Complete the relevant contents according to the product introduction and user manual in the customized text .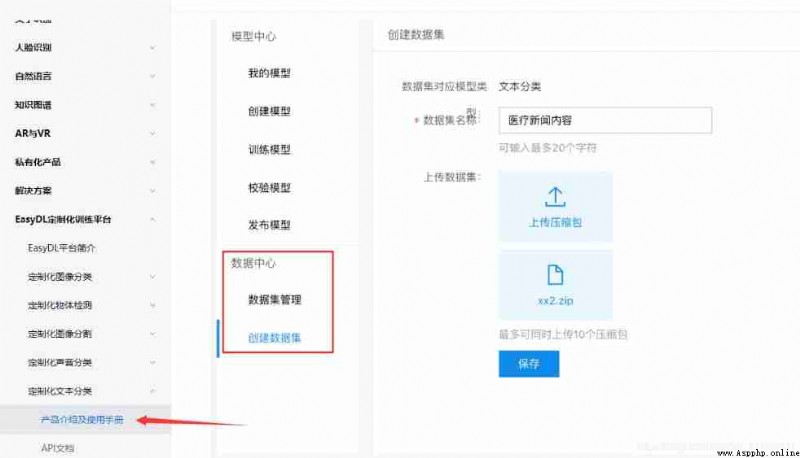
Pay attention to the point :
Be careful 1:txt The file must be utf-8 File format
a=' Old bathtub Basin Bad toilet Old sink shell Cosmetic brush earthen jar Haijin Peanut shell Chopping board brick toilet paper Basketball peach kernel glass Ceramic bowl one-off chopsticks Prune core Bad flowerpot Wooden comb Dirty clothes cigarette end Dregs Wet garbage bags tiles Broom '
b=' China Youth Daily client Chengdu 9 month 26 (Reuters) ( The intern Chen jing China youth daily · China Youth net reporter Wang Xinxin )9 month 26 The morning of 11 when , Under the organization of Sichuan Youth Federation ,30 A number of members of the Youth Federation and youth representatives from all walks of life carried out “ Bless Hong Kong · Praise the motherland ” Theme activities , Express the heart to heart connection between Mainland and Hong Kong Youth , Wish the founding of new China 70 Anniversary of the '
for i in range(100):
if(a[i]==' '):
c=a[i:(i+4)]+b[(i+6):(i+9)]+b[i:(i+6)]# Add a piece of text to generate more data
#c=a[i:(i+4)]
d=str(i)# The production of txt file name
f = open(d+'.txt','w',encoding='utf-8')# Format must be utf-8
f.write(c)
print(c)
Be careful 2: If the classification and naming of multiple uploaded compressed packages are consistent , The system will automatically merge data
Be careful 3: The classification should be named with numbers 、 Letter 、 Underline format , Chinese format naming is not supported at present , At the same time, be careful not to have spaces
Give my data set 
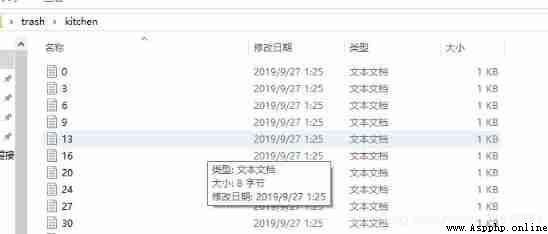

Finally packaged into zip Just upload
Basically follow the documentation , The document is very detailed
Select the previously uploaded dataset , Click training 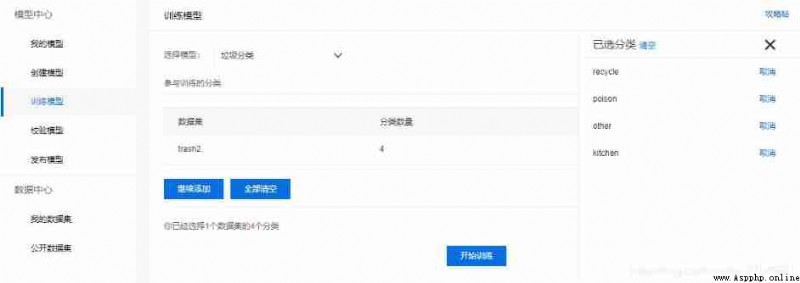
Training is usually fast , Less data 15 Just minutes
