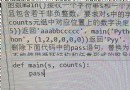
import xlwings as xw # Import xlwings modular
file_path = 'e:/table/text.xlsx' # Give the file path of the source workbook
sheet_name = 'sheetOne' # Give the name of the worksheet to split
app = xw.App(visible=False,add_book=False)
workbook = app.books.open(file_path) # Open source workbook
worksheet = workbook.sheets[sheet_name] # Select the sheet to split
value = worksheet.range('A2').expand('table').value # Read all data in the worksheet to be split
data = dict() # Create an empty dictionary to store data by product name
for i in range(len(value)): # Traverse worksheet data by row
product_name = value[i][1] # Get the product name of the current line , As the classification basis of data
if product_name not in data: # Judge whether the product name of the current line does not exist in the dictionary
data[product_name] = [] # If it doesn't exist , Create an empty list corresponding to the product name of the current line , Used to store the data of the current row
data[product_name].append(value[i]) # Append the data of the current line to the list corresponding to the product name of the current line
for key,value in data.items(): # Traverse the classified data by product name
new_workbook = xw.books.add() # New target Workbook
new_worksheet = new_workbook.sheets.add(key) # Add a new worksheet in the target workbook and name it the current product name
new_worksheet['A1'].value = worksheet['A1:H1'].value # Copy the column headings of the worksheet to be split into the new worksheet
new_worksheet['A2'].value = value # Copy the data under the current product name to the new worksheet
new_workbook.save('{}.xlsx'.format(key)) # Save the target Workbook with the current product name as the file name
app.quit()
Code parsing :
The first 2~7 Line code is used to specify which worksheet in which workbook to split , And read all the data in this worksheet . The first 7 In line code “A2” It refers to the starting cell for reading data , It can be changed according to actual needs .
The first 9~13 In line code for Statement uses the 8 Line of code to create an empty dictionary according to production Sort out the previously read data by product name . The first 10 In line code value[i][1] Used to count Determine the classification basis according to the rows and columns of the region , The two bracketed values are used to specify the line sequence number And column sequence number ( All from 0 Start ), for example ,[0][0] On behalf of the 1 Xing di 1 Column ,[0][1] On behalf of the 1 Xing di 2 Column ,[1][1] On behalf of the 2 Xing di 2 Column , And so on . The classification of this case is based on “ production Product name ”, This column is located in the... Of the entire data area B Column , That is the first. 2 Column , therefore value after [i][1]. Classification basis can be set according to actual demand
The first 14~19 In line code for Statement to create a new workbook , And sort out the front Copy the data of to the worksheets of these new workbooks respectively . The first 17 Line code ,A1:H1 Represents the worksheet to split “ Statistical table ” Column header cell range ,A1 Then it means to start a new job Make the cells of the worksheet in the workbook A1 Start pasting column header cell range . The first 18 Line code Of A2 It refers to the cells of the worksheet in the new workbook A2 The number of products after starting to paste the classification According to the . this 3 Parameters can be changed according to actual needs
Expand (format() function ):
s1 = '{} This year, {} year .'.format(' Xiao Ming ', 7) # Do not set the splicing position , Splice in the default order
s2 = '{1} This year, {0} year .'.format(7, ' Xiao Ming ') # Specify the splice position with a numerical sequence number
s3 = '{name} This year, {age} year .'.format(name=' Xiao Ming ', age=7) # Specify the splice location with the variable name
print(s1)
print(s2)
print(s3)
import xlwings as xw # Import xlwings modular
import pandas as pd
app = xw.App(visible=False,add_book=False)
workbook = app.books.open('e:\\table\\text.xlsx') # Open the workbook
worksheet = workbook.sheets[sheet_name] # Select the sheet to split
value = worksheet.range('A1').options(pd.DataFrame,header = 1,index = False,expand = 'table').value # Read the worksheet data to be split
data = value.groupby('product_name') # Set the data according to 'product_name' grouping
for idx,group in data:
new_worksheet = workbook.sheets.add(idx) # Add a new worksheet to the workbook and name it the current product name
workbook.save()
workbook.close()
app.quit()
 〖Python database development practice - MySQL chapter ⑨〗 - what is the SQL language, how to create a data logic library and how to create a data table
〖Python database development practice - MySQL chapter ⑨〗 - what is the SQL language, how to create a data logic library and how to create a data table
萬葉集?? 隱約雷鳴,陰霾天空. ???? 但盼風雨來,能留