時候,難免會用到圖像來表示你要展示的東西,接下來寫一下demo來表示一下各種圖:
以下默認所有的操作都先導入了numpy、pandas、matplotlib、seaborn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns數據源地址:github地址:https://github.com/mwaskom/seaborn-data
解壓縮文件,拖入seaborn-data文件夾中
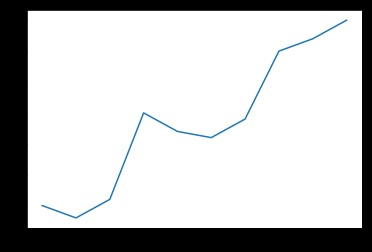
折線圖可以用來表示數據隨著時間變化的趨勢
x = [2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019]
y = [5, 3, 6, 20, 17, 16, 19, 30, 32, 35]
plt.plot(x, y)
plt.show()
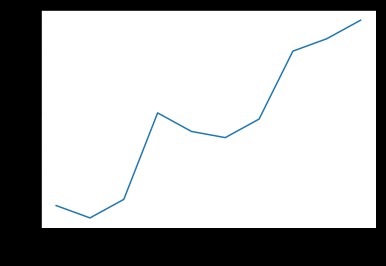
df = pd.DataFrame({'x': x, 'y': y})
sns.lineplot(x="x", y="y", data=df)
plt.show()
直方圖是比較常見的視圖,它是把橫坐標等分成了一定數量的小區間,然後在每個小區間內用矩形條(bars)展示該區間的數值
a = np.random.randn(100)
s = pd.Series(a)
plt.hist(s)
plt.show()
sns.distplot(s, kde=False)
plt.show()
sns.distplot(s, kde=True)
plt.show()
條形圖可以幫我們查看類別的特征。在條形圖中,長條形的長度表示類別的頻數,寬度表示類別。
x = ['Cat1', 'Cat2', 'Cat3', 'Cat4', 'Cat5']
y = [5, 4, 8, 12, 7]
plt.bar(x, y)
plt.show()
plt.show()
x = ['Cat1', 'Cat2', 'Cat3', 'Cat4', 'Cat5']
y = [5, 4, 8, 12, 7]
plt.barh(x, y)
plt.show()
nums = [25, 37, 33, 37, 6]
labels = ['High-school','Bachelor','Master','Ph.d', 'Others']
plt.pie(x = nums, labels=labels)
plt.show()
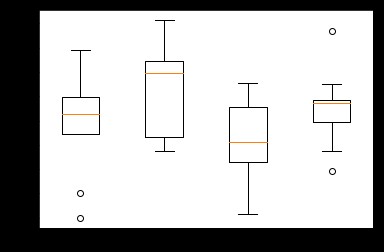
箱線圖由五個數值點組成:最大值 (max)、最小值 (min)、中位數 (median) 和上下四分位數 (Q3, Q1)。
可以幫我們分析出數據的差異性、離散程度和異常值等。
# 生成0-1之間的10*4維度數據
data=np.random.normal(size=(10,4))
lables = ['A','B','C','D']
# 用Matplotlib畫箱線圖
plt.boxplot(data,labels=lables)
plt.show()
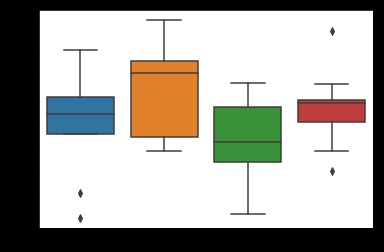
