實驗數據集:全國工作情況數據集下載
import pandas as pd
import numpy as np
from pyecharts.charts import *
from pyecharts import options as opts
from pyecharts.commons.utils import JsCode
from pyecharts.globals import SymbolType
from pyecharts.components import Table
import textwrap
path = r'2022年數據分析崗招聘數據.csv'#修改文件存儲目錄
data = pd.read_csv(path)
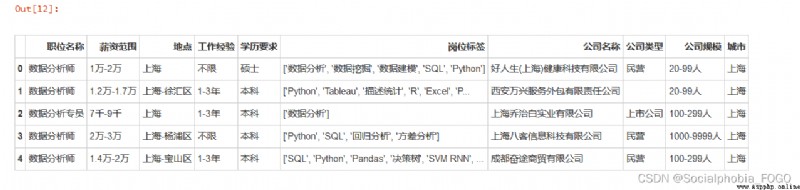
data.head()

# 城市數據處理
data['城市'] = data['地點'].apply(lambda x:x.split('-')[0])
data.head()
# 薪資數據處理
# 去除非范圍類數據
data2 = data[data['薪資范圍'] != '面議']
data2 = data2[~data2.薪資范圍.str.contains('/天')]
data2 = data2[~data2.薪資范圍.str.contains('以下')]
data2['薪資下限'] = data2.薪資范圍.apply(lambda x:x.split('-')[0])
data2['薪資上限'] = data2.薪資范圍.apply(lambda x:x.split('-')[1])
# 定義函數將薪資轉化為數字形式
def salary_handle(word):
if word[-1] == '萬':
num = float(word.strip('萬')) * 10000
elif word[-1] == '千':
num = float(word.strip('千')) * 1000
return num
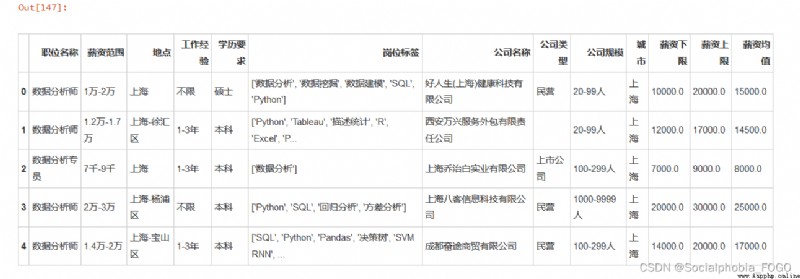
data2['薪資下限'] = data2.薪資下限.apply(lambda x:salary_handle(x))
data2['薪資上限'] = data2.薪資上限.apply(lambda x:salary_handle(x))
data2['薪資均值'] = round((data2.薪資上限 + data2.薪資下限)/2,2)
data2.head()
print('不規范數據量為:',data.shape[0] - data2.shape[0])
不規范數據量為: 330
# 去除異常值
data2 = data2.reset_index(drop = True)
# data2[data2['工作經驗']=='10年以上']
data2 = data2.drop(index = 5860)
在數據預處理部分,做了如下事情。
首先導入數據,查看數據基本情況。由於數據是自己爬的,所以每個字段的數據情況基本上都了解了,這部分就進行了省略。
然後處理城市數據。企業發布的招聘信息中,工作地點的信息大部分都精確到了具體的市區。因此這裡將工作地區中的城市提取出來,方便後續統計。
然後對數據中的薪資范圍進行處理。由於薪資范圍的數據是‘1萬-2萬’或者是‘7千-9千’或者是'面議'或者是‘200元/天’這樣的形式,因此要對薪資數據進行處理。查看薪資數據,發現大部分薪資的數據都是以‘7千-9千’這樣的范圍形式出現的,僅有少部分數據是‘面議’或者是‘200/天’這樣的形式,這樣不規范的數據總計330條,占比不是很大,因此將這部分數據直接進行去除。並且將范圍中的7千、1萬這樣形式的數據都轉換成具體的數值型數據,方便後續統計分析。並且去薪資的上限和下限的均值作為新字段進行分析。
我們首先來看看,哪個城市的數據分析崗的崗位需求最多呢?
