When we search the content in the browser, we will find that the browser will automatically convert the content we enter into the content with quite a lot % The address of is as follows :
https://www.baidu.com/s?wd=%E4%B8%BA%E4%BB%80%E4%B9%88&rsv_spt=1&rsv_iqid=0xeaa7d7410002e421&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=9&rsv_sug1=11&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&prefixsug=%25E4%25B8%25BA%25E4%25BB%2580%25E4%25B9%2588&rsp=5&inputT=2965&rsv_sug4=3444
So why do browsers do this ? What's the use of doing this ?
Before we can understand the above problems, we need to find out URI、URL、 as well as URN
URI(Uniform Resource Identifier: Uniform resource identifiers ): Use a compact string to represent abstract or physical resources .URI It only specifies how to arrange resources, but it does not specify how to obtain resources .
URL(Uniform Resource Locator: Uniform resource locator ):URL yes URI The most common form of expression , It clearly explains how to get from a precise 、 Fixed location access to resources .URL It not only specifies how to identify resources, but also specifies how to obtain resources
Most of the URL All follow a standard format that consists of three parts :
URN(Uniform Resource Name: Unified resource name ):URN As a unique name for a specific content, it has nothing to do with the current location of the resource , Use these location independent URN You can move resources everywhere
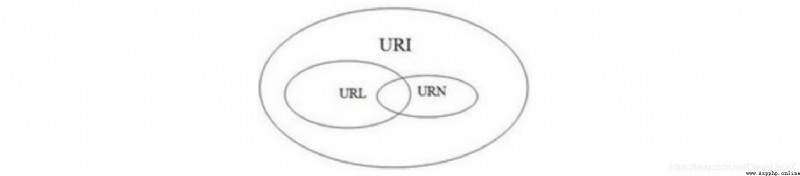
The relationship between the three is shown in the figure :
According to the above, we know that URL Is a resource qualifier , stay URL Some parameter strings in the use ke y=value The form of key value pairs is used to transfer parameters between key value pairs & symbols .
Suppose if your value contained = perhaps &, Then it will lead to receiving URL The server parsing error of resulted in the failure to obtain the correct resources , Therefore, it is necessary to bring about ambiguity & and = To escape a symbol is to encode it .
Or, URL The encoding format of is ASCII code , instead of unicode, That means you can't URL Include any non ASCII character , For example, Chinese , Otherwise, if the character sets supported by the client browser and the server browser are different, Chinese may cause problems .
There are many scenarios similar to the above situations, and there are no examples here , To avoid the above problems, the browser defaults to us URL Transference .
stay python3 Chinese will be urlencode urldecode Coding needs to use urllib This library
import urllib
urllib.parse.quote(string, safe='/', encoding=None, errors=None)
import urllib
urllib.parse.unquote(string, encoding='utf-8', error='replace')
import urllib
urllib.parse.quote(' Workers ')
>>> '%E6%89%93%E5%B7%A5%E4%BA%BA'
urllib.parse.unquote('%E6%89%93%E5%B7%A5%E4%BA%BA')
>>> ' Workers '