# 用Seaborn畫箱線圖
df = pd.DataFrame(data, columns=lables)
sns.boxplot(data=df)
plt.show()
熱力圖,英文叫 heat map,是一種矩陣表示方法,其中矩陣中的元素值用顏色來代表,不同的顏色代表不同大小的值。通過顏色就能直觀地知道某個位置上數值的大小。
data = np.array([[1,2,3],[4,5,6],[7,8,9]])
ax = sns.heatmap(data,annot=True)
bottom, top = ax.get_ylim()
ax.set_ylim(bottom + 0.5, top - 0.5)
plt.show()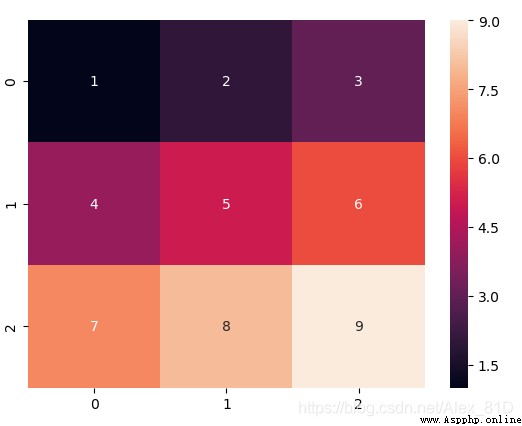
這個需要數據集,去git上下載即可,git地址:https://github.com/mwaskom/seaborn-data下載seaborn-data文件
flights = sns.load_dataset("flights")
data=flights.pivot('year','month','passengers')
sns.heatmap(data)
plt.show()
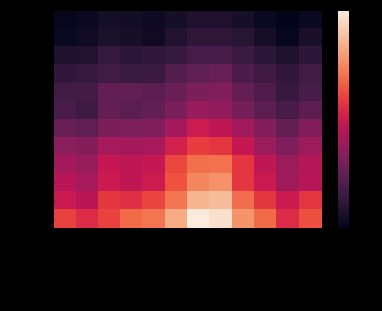
通過 seaborn 的 heatmap 函數,我們可以觀察到不同年份,不同月份的乘客數量變化情況,其中顏色越淺的代表乘客數量越多
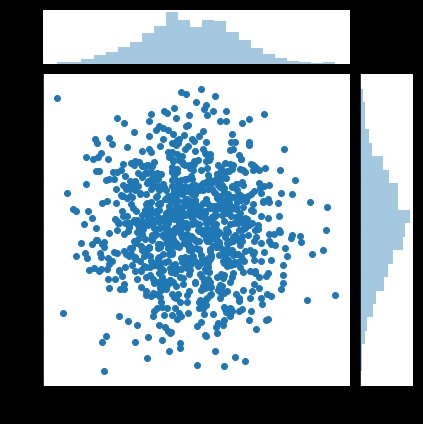
散點圖的英文叫做 scatter plot,它將兩個變量的值顯示在二維坐標中,非常適合展示兩個變量之間的關系。
N = 1000
x = np.random.randn(N)
y = np.random.randn(N)
plt.scatter(x, y,marker='x')
plt.show()

df = pd.DataFrame({'x': x, 'y': y})
sns.jointplot(x="x", y="y", data=df, kind='scatter');
plt.show()
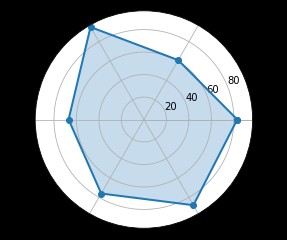
蜘蛛圖是一種顯示一對多關系的方法,使一個變量相對於另一個變量的顯著性是清晰可見
labels=np.array([u"推進","KDA",u"生存",u"團戰",u"發育",u"輸出"])
stats=[83, 61, 95, 67, 76, 88]
# 畫圖數據准備,角度、狀態值
angles=np.linspace(0, 2*np.pi, len(labels), endpoint=False)
stats=np.concatenate((stats,[stats[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 用Matplotlib畫蜘蛛圖
fig = plt.figure()
ax = fig.add_subplot(111, polar=True)
ax.plot(angles, stats, 'o-', linewidth=2)
ax.fill(angles, stats, alpha=0.25)
