記錄一下自己的學習過程。
有很多省份的數據,想要求全國的綜合。這些數據都分別存在csv裡。如下:
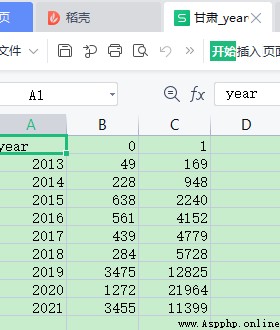
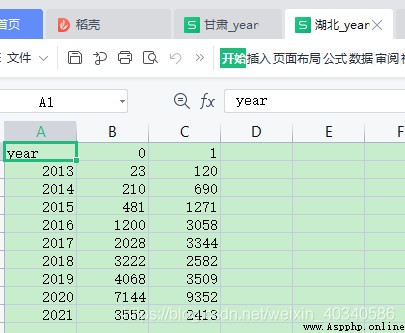
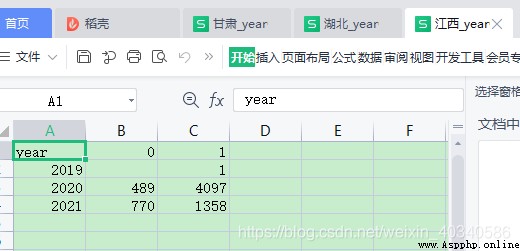
我希望把全部省份加起來, 算一個全國總和。這時候需要用到數據表對應值相加。
代碼如下:
先讀進來一個數據表,比如
df1 是湖北的。
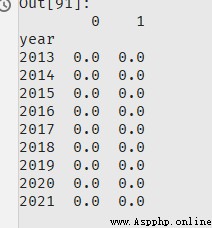
在df1 的基礎上創建一個空表。
df_empty = pd.DataFrame(np.zeros(df1.shape), columns=df1.columns, index=df1.index)
這樣df_empty是
然後寫一個for循環,逐個加進來。
for i in range(len(result_list)):
print("\n************\n")
print(result_list[i])
print(prov_list[i])
dfi = pd.read_csv(os.path.join(result_data_dir, result_list[i]), index_col='year')
print(dfi)
dfi = dfi.fillna(0)
print(i)
df_empty = df_empty.add(dfi, fill_value = 0)
print(df_empty)中間有很多打印的內容,其實關鍵的是其中兩句。
dfi = pd.read_csv(os.path.join(result_data_dir, result_list[i]), index_col='year') 這一句保證讀進來的數據索引相同,列相同。
相加,
df_empty = df_empty.add(dfi, fill_value = 0)
這一句可以讓數據表相加,相當於矩陣的點加。
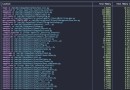
得到最後結果如下
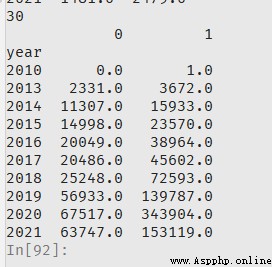
其中fill_value=0,不能省略,因為如果不加,那麼add的時候,會把一些有缺失的格變成缺失,最後加起來會有很多缺失。
看樣子原來沒有的行,比如2010,會自動添加進去。總和數據表裡多了2010這一行。