Recently, a good friend, ah Lang, was forced by his low salary , I am going to come to Shenzhen from my hometown in the north to find a job , Ah Lang, who studied graphic design, knew that I was in Shenzhen, so he asked me about the salary level of graphic design in Shenzhen , At that time, I was a little confused that I was not familiar with this industry , When you are ready to open the recruitment website, you should first look at it and then open the website to enter the recruitment positions. The number of job openings is quite large , It's too inefficient to look at it slowly , Why are you a programmer? Just pull down the data, so I have this blog .
import os
import json
import urllib
import requests
Data address :https://www.lagou.com/
When I was there chrom I found that the data on the page was not directly displayed on the source code when I entered the source code of the page in the pull tick website . The inference may be to use AJAX Load data asynchronously , When I open chrom The developer tools are in network View in XHR I found a https://www.lagou.com/jobs/positionAjax.json?city=%E6%B7%B1%E5%9C%B3&needAddtionalResult=false Request inching on response Sure enough, the data is returned in this request .
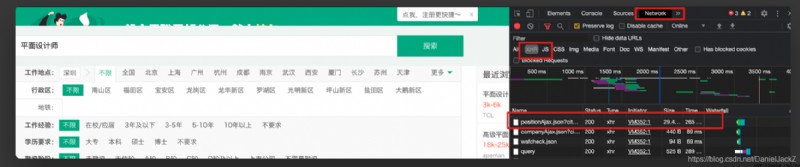
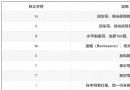
The returned data format is as follows :

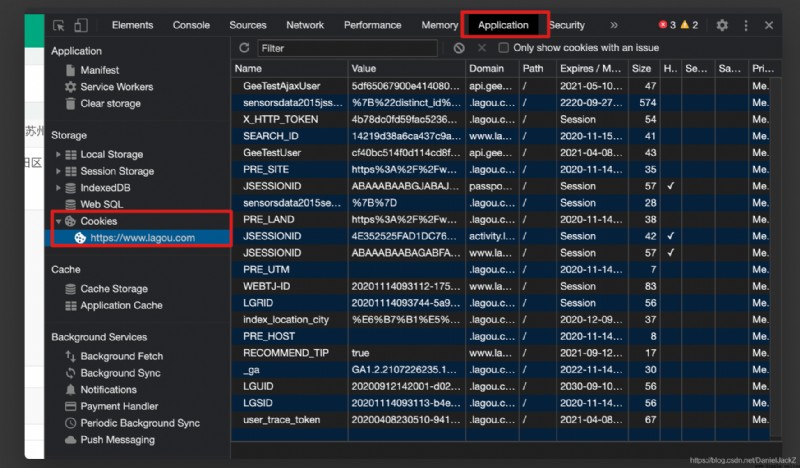
We can find that all the data we need are stored in result in , So I'm ready to get the data directly but use request To simulate the request discovery, it will be intercepted every time . Because the browser can get data without logging in, it should not be a user level interception , Guess it could be cookie The limitations of the level , It is found that the request does not carry the website cookie Direct interception
Please obtain the parameters
def get_request_params(city, city_num):
req_url = 'https://www.lagou.com/jobs/list_{}/p-city_{}?&cl=false&fromSearch=true&labelWords=&suginput='.format(urllib.parse.quote(city), city_num)
ajax_url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(urllib.parse.quote(city))
headers = headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://www.lagou.com/jobs/list_{}/p-city_{}?px=default#filterBox".format(urllib.parse.quote(city), city_num),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
return req_url, ajax_url, headers
So in Add to request cookie, The code is as follows :
def get_cookie(city):
city_num = get_city_num_by_name(city)
req_url, _, headers = get_request_params(city, city_num)
s = requests.session()
s.get(req_url, headers=headers, timeout=3)
cookie = s.cookies
return cookie
Although joining cookie Data can be obtained later, but each time it is the data on the first page and is the data of a fixed position , When the link requesting the real data address is viewed again, it is found that the request will carry query The parameters are as follows :
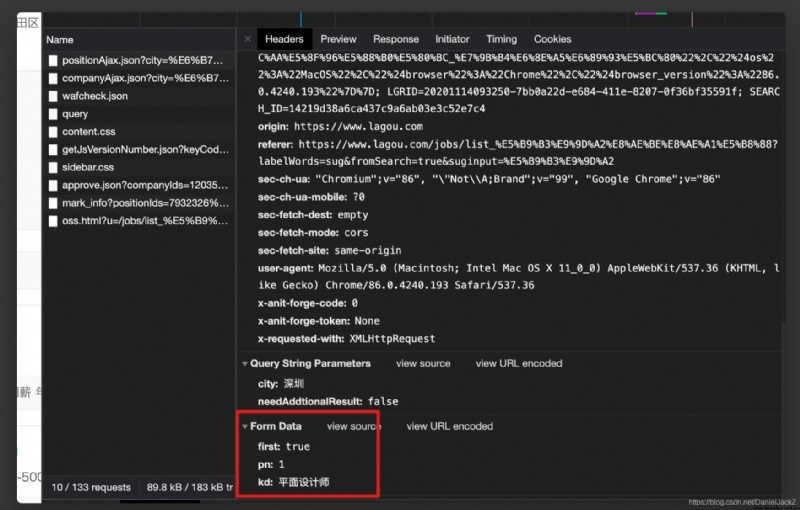
Therefore, request parameter acquisition is added :
def get_params(pn, kd):
return {
'first': 'true',
'pn': pn,
'kd': kd
}
Although we solve the request parameters and get the number of pages , But it's too rigid to crawl data from a fixed city at a time , It turns out that we are requesting data url There are city_nun This parameter , Every city has a corresponding number
Open the pull hook page source code and pull the page to the bottom to find cityNumMap, After finding this, we can control and obtain the desired city job information