繪制各城市崗位需求榜單如下。
# 繪制圓角柱狀圖函數
def echarts_bar(x,y,title = '主標題',subtitle = '副標題',label = '圖例'):
""" x: 函數傳入x軸標簽數據 y:函數傳入y軸數據 title:主標題 subtitle:副標題 label:圖例 """
bar = Bar(
init_opts=opts.InitOpts(
# bg_color='#080b30', # 設置背景顏色
theme='shine', # 設置主題
width='1000px', # 設置圖的寬度
height='700px' # 設置圖的高度
)
)
bar.add_xaxis(x)
bar.add_yaxis(label,y,
label_opts=opts.LabelOpts(is_show=True) # 是否顯示數據
,category_gap="50%" # 柱子寬度設置
)
bar.reversal_axis()
bar.set_series_opts( # 自定義圖表樣式
label_opts=opts.LabelOpts(
is_show=True,
position='right', # position 標簽的位置 可選 'top','left','right','bottom','inside','insideLeft','insideRight'
font_size=15,
color= '#333333',
font_weight = 'bolder', # font_weight 文字字體的粗細 'normal','bold','bolder','lighter'
font_style = 'oblique', # font_style 文字字體的風格,可選 'normal','italic','oblique'
), # 是否顯示數據標簽
itemstyle_opts={
"normal": {
"color": JsCode(
"""new echarts.graphic.LinearGradient(0, 0, 0, 1, [{ offset: 0,color: '#FC7D5D'} ,{offset: 1,color: '#C45739'}], false) """
), # 調整柱子顏色漸變
'shadowBlur': 6, # 光影大小
"barBorderRadius": [100, 100, 100, 100], # 調整柱子圓角弧度
"shadowColor": "#999999", # 調整陰影顏色
'shadowOffsetY': 2,
'shadowOffsetX': 2, # 偏移量
}
}
)
bar.set_global_opts(
# 標題設置
title_opts=opts.TitleOpts(
title=title, # 主標題
subtitle=subtitle, # 副標題
pos_left='center', # 標題展示位置
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20,font_weight='bolder')
),
# 圖例設置
legend_opts=opts.LegendOpts(
is_show=True, # 是否顯示圖例
pos_left='right', # 圖例顯示位置
pos_top='3%', #圖例距離頂部的距離
orient='horizontal' # 圖例水平布局
),
tooltip_opts=opts.TooltipOpts(
is_show=True, # 是否使用提示框
trigger='axis', # 觸發類型
trigger_on='mousemove|click', # 觸發條件,點擊或者懸停均可出發
axis_pointer_type='cross', # 指示器類型,鼠標移動到圖表區可以查看效果
),
yaxis_opts=opts.AxisOpts(
is_show=True,
splitline_opts=opts.SplitLineOpts(is_show=False), # 分割線
axistick_opts=opts.AxisTickOpts(is_show=False), # 刻度不顯示
axislabel_opts=opts.LabelOpts( # 坐標軸標簽配置
font_size=13, # 字體大小
font_weight='bolder' # 字重
),
), # 關閉Y軸顯示
xaxis_opts=opts.AxisOpts(
boundary_gap=True, # 兩邊不顯示間隔
axistick_opts=opts.AxisTickOpts(is_show=True), # 刻度不顯示
splitline_opts=opts.SplitLineOpts(is_show=False), # 分割線不顯示
axisline_opts=opts.AxisLineOpts(is_show=True), # 軸不顯示
axislabel_opts=opts.LabelOpts( # 坐標軸標簽配置
font_size=13, # 字體大小
font_weight='bolder' # 字重
),
),
)
return bar
job_demand = data2.城市.value_counts().sort_values(ascending = True)
echarts_bar(job_demand.index.tolist(),job_demand.values.tolist(),title = '全國各地數據分析崗崗位需求排名',subtitle = ' ',
label = '崗位需求量').render_notebook()
