In recent days, , The illustration in the primary school mathematics textbook published by the people's education press, which has been used for many years, has aroused controversy from people from all walks of life . Our programmers also do not have the ability to draw illustrations by hand , But we can turn video into animation with the help of a powerful in-depth learning model . The goal of this article is to make any with python Programmers with basic language skills , Achieve short video to animation effect . The example effect is as follows :

The whole implementation process is as follows :
- Read video frames
- Turn each frame of the image into an animation frame
- Convert the converted animation frame to video
The difficulty is how to turn the image into animation effect . Here we use the animation effect transformation model based on deep learning , Considering that many readers do not understand this , So I have prepared the source code and model , Just call it directly . If you don't want to read the details of the article, you can directly drag it to the end of the article , Access to the source code .
In order to make readers not care about the deep learning model , We have prepared the converted for the readers onnx Type model . Next, we introduce the operation in sequence onnx Model flow .
onnxruntime library pip install onnxruntime
If you want to use GPU Speed up , Can install GPU Version of onnxruntime:
pip install onnxruntime-gpu
It should be noted that :
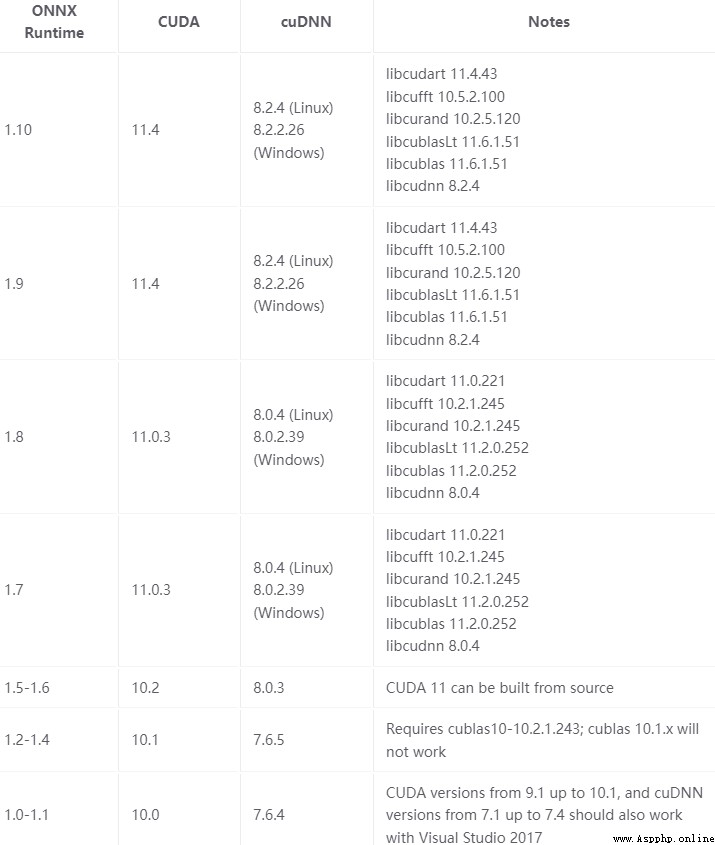
onnxruntime-gpuThe version ofCUDARelated , The specific correspondence is as follows :
Yes, of course , If you use CPU function , Then you don't need to think so much . In consideration of generality , This paper is based on CPU edition onnxruntime.
First import onnxruntime library , establish InferenceSession object , call run function . As shown below
import onnxruntime as rt
sess = rt.InferenceSession(MODEL_PATH)
inp_name = sess.get_inputs()[0].name
out = sess.run(None, {
inp_name: inp_image})
Specific to our animation effect , The implementation details are as follows :
import cv2
import numpy as np
import onnxruntime as rt
# MODEL = "models/anime_1.onnx"
MODEL = "models/anime_2.onnx"
sess = rt.InferenceSession(MODEL)
inp_name = sess.get_inputs()[0].name
def infer(rgb):
rgb = np.expand_dims(rgb, 0)
rgb = rgb * 2.0 / 255.0 - 1
rgb = rgb.astype(np.float32)
out = sess.run(None, {
inp_name: rgb})
out = out[0][0]
out = (out+1)/2*255
out = np.clip(out, 0, 255).astype(np.uint8)
return out
def preprocess(rgb):
pad_w = 0
pad_h = 0
h,w,__ = rgb.shape
N = 2**3
if h%N!=0:
pad_h=(h//N+1)*N-h
if w%2!=0:
pad_w=(w//N+1)*N-w
# print(pad_w, pad_h, w, h)
rgb = np.pad(rgb, ((0,pad_h),(0, pad_w),(0,0)), "reflect")
return rgb, pad_w, pad_h
among , preprocess Function to ensure that the width and height of the input image are 8 Integer multiple . This is mainly because the deep learning model has down sampling , Ensure that each down sampling can be 2 to be divisible by .



Use here Opencv library , Extract each frame in the video and call the callback function to send back the video frame . In the process of converting pictures to videos , By defining VideoWriter Type variable WRITE Make sure it's unique . The specific implementation code is as follows :
import cv2
from tqdm import tqdm
WRITER = None
def write_frame(frame, out_path, fps=30):
global WRITER
if WRITER is None:
size = frame.shape[0:2][::-1]
WRITER = cv2.VideoWriter(
out_path,
cv2.VideoWriter_fourcc(*'mp4v'), # Encoder
fps,
size)
WRITER.write(frame)
def extract_frames(video_path, callback):
video = cv2.VideoCapture(video_path)
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
for _ in tqdm(range(num_frames)):
_, frame = video.read()
if frame is not None:
callback(frame)
else:
break
Python Learning from actual combat Comic , Get the full source code . If you find this article helpful , Thank you for your free praise , Your effort will provide me with unlimited writing power ! Welcome to my official account. :Python Learning from actual combat , Get the latest articles first .