由於最近在研究爬蟲相關知識,有時在頻繁獲取(爬取)網站數據時會出現 ip 被限制的情況導致無法及時獲取想要的數據,因此想著該搞個 ip proxy pool 啦,啥也不說開始干呗。
import re
import json
import requests
import urllib
from lxml import etree
url = 'https://raw.githubusercontent.com/fate0/proxylist/master/proxy.list'
class GetIpProxyPool(object):
ping_url = 'https://blog.csdn.net/DanielJackZ/article/details/106870071'
def __init__(self, url):
self.url = url
self.get_proxy_data()
def get_proxy_data(self):
result = requests.get(self.url).text
self.store_data(result)
def store_data(self, data):
f = open('./res.txt', 'w+')
f.write(data)
f.close()
def get_read_lines(self):
f = open('./res.txt', 'rb')
lines = f.readlines()
return lines
def validate_proxy(self):
f = open('./useful.txt', 'w+')
lines = self.get_read_lines()
for line in lines:
line = json.loads(line.strip())
proxy_ip = {
line.get('type'): line.get('host')}
proxy_support = urllib.request.ProxyHandler(proxy_ip)
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')]
urllib.request.install_opener(opener)
try:
response = urllib.request.urlopen(self.ping_url, timeout=5)
except:
pass
if response.read().decode('utf-8'):
f.write(json.dumps(line) + '\n')
if __name__ == "__main__":
proxy_pool = GetIpProxyPool(url)
proxy_pool.validate_proxy()
這部分代碼中在 validate_proxy 中實現 ip 代理代碼部分為:
.request.ProxyHandler(proxy_ip)
opener = urllib.request.build_opener(proxy_support)
opener.addheaders = [('User-Agent',
'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')]
urllib.request.install_opener(opener)
在驗證ip 有效可用的方法上使用了一個比較笨的方法:讓獲取到的ip 去訪問某個網站,通過訪問結果是否正常來作為判斷依據,能正常獲取到請求內容的默認它是有效的反之則無效,後期會在針對這部分代碼進行優化
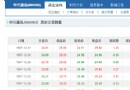
當我們通過上面的步驟構建個人 IP 代理池後,我們難道只是簡單的解決當我們在獲取數據時 IP 被限制這一個問題嗎,當然不是這玩意可以做的事情可多了,這裡我舉個簡單的應用場景,當我們寫一篇博客是發現閱讀量很低想要多刷點訪問量我們也可以通過代理 ip 方式去訪問對應的鏈接,達到增加訪問量的目的(note: 這只是一個簡單的應用場景舉例大家應該還是按照正常客流量來看待博客訪問量問題)
import os
import json
import requests
from lxml import etree
from urllib import request
def get_blog_list(blog_list_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.0.1 Safari/605.1.15'
}
html = requests.get(blog_list_url, headers=headers).text
selector = etree.HTML(html)
data = selector.xpath('//*[@id="articleMeList-blog"]/div[2]/div//a/@href')
return data
def brush_visits(data):
f = open(os.path.join(os.path.dirname(__file__), 'useful.txt'))
for line in f.readlines():
line = json.loads(line)
proxy_ip = {
line.get('type'): line.get('host')}
print('>>>', proxy_ip)
proxy_support = request.ProxyHandler(proxy_ip)
opener = request.build_opener(proxy_support)
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36')]
for link in data:
print('brush>>>', link)
request.urlopen(link)
# 這個地址換成你賬戶下的博客列表即可
blog_list_url = 'https://blog.csdn.net/xxxxx'
data = get_blog_list(blog_list_url)
brush_visits(data)
項目源碼地址