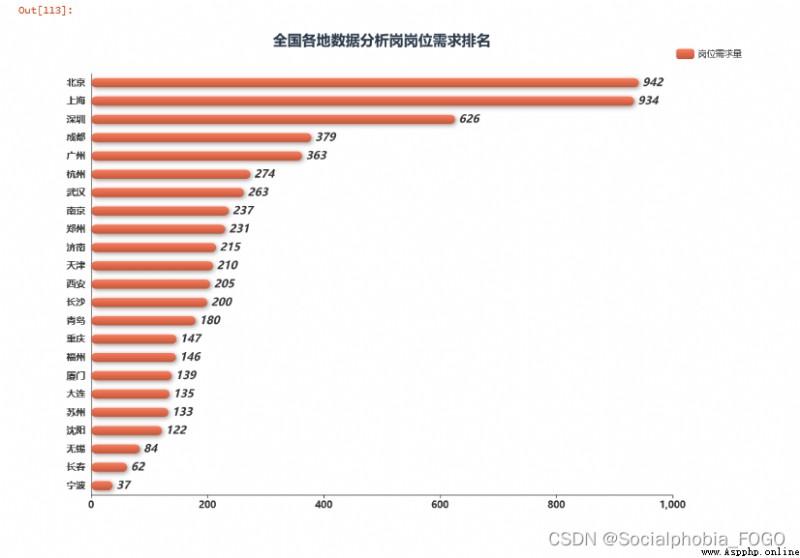 通過全國各地數據分析崗崗位需求排名可以發現,北京上海的崗位需求是最多的。其次是深圳。在北上廣深四個一線城市中,廣州的數據分析崗位需求是最少的。而成都的數據分析崗的崗位需求量近幾年增長較快,甚至超過了廣州。其次是杭州、武漢、南京等城市。
通過全國各地數據分析崗崗位需求排名可以發現,北京上海的崗位需求是最多的。其次是深圳。在北上廣深四個一線城市中,廣州的數據分析崗位需求是最少的。而成都的數據分析崗的崗位需求量近幾年增長較快,甚至超過了廣州。其次是杭州、武漢、南京等城市。
因此要找數據分析崗工作或者實習的小伙伴,還是推薦去北上廣深這樣的一線城市。
我們進一步查看北上廣深以及成都、杭州等數據分析崗崗位需求排名前9的城市,其數據分析崗崗位需求主要分別分布在哪些區。
# 北上廣深和成都杭州各個地區崗位需求量
beijing_demand = data[data['城市'] == '北京']['地點'].value_counts().sort_values(ascending = False)
shanghai_demand = data[data['城市'] == '上海']['地點'].value_counts().sort_values(ascending = False)
shenzhen_demand = data[data['城市'] == '深圳']['地點'].value_counts().sort_values(ascending = False)
guangzhou_demand = data[data['城市'] == '廣州']['地點'].value_counts().sort_values(ascending = False)
chengdu_demand = data[data['城市'] == '成都']['地點'].value_counts().sort_values(ascending = False)
hangzhou_demand = data[data['城市'] == '杭州']['地點'].value_counts().sort_values(ascending = False)
def bar_chart(desc, title_pos):
df_t = data[(data['城市'] == desc)&(data['地點'] != desc)]['地點'].value_counts().sort_values(ascending = False).reset_index()
df_t.columns = [desc,'崗位需求量']
df_t[desc] = df_t[desc].apply(lambda x:x.split('-')[1])
# 新建一個Bar
chart = Bar(
init_opts=opts.InitOpts(
# bg_color='#2C3B4C', # 設置背景顏色
theme='white', # 設置主題
width='400px', # 設置圖的寬度
height='400px'
)
)
chart.add_xaxis(
df_t[desc].tolist()
)
chart.add_yaxis(
'',
df_t['崗位需求量'].tolist()
)
chart.set_series_opts( # 自定義圖表樣式
label_opts=opts.LabelOpts(
is_show=True,
position='top', # position 標簽的位置 可選 'top','left','right','bottom','inside','insideLeft','insideRight'
font_size=15,
color= '#727F91',
font_weight = 'bolder', # font_weight 文字字體的粗細 'normal','bold','bolder','lighter'
font_style = 'oblique', # font_style 文字字體的風格,可選 'normal','italic','oblique'
), # 是否顯示數據標簽
itemstyle_opts={
"normal": {
'shadowBlur': 10, # 光影大小
"barBorderRadius": [100, 100, 0, 0], # 調整柱子圓角弧度
"shadowColor": "#94A4B4", # 調整陰影顏色
'shadowOffsetY': 6,
'shadowOffsetX': 6, # 偏移量
}
}
)
# Bar的全局配置項
chart.set_global_opts(
xaxis_opts=opts.AxisOpts(
name='地區',
is_scale=True,
axislabel_opts=opts.LabelOpts(rotate = 45),
# 網格線配置
splitline_opts=opts.SplitLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
yaxis_opts=opts.AxisOpts(
is_scale=True,
name='崗位需求量',
type_="value",
# 網格線配置
splitline_opts=opts.SplitLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
# 標題配置
title_opts=opts.TitleOpts(
title=desc,
pos_left=title_pos[0],
pos_top=title_pos[1],
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