After training, the next step is model verification
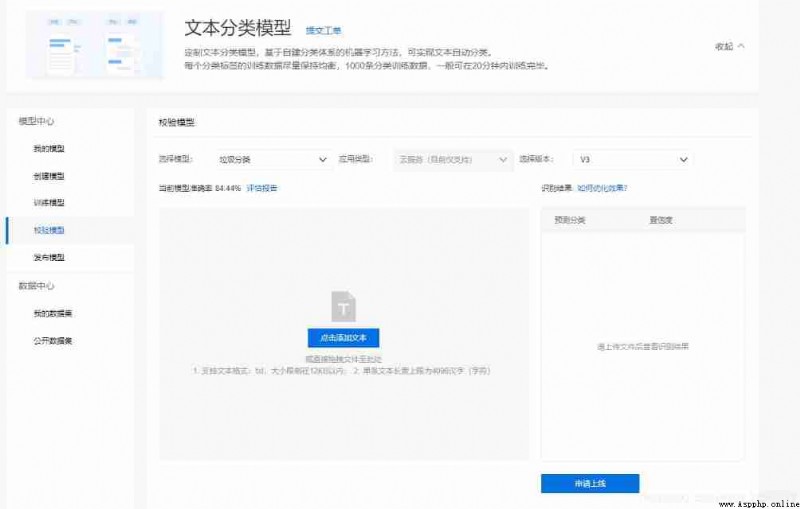
Every kind of 100 Pieces of data get a 84% The accuracy is fairly good .
In my model list —— Find the newly trained model version —— Click apply to publish
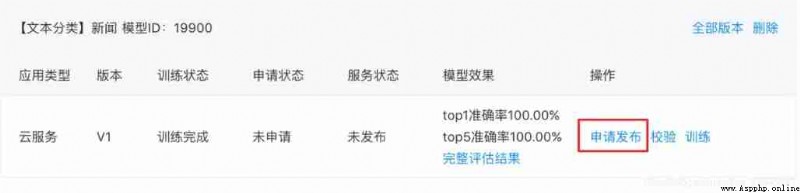
This usually takes about a day , Just be patient
Because of Baidu easydl in api Documents are mostly python2 Code for , And it's old
This is because the input text format is incorrect
#api In the code is
params = "{\"text\":\" watermelon \"}"
Should be changed to
params = {
"text": " watermelon ",
"top_num": 5
}
#python2 Code
# encoding:utf-8
import urllib2
'''
easydl Text classification
'''
request_url = "【 Address of the interface 】"
params = "{\"text\":\" watermelon \"}" ### Note that this is not the case , Look below python3 Code for
access_token = '[ Call the authentication interface to get token]'
request_url = request_url + "?access_token=" + access_token
request = urllib2.Request(url=request_url, data=params)
request.add_header('Content-Type', 'application/json')
response = urllib2.urlopen(request)
content = response.read()
if content:
print content
# This is for you python2 Code
Here's my python3 Code .
import urllib.request
import urllib, json, base64
request_url = ' Interface URL '
access_token =' Their own '
params={
"text": " A basin ",
"top_num": 2
} #******** That's right ********* It's been a long time
params = json.dumps(params).encode('utf-8')
print(params)
headers={'Content-Type':'application/json'}
request_url = request_url+"?access_token="+access_token
print('1',request_url)
mess=urllib.request.Request(url=request_url, headers=headers, data=params)
mess = urllib.request.urlopen(mess)
logInfo = mess.read().decode()
print(logInfo)
Output results
{"log_id":3173339169514822677,"results":[{"name":"other","score":0.4282606542110443},{"name":"recycle","score":0.2605192959308624}]}
Blog for the first time , I hope I can record more pits I have climbed in the future