#####################################################
##### Operation on movie data . Generate dummy variables
#####################################################
import os
data_dir = "python Data Science Handbook /pydata-book-2nd-edition- Code /datasets/movielens"
mnames = ['movie_id', 'title', 'genres']
movies = pd.read_table(os.path.join(data_dir, 'movies.dat'), sep='::', header=None, names=mnames)
movies.head()
all_genres = []
for x in movies.genres:
all_genres.extend(x.split('|'))
movies.shape
len(all_genres)
genres = pd.unique(all_genres)
len(genres)
genres
'''
Build metrics DataFrame One way to do this is to start with an all zero DataFrame Start :
'''
zero_matrix = np.zeros((len(movies), len(genres)))
zero_matrix.ndim
zero_matrix.shape
dummies = pd.DataFrame(zero_matrix, columns=genres)
dummies
gen = movies.genres[0]
gen
gen.split('|')
dummies.columns.get_indexer(gen.split('|'))
######################
#### there get_indexer It's very functional , Is to get the tag , From a list , find In accordance with , Get its number .
# Must be columns Methods .
######################
dummies.columns.get_indexer(movies.genres[1].split('|'))
dummies.columns.get_indexer(movies.genres[3].split('|'))
movies.genres
for i, gen in enumerate(movies.genres):
indices = dummies.columns.get_indexer(gen.split("|"))
dummies.iloc[i, indices] = 1
dummies
'''
This operation Worth learning .
'''
#
# g2 = movies.genres[2]
# g2
# g2.split('|')
#
# dummies
# x = pd.DataFrame(np.zeros(18))
# x
# x.get_indexer(g2.split('|'))
# x.columns = genres
# genres
# dfx = pd.DataFrame(x, columns=genres)
# dfx
# dfx.get_indexer(g2.split('|'))
# dfx.columns.get_indexer(g2.split('|'))
# locx = dfx.columns.get_indexer(g2.split('|'))
# locx
#
# dfx.iloc[0, locx] = 10
# dfx.iloc[0,]
# dfx
movies_windic = movies.join(dummies.add_prefix('Genre_'))
movies_windic.iloc[0]
In this code , The most coquettish operation is get_indexer.
Use cut It is also convenient to generate dummy variables .
such as
np.random.seed(12345)
values = np.random.rand(10)
values
bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
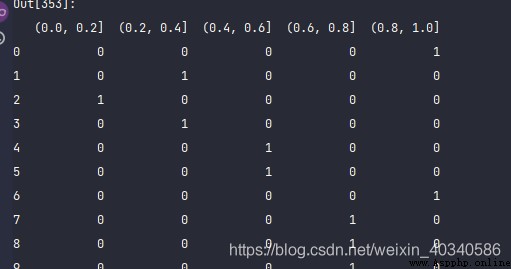
pd.get_dummies(pd.cut(values, bins))
in addition , add_prefix, You can directly modify all variable names . such as :
df = pd.DataFrame(np.arange(12).reshape(3, 4),
columns=list('abcd'))
df
df.add_prefix('key_')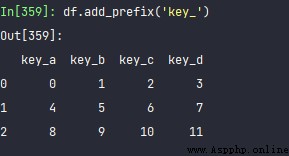
This part uses my own example to make a .
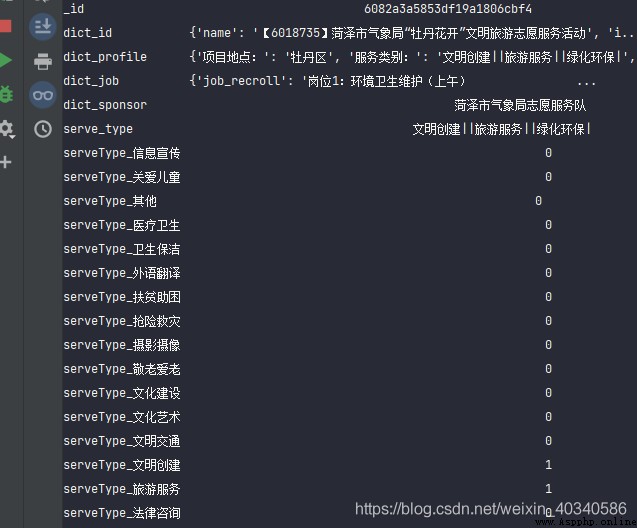
There is a data like this .
Activities of some organizations , It is also divided into many categories .
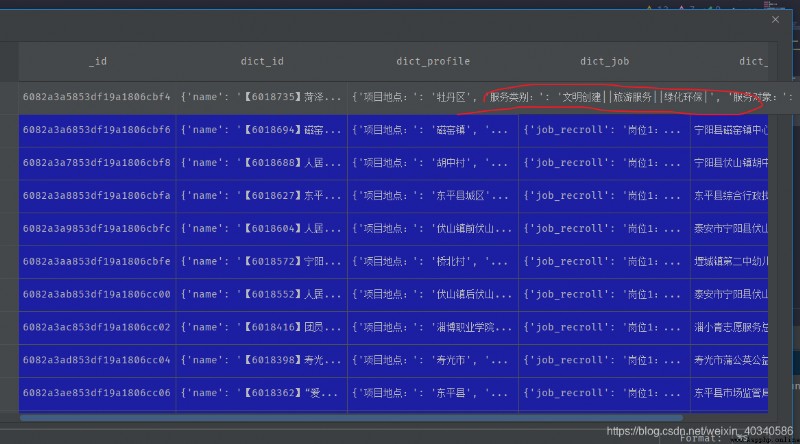
This data is just a little more complicated , The service category is in dict_profile Inside this key . You need to pull it out . No effect .
import os
path = "all_volunteer_data_dir/ Information about each project ( Contains multiple dictionaries )"
import pandas as pd
df = pd.read_pickle(path)
df.keys()
df.iloc[0,]
df.shape
df = df.iloc[:100]
df.shape
df.keys()
df['dict_profile']
serve_type = []
for i in range(df.shape[0]):
profile = df.iloc[i, ]['dict_profile']
serve_type.append(profile[' Service category :'])
serve_type

First get serve_type A list of . Then add only df
df['serve_type'] = serve_type
df.iloc[0, ]["serve_type"].split('|')
st1 =df.iloc[0, ]["serve_type"]
st1.split('|')
st1
Okay , Be ready , Start generating dummy variables .
serve_type_all = []
for i in range(df.shape[0]):
serve_type_listi = df.iloc[i,]['serve_type'].split("|")
serve_type_all.extend(serve_type_listi)
len(serve_type_all)
pd.Series(serve_type_all).value_counts()
import numpy as np
serve_type_all = np.unique(serve_type_all)
serve_type_all
serve_type_all.delete([""])
serve_type_all
new_serve_type_all = np.delete(serve_type_all, 0)
new_serve_type_all
This gives you a list of all service categories .

however , This still can't be used in a loop
In the cycle , Add a judgment , Character length cannot be 0, It was eliminated , Space .
for i, st in enumerate(df['serve_type']):
st_list = st.split('|')
clean_st_list = [ s for s in st_list if len(s) >0]
indices = dummies.columns.get_indexer(clean_st_list)
dummies.iloc[i, indices] = 1
dummiesresult , You can get dummies

Look at the first line of data , give the result as follows :
df_with_serve_type = df.join(dummies.add_prefix("serveType_"))
df_with_serve_type.iloc[0, ]