),
tooltip_opts=opts.TooltipOpts(
is_show=True, # 是否使用提示框
trigger='axis', # 觸發類型
# is_show_content = True,
trigger_on='mousemove|click', # 觸發條件,點擊或者懸停均可出發
axis_pointer_type='cross', # 指示器類型,鼠標移動到圖表區可以查看效果
),
)
return chart
grid = Grid(
init_opts=opts.InitOpts(
theme='white',
width='1200px',
height='1200px',
)
)
# 依次添加不同屬性下價格對比Bar
grid.add(
bar_chart('北京', ['15%', '3%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%', # 指定Grid中子圖的位置
pos_bottom='70%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart('上海', ['50%', '3%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart('廣州', ['85%', '3%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='75%',
pos_right='0%'
)
)
grid.add(
bar_chart('深圳', ['15%', '33%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart('成都', ['50%', '33%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart('杭州', ['85%', '33%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='75%',
pos_right='0%'
)
)
grid.add(
bar_chart('武漢', ['15%', '63%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart('南京', ['50%', '63%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart('鄭州', ['85%', '63%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='75%',
pos_right='0%'
)
)
grid.render_notebook()

通過繪制柱狀圖可以發現,北京作為崗位需求最多的城市,其數據分析崗主要分布在朝陽區和海澱區,而其他區僅有這兩個區的不到三分之一的崗位需求。
上海數據分析崗崗位需求最多的區是浦東新區,其次是徐匯區,而徐匯區的崗位需求也不及浦東新區的一半。
廣州的數據分析崗崗位需求主要分布在天河區,海珠越秀黃埔也有一部分數據分析崗,但是最主要的還是再天河區。
深圳的數據分析崗崗位需求主要分布在南山區、福田區以及龍崗區。
…
下邊看大部分小伙伴都比較關心的問題,就是薪資水平。這裡的計算采用的都是企業發布的招聘的薪資范圍的均值。
city_salary = data2[['城市','薪資均值']].groupby('城市').mean().round(0).sort_values(by = '薪資均值',ascending = True).reset_index()
echarts_bar(city_salary['城市'].tolist(),city_salary['薪資均值'].tolist(),title = '全國各城市數據分析崗平均薪資水平排名',
subtitle = '',label = '平均薪資').render_notebook()
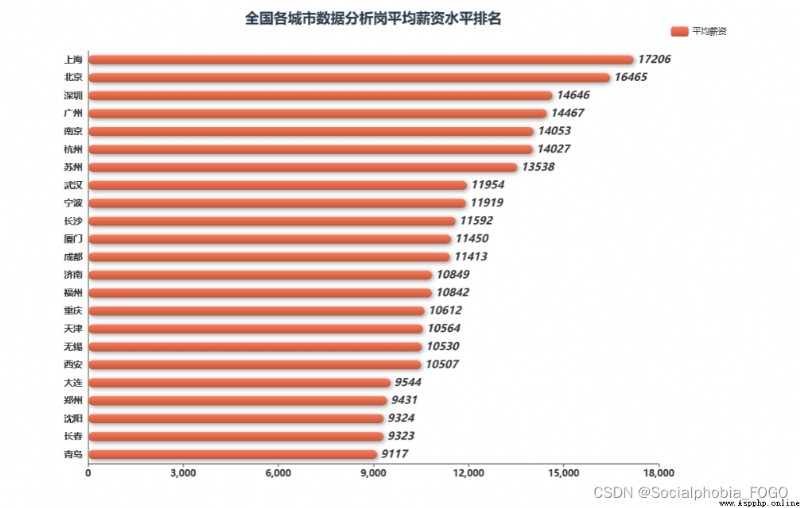
查看各個城市的薪資水平可以發現,北上廣深身為經濟最發達的四個一線城市,薪資水平也是最高的。數據分析崗薪資最高的城市是上海,而四個城市中薪資最低的城市是廣州。南京和蘇杭二州的薪資是緊隨其後的,值得一提的是,崗位需求量超過廣州的成都,薪資水平卻處於中等水平。
知道了哪個城市薪資水平較高以後,我們看看不同工作經驗和不同學歷的薪資水平分布是怎麼樣的吧
# 不同學歷、不同經驗、大專-不同經驗交叉分析、本科-不同經驗交叉分析、碩士-不同經驗交叉分析、學歷不限-不同經驗交叉分析
job_exp = data2[['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).sort_values(by = '薪資均值',ascending = False).reset_index()
job_edu = data2[['學歷要求','薪資均值']].groupby('學歷要求').mean().round(0).sort_values(by = '薪資均值',ascending = False).reset_index()
benke_exp = data2[data2['學歷要求'] == '本科'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
dazhuan_exp = data2[data2['學歷要求'] == '大專'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
