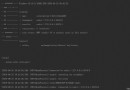
當我們在浏覽器搜索內容時會發現浏覽器會自動的將我們輸入的內容轉化為帶有 很多% 的地址如下所示:
https://www.baidu.com/s?wd=%E4%B8%BA%E4%BB%80%E4%B9%88&rsv_spt=1&rsv_iqid=0xeaa7d7410002e421&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=9&rsv_sug1=11&rsv_sug7=101&rsv_sug2=0&rsv_btype=i&prefixsug=%25E4%25B8%25BA%25E4%25BB%2580%25E4%25B9%2588&rsp=5&inputT=2965&rsv_sug4=3444
那麼為什麼浏覽器要這麼做?這麼做有什麼用?
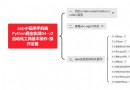
在了解上面的問題前我們需要先搞清楚 URI、URL、以及URN
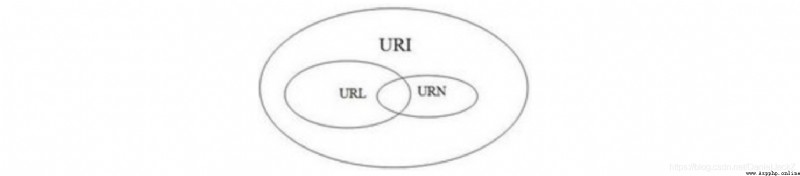
URI(Uniform Resource Identifier:統一資源標識符): 用一個緊湊的字符串來表示抽象或物理資源。URI 只是規定如何擺哦是資源但是沒有規定如何獲取資源。
URL(Uniform Resource Locator:統一資源定位符):URL是URI最常見的表現形式,它明確說明如何從一個精准、固定的位置獲取資源。URL不但規定了如何標識資源同時還規定了如何獲取資源
大部分URL都遵循一種標准格式這種格式包含三個部分:
URN(Uniform Resource Name:統一資源名稱):URN作為特定內容的唯一名稱使用與目前的資源所在地無關,使用這些這些位置無關的URN就可以將資源到處搬遷
三者關系如圖所示:
根據上面的內容我們了解到 URL 是資源定符,在URL中有些參數字符串是使用ke y=value 鍵值對的形式傳參鍵值對之間使用 & 符號分隔。
假設如果你的value中包含有 = 或者 &,那麼將會導致接收URL的服務器解析錯誤導致無法獲取正確的資源,因此必須將引起歧義的 & 和 = 符號進行轉義也就是對其進行編碼。
又或者 URL 的編碼格式采用 ASCII 碼,而不是unicode,這也是就是說你不能在URL中包含任何非ASCII 字符,例如中文,否則如果客戶端浏覽器和服務端浏覽器支持的字符集不同中文可能會造成問題。
類似以上的情況還有很多場景這裡就不一一舉例,為了避免上述問題浏覽器默認對我們URL進行轉義。
在 python3 中將中文進行 urlencode urldecode 編碼需要使用 urllib 這個庫
import urllib
urllib.parse.quote(string, safe='/', encoding=None, errors=None)
import urllib
urllib.parse.unquote(string, encoding='utf-8', error='replace')
import urllib
urllib.parse.quote('打工人')
>>> '%E6%89%93%E5%B7%A5%E4%BA%BA'
urllib.parse.unquote('%E6%89%93%E5%B7%A5%E4%BA%BA')
>>> '打工人'