# 設置中文字體
# font = FontProperties(fname=r"/System/Library/Fonts/PingFang.ttc", size=14)
# ax.set_thetagrids(angles * 180/np.pi, labels, FontProperties=font)
ax.set_thetagrids(angles * 180/np.pi, labels, fontproperties="SimHei")
plt.show()
數據源地址:github地址:https://github.com/mwaskom/seaborn-data
解壓縮文件,拖入seaborn-data文件夾中
二元變量分布可以看兩個變量之間的關系
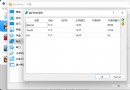
tips = sns.load_dataset("tips")
tips.head(10)
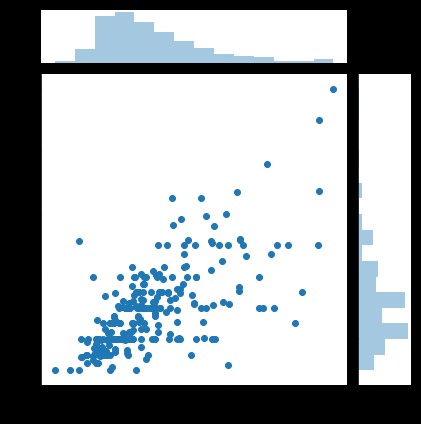
#散點圖
sns.jointplot(x="total_bill", y="tip", data=tips, kind='scatter')
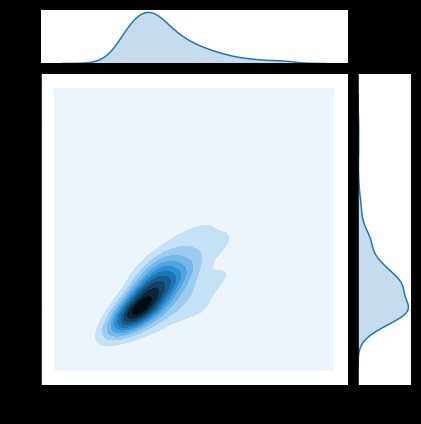
#核密度圖
sns.jointplot(x="total_bill", y="tip", data=tips, kind='kde')
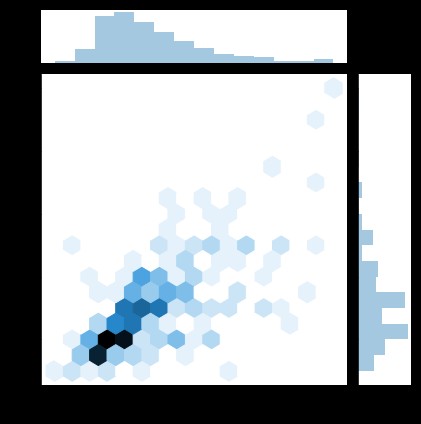
#Hexbin圖
sns.jointplot(x="total_bill", y="tip", data=tips, kind='hex')
plt.show()
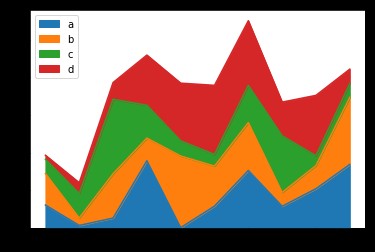
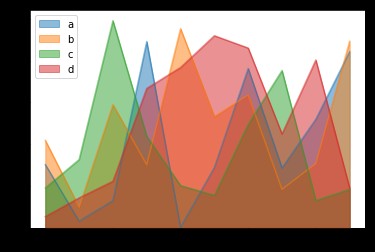
面積圖又稱區域圖,強調數量隨時間而變化的程度,也可用於引起人們對總值趨勢的注意。
堆積面積圖還可以顯示部分與整體的關系。折線圖和面積圖都可以用來幫助我們對趨勢進行分析,當數據集有合計關系或者你想要展示局部與整體關系的時候,使用面積圖為更好的選擇。
df = pd.DataFrame(
np.random.rand(10, 4),
columns=['a', 'b', 'c', 'd'])
# 堆面積圖
df.plot.area()
# 面積圖
df.plot.area(stacked=False)
六邊形圖將空間中的點聚合成六邊形,然後根據六邊形內部的值為這些六邊形上色。
df = pd.DataFrame(
np.random.randn(1000, 2),
columns=['a', 'b'])
df['b'] = df['b'] + np.arange(1000)
# 關鍵字參數gridsize;它控制x方向上的六邊形數量,默認為100,較大的gridsize意味著更多,更小的bin
df.plot.hexbin(x='a', y='b', gridsize=25)

本文參考如下文章改寫,感謝博主
https://www.cnblogs.com/chenqionghe/p/12254085.html