shuoshi_exp = data2[data2['學歷要求'] == '碩士'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
buxian_exp = data2[data2['學歷要求'] == '學歷不限'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
boshi_exp = data2[data2['學歷要求'] == '博士'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
gaozhong_exp = data2[data2['學歷要求'] == '高中'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
zhongzhuan_exp = data2[data2['學歷要求'] == '中專/中技'][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).\
sort_values(by = '薪資均值',ascending = False).reset_index()
def bar_chart2(x,y,title_pos,title = '主標題',subtitle = '副標題'):
# 新建一個Bar
chart = Bar(
init_opts=opts.InitOpts(
# bg_color='#2C3B4C', # 設置背景顏色
theme='white', # 設置主題
width='400px', # 設置圖的寬度
height='400px'
)
)
chart.add_xaxis(
x
)
chart.add_yaxis(
'',
y
)
chart.set_series_opts( # 自定義圖表樣式
label_opts=opts.LabelOpts(
is_show=True,
position='top', # position 標簽的位置 可選 'top','left','right','bottom','inside','insideLeft','insideRight'
font_size=15,
color= '#727F91',
font_weight = 'bolder', # font_weight 文字字體的粗細 'normal','bold','bolder','lighter'
font_style = 'oblique', # font_style 文字字體的風格,可選 'normal','italic','oblique'
), # 是否顯示數據標簽
itemstyle_opts={
"normal": {
'shadowBlur': 10, # 光影大小
"barBorderRadius": [100, 100, 0, 0], # 調整柱子圓角弧度
"shadowColor": "#94A4B4", # 調整陰影顏色
'shadowOffsetY': 6,
'shadowOffsetX': 6, # 偏移量
}
}
)
# Bar的全局配置項
chart.set_global_opts(
xaxis_opts=opts.AxisOpts(
name=' ',
is_scale=True,
axislabel_opts=opts.LabelOpts(rotate = 45),
# 網格線配置
splitline_opts=opts.SplitLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
yaxis_opts=opts.AxisOpts(
is_scale=True,
name='薪資均值',
type_="value",
# 網格線配置
splitline_opts=opts.SplitLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
# 標題配置
title_opts=opts.TitleOpts(
title=title,
subtitle = subtitle,
pos_left=title_pos[0],
pos_top=title_pos[1],
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
),
tooltip_opts=opts.TooltipOpts(
is_show=True, # 是否使用提示框
trigger='axis', # 觸發類型
# is_show_content = True,
trigger_on='mousemove|click', # 觸發條件,點擊或者懸停均可出發
axis_pointer_type='cross', # 指示器類型,鼠標移動到圖表區可以查看效果
),
)
return chart
grid = Grid(
init_opts=opts.InitOpts(
theme='white',
width='1200px',
height='1200px',
)
)
# 依次添加不同屬性下價格對比Bar
grid.add(
bar_chart2(job_exp['工作經驗'].tolist(), job_exp['薪資均值'].tolist(), ['15%', '3%'], title='不同工作經驗薪資對比',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='10%', # 指定Grid中子圖的位置