import os
import json
import urllib
import requests
from cityNumMap import city_num_map
def validate_params(city, key_world):
if not city or not key_world:
raise Exception(' Input parameter cannot be empty ')
def get_city_num_by_name(city_name):
city_num = city_num_map.get(city_name)
if not city_name:
raise BaseException('>>> The city name you entered is incorrect , Please re-enter after confirmation ')
return city_num
def get_request_params(city, city_num):
req_url = 'https://www.lagou.com/jobs/list_{}/p-city_{}?&cl=false&fromSearch=true&labelWords=&suginput='.format(urllib.parse.quote(city), city_num)
ajax_url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city={}&needAddtionalResult=false'.format(urllib.parse.quote(city))
headers = headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Referer": "https://www.lagou.com/jobs/list_{}/p-city_{}?px=default#filterBox".format(urllib.parse.quote(city), city_num),
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36",
}
return req_url, ajax_url, headers
def get_params(pn, kd):
return {
'first': 'true',
'pn': pn,
'kd': kd
}
def get_cookie(city):
city_num = get_city_num_by_name(city)
req_url, _, headers = get_request_params(city, city_num)
s = requests.session()
s.get(req_url, headers=headers, timeout=3)
cookie = s.cookies
return cookie
def get_page_info(city, key_world):
params = get_params(1, key_world)
city_num = get_city_num_by_name(city)
_, ajax_url, headers = get_request_params(city, city_num)
html = requests.post(ajax_url, data=params, headers=headers, cookies=get_cookie(city), timeout=5)
result = json.loads(html.text)
total_count = result.get('content').get('positionResult').get('totalCount')
page_size = result.get('content').get('pageSize')
page_remainder = total_count % page_size
total_size = total_count // page_size
if page_remainder == 0:
total_size = total_size
else:
total_size = total_size + 1
print('>>> Total for this position {} Data '.format(total_size))
return total_size
def get_page_data(city, key_world, total_size):
path = os.path.dirname(__file__)
path = os.path.join(path, 'lagou.txt')
f = open(path, mode='w+')
city_num = get_city_num_by_name(city)
_, ajax_url, headers = get_request_params(city, city_num)
for i in range(1, total_size):
print('>>> Start getting the second {} Page data '.format(i))
params = get_params(i, key_world)
html = requests.post(ajax_url, data=params, headers=headers, cookies=get_cookie(city), timeout=5)
result = json.loads(html.text)
data = result.get('content').get('positionResult').get('result')
page_size = result.get('content').get('pageSize')
for i in range(page_size):
company_name = data[i].get('companyFullName')
company_size = data[i].get('companySize')
company_label = data[i].get('companyLabelList')
salary = data[i].get('salary')
education = data[i].get('education')
result_str = '{}&&{}&&{}&&{}&&{}\n'.format(company_name, company_size, company_label, salary, education)
f.write(result_str)
print('>>> Data acquisition complete ')
if __name__ == "__main__":
city = input('>>> Please enter the city where you want to search for the position :').strip()
kb = input('>>> Please enter the position you want to search :').strip()
validate_params(city, kb)
total_size = get_page_info(city, kb)
get_page_data(city, kb, total_size)
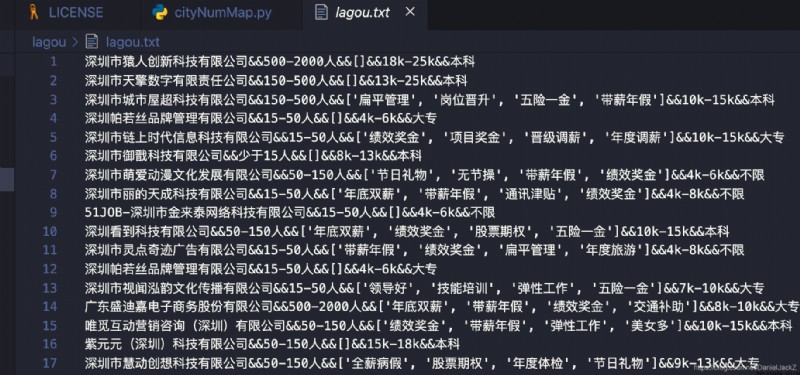
Execute locally pythin3 lagou.py Enter the address and position to be searched, and it will be generated in the current peer directory lagou.txt Files store data results

Project address : Complete code
 【OpenCV-Python-課程學習(賈)】OpenCV3.3課程學習筆記:圖像直方圖的計算、圖像直方圖特征的應用、直方圖反向投影、matplotlib繪制圖像直方圖
【OpenCV-Python-課程學習(賈)】OpenCV3.3課程學習筆記:圖像直方圖的計算、圖像直方圖特征的應用、直方圖反向投影、matplotlib繪制圖像直方圖
圖像直方圖,本質上就是對圖像的所有像素點的取值進行統計,在不
 How to collect daily hot content information with Python code and send it to your mailbox?
How to collect daily hot content information with Python code and send it to your mailbox?
Hey, everyone, good duck ! Im