pos_bottom='70%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart2(job_edu['學歷要求'].tolist(), job_edu['薪資均值'].tolist(), ['50%', '3%'], title='不同學歷要求薪資對比',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart2(buxian_exp['工作經驗'].tolist(), buxian_exp['薪資均值'].tolist(), ['85%', '3%'], title='學歷不限',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='75%',
pos_right='0%'
)
)
grid.add(
bar_chart2(dazhuan_exp['工作經驗'].tolist(), dazhuan_exp['薪資均值'].tolist(), ['15%', '33%'], title='大專',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart2(benke_exp['工作經驗'].tolist(), benke_exp['薪資均值'].tolist(), ['50%', '33%'], title='本科',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart2(shuoshi_exp['工作經驗'].tolist(), shuoshi_exp['薪資均值'].tolist(), ['85%', '33%'], title='碩士',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='75%',
pos_right='0%'
)
)
grid.add(
bar_chart2(boshi_exp['工作經驗'].tolist(), boshi_exp['薪資均值'].tolist(), ['15%', '63%'], title='博士',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart2(gaozhong_exp['工作經驗'].tolist(), gaozhong_exp['薪資均值'].tolist(), ['50%', '63%'], title='高中',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart2(zhongzhuan_exp['工作經驗'].tolist(), zhongzhuan_exp['薪資均值'].tolist(), ['85%', '63%'], title='中專/中技',
subtitle=' '),
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='75%',
pos_right='0%'
)
)
grid.render_notebook()
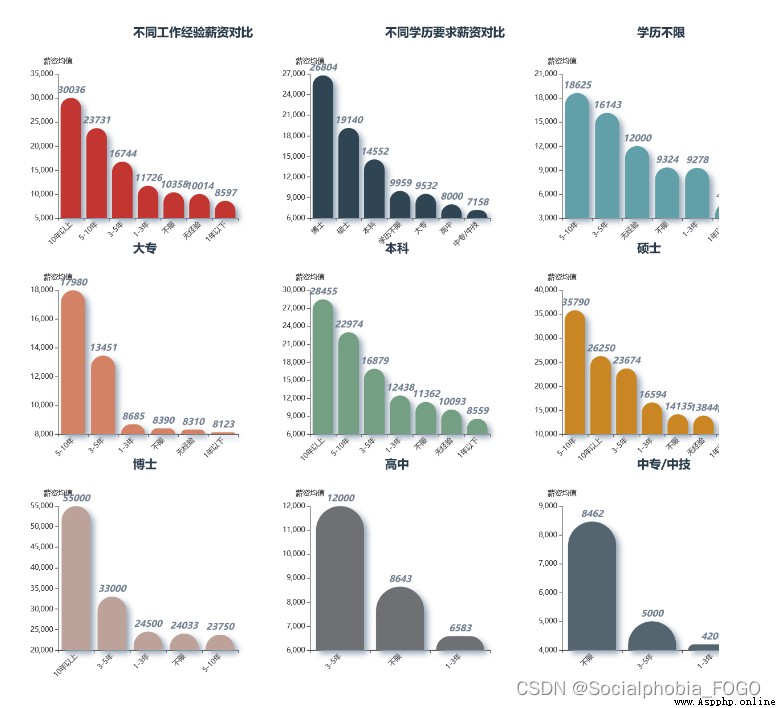
總的來看工作經驗、學歷和薪資的關系,可以發現,工作經驗和學歷越高,相應的薪資也越高,這是毋庸置疑的。
通過不同學歷背景下,不同的工作經驗與薪資的交叉分析,不難看出,學歷越高,相應的薪資的上升空間也是越高的。
def bar_chart(desc, title_pos):
df_t = data2[data2['城市'] == desc][['工作經驗','薪資均值']].groupby('工作經驗').mean().round(0).sort_values(by = '薪資均值',
ascending = False).reset_index()
# 新建一個Bar
chart = Bar(
init_opts=opts.InitOpts(
# bg_color='#2C3B4C', # 設置背景顏色
theme='white', # 設置主題
width='400px', # 設置圖的寬度
height='400px'
)
)
chart.add_xaxis(
df_t['工作經驗'].tolist()
)
chart.add_yaxis(
'',
df_t['薪資均值'].tolist()
)
chart.set_series_opts( # 自定義圖表樣式
label_opts=opts.LabelOpts(
is_show=True,
position='top', # position 標簽的位置 可選 'top','left','right','bottom','inside','insideLeft','insideRight'
font_size=15,
color= '#727F91',
font_weight = 'bolder', # font_weight 文字字體的粗細 'normal','bold','bolder','lighter'
font_style = 'oblique', # font_style 文字字體的風格,可選 'normal','italic','oblique'
), # 是否顯示數據標簽
itemstyle_opts={
"normal": {
'shadowBlur': 10, # 光影大小
"barBorderRadius": [100, 100, 0, 0], # 調整柱子圓角弧度
"shadowColor": "#94A4B4", # 調整陰影顏色
'shadowOffsetY': 6,
'shadowOffsetX': 6, # 偏移量
}
}
)
# Bar的全局配置項
chart.set_global_opts(
xaxis_opts=opts.AxisOpts(
name='工作經驗',
is_scale=True,
axislabel_opts=opts.LabelOpts(rotate = 45),
# 網格線配置
splitline_opts=opts.SplitLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
yaxis_opts=opts.AxisOpts(
is_scale=True,
name='薪資均值',
type_="value",
# 網格線配置
splitline_opts=opts.SplitLineOpts(
is_show=False,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
# 標題配置
title_opts=opts.TitleOpts(
title=desc,
pos_left=title_pos[0],
pos_top=title_pos[1],
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
),
tooltip_opts=opts.TooltipOpts(
is_show=True, # 是否使用提示框
trigger='axis', # 觸發類型
# is_show_content = True,
trigger_on='mousemove|click', # 觸發條件,點擊或者懸停均可出發
axis_pointer_type='cross', # 指示器類型,鼠標移動到圖表區可以查看效果
),
)
return chart
grid = Grid(
init_opts=opts.InitOpts(
theme='white',
width='1200px',
height='1200px',
)
)
# 依次添加不同屬性下價格對比Bar
grid.add(
bar_chart('北京', ['15%', '3%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%', # 指定Grid中子圖的位置
pos_bottom='70%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart('上海', ['50%', '3%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart('廣州', ['85%', '3%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='75%',
pos_right='0%'
)
)
grid.add(
bar_chart('深圳', ['15%', '33%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart('成都', ['50%', '33%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart('杭州', ['85%', '33%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='75%',
pos_right='0%'
)
)
grid.add(
bar_chart('武漢', ['15%', '63%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='5%',
pos_right='70%'
)
)
grid.add(
bar_chart('南京', ['50%', '63%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='40%',
pos_right='35%'
)
)
grid.add(
bar_chart('鄭州', ['85%', '63%']),
# is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='75%',
pos_right='0%'
)
)
grid.render_notebook()
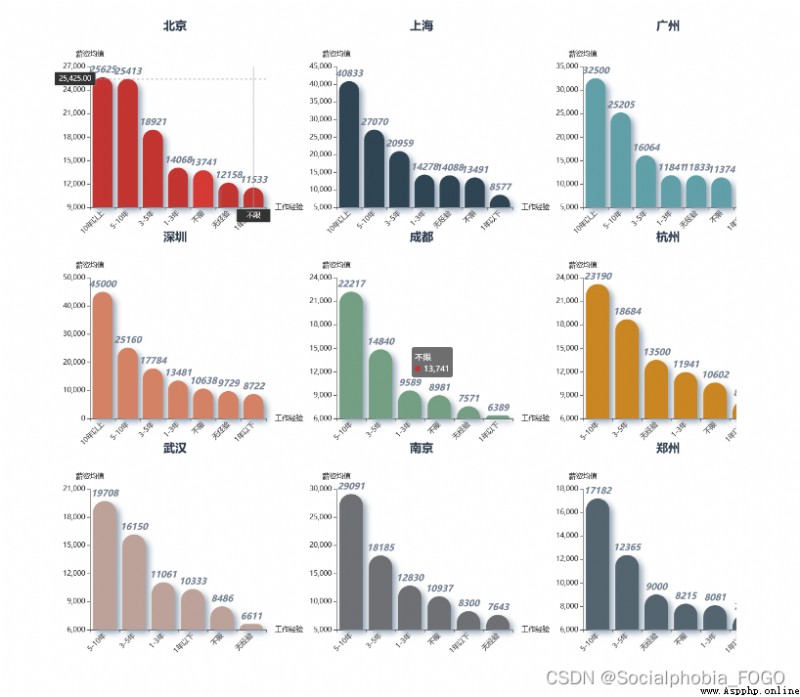
看各城市相應的薪資下限和上限,可以發現,北上廣深的下限和上限都是很高的,做數據分析去一線城市是沒毛病的~
了解了薪資以後,接下來我們看下數據分析崗有哪些崗位需求吧~
pie1 = data[['工作經驗','職位名稱']].groupby('工作經驗').count().sort_values(by = '職位名稱',ascending = False).reset_index()
pie2 = data[['學歷要求','職位名稱']].groupby('學歷要求').count().sort_values(by = '職位名稱',ascending = False).reset_index()
pie1 = (Pie()
.add('', [list(z) for z in zip(pie1['工作經驗'], pie1['職位名稱'])])
.set_global_opts(
title_opts=opts.TitleOpts(
title='工作經驗需求量',
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
)
)
)
pie2 = (Pie()
.add('', [list(z) for z in zip(pie2['學歷要求'], pie2['職位名稱'])])
.set_global_opts(
title_opts=opts.TitleOpts(
title='學歷需求量',
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
)
)
)
page = Page()
page.add(pie1,pie2)
page.render_notebook()
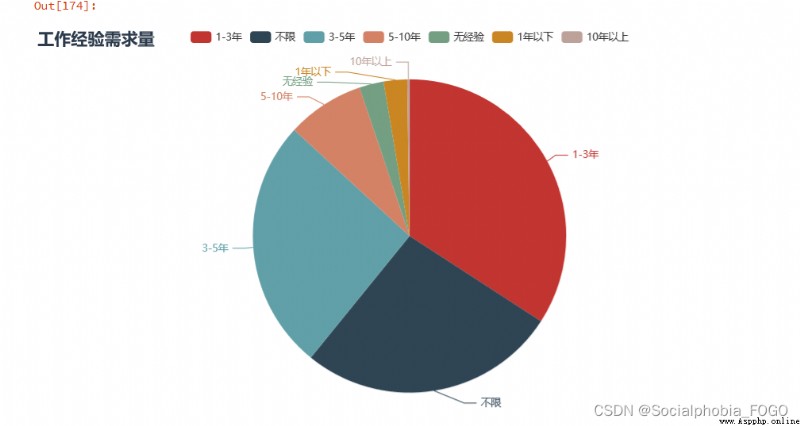
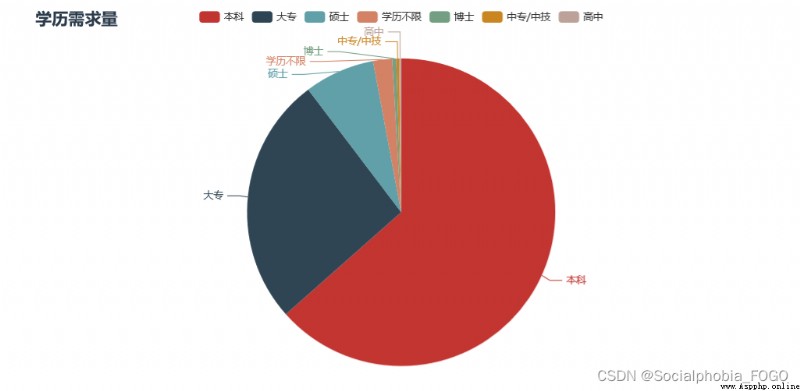
首先看工作經驗。數據分析崗在工作經驗的要求上邊,1-3年工作經驗是最多的,而不限工作經驗和3-5年工作經驗的需求也相對較多。
在學歷需求上邊,本科和大專占了絕大部分,僅有較少一部分是要求碩士和博士學歷的。因此數據分析崗對於學歷的要求並不是很高。
接下來我們看下數據分析崗要具備哪些技能吧~
這裡的數據是爬取自公司發布的職位信息中的職位標簽,而非崗位JD
tag_array = data['崗位標簽'].apply(lambda x:eval(x)).tolist()
tag_lis = []
for tag in tag_array:
tag_lis += tag
tag_df = pd.DataFrame(tag_lis,columns = ['職位標簽'])
tag_df_cnt = tag_df['職位標簽'].value_counts().reset_index()
tag_df_cnt.columns = ['職位標簽','計數']
word_cnt_lis = [tag for tag in zip(tag_df_cnt['職位標簽'],tag_df_cnt['計數'])]
wc = (
WordCloud()
.add("",
word_cnt_lis,
)
.set_global_opts(
title_opts=opts.TitleOpts(title="崗位標簽詞雲圖"),
)
)
wc.render_notebook()
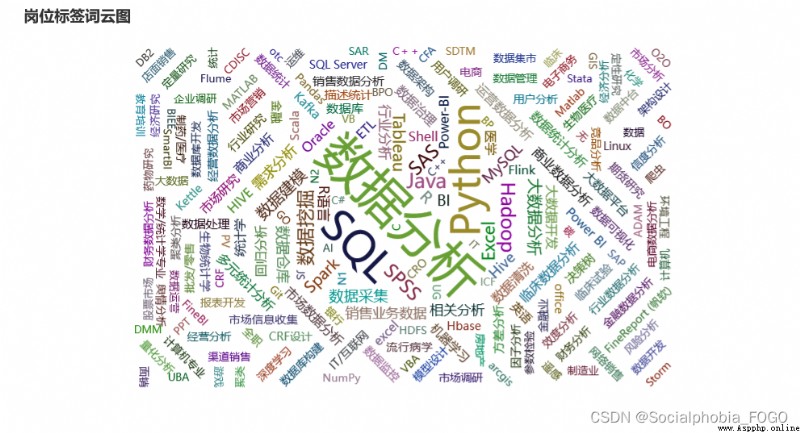
繪制詞雲圖我們可以發現,眾多的崗位標簽中,出現次數最頻繁的就是python和sql了,因此可以說明,sql和python是數據分析崗必備的技能,當然excel技能在日常工作中使用同樣很頻繁。
詞雲中數據挖掘、數據清洗、SPSS、BI工具等一些詞匯出現的也較多,具體的還要看各崗位的具體需求。
接下來我們看看招聘數據分析崗的企業中,主要都是哪些類型的企業,以及公司規模都是如何的。
company_type_cnt = data[['公司類型','公司規模']].groupby('公司類型').count().sort_values(by = '公司規模',ascending = False).reset_index()
# 刪除空值
company_type_cnt = company_type_cnt.drop(index = 10)
company_type_cnt.columns = ['公司類型','數量']
company_size_cnt = data[['公司類型','公司規模']].groupby('公司規模').count().sort_values(by = '公司類型',ascending = False).reset_index()
company_size_cnt.columns = ['公司規模','數量']
pie1 = (Pie()
.add('', [list(z) for z in zip(company_type_cnt['公司類型'], company_type_cnt['數量'])])
.set_global_opts(
title_opts=opts.TitleOpts(
title='各類型公司數據分析崗需求量',
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
)
)
)
pie2 = (Pie()
.add('', [list(z) for z in zip(company_size_cnt['公司規模'], company_size_cnt['數量'])])
.set_global_opts(
title_opts=opts.TitleOpts(
title='各規模公司數據分析崗需求量',
title_textstyle_opts=opts.TextStyleOpts(color='#2C3B4C', font_size=20)
)
)
)
page = Page()
page.add(pie1,pie2)
page.render_notebook()
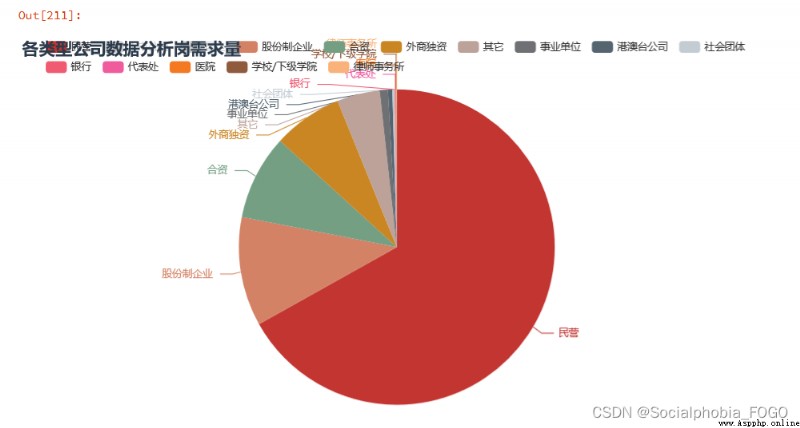
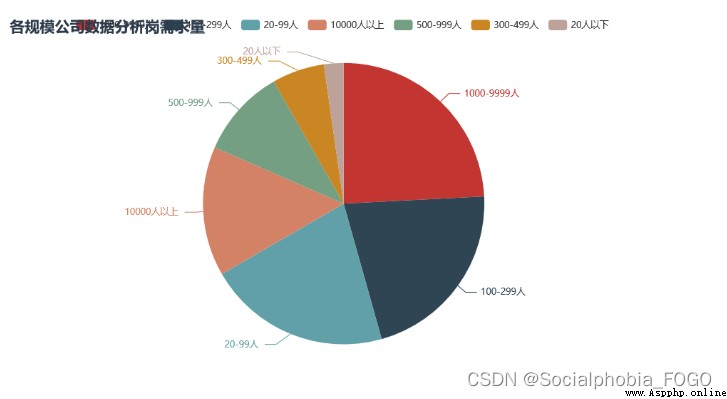
我們可以發現,招聘數據分析崗的企業中,以民營企業為主,占了一大半以上。
公司規模以1000-9999以及10000人以上的大型企業為主,大廠的數字化建設較為完善和成熟,因此會有較多的數據分析需求。同樣也有部分中小企業,有可能是一些外包企業等。
接下來,我們統計出薪資待遇top前50的企業,希望可以為各位小伙伴提供一些參考的依據~
company_rank = data2[['職位名稱','公司名稱','薪資均值','公司規模']].groupby(['公司名稱','公司規模','職位名稱']).mean().\
sort_values(by = ['薪資均值'],ascending = False).reset_index()
table = Table()
table_rows = [company_rank.iloc[i,:].tolist() for i in range(50)]
table.add(company_rank.columns.tolist(), table_rows)
table.render_notebook()