Just personal notes , No ornamental value .
'''
7.2 Detect and filter outliers
'''
data = pd.DataFrame(np.random.randn(1000, 4))
data.describe()
col = data[2]
col
col[np.abs(col) > 3]
data
data.head()
data.columnnames =['a', 'b', 'c', 'd']
###################
# columnnames The name of the column will not be changed , What will that change ?
data
data.columns = ['a', 'b', 'c', 'd']
data[data['a'] > 3].idxmax()
data['a'] > 3
data[data['a'] > 3]
c = data['c']
c.idxmax()
c
data['c'].nlargest()
c.argmax(2)
np.argpartition(c, )
x = np.array([4, 3, 2, 1])
np.argpartition(x, 3)[0]
np.argpartition(x, 3)
np.argpartition(x,3)
np.argpartition(x,2)
np.argpartition(x,5)
np.argwhere(x, 3)
data[(np.abs(data)> 3).any(1)]
data[data>3].any(1)
(data>3).any(1)
######################### It seems that it must be written in the above way ,
data[(data>3.5).any(1)]
data[(np.abs(data) > 3).any(1)]
col[(np.abs(col) > 2).any(1)]
data[(data > 3).any(1)]
data[(data > 3).any(1)]
data[(data > 3).any()]
data[np.abs(data) > 3] = np.sign(data) * 3
data
data.describe()Here's to learn any Application .
dataframe Find a number that matches the criteria in the
data = pd.DataFrame({
'name':[' Zhang San ', ' Li Si ', ' Wang Wu ', ' Zhao Liu ', ' Chen Qi ', ' Zheng Ba ', ' Week nine '],
'age':np.random.randint(10, 30, 7)
})
data
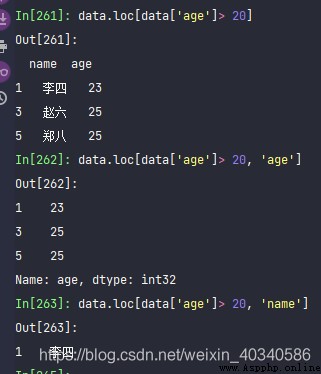
data.loc[data['age']> 20, 'age']
data.loc[data['age']> 20, 'name']
data.loc[data['age']> 20, 'name'].valuesUse loc, You can get the results you want .
'''
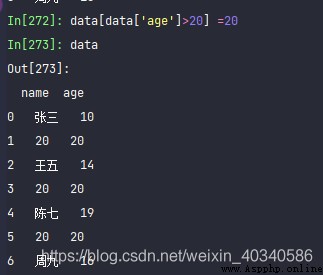
If I want to batch replace , The greater than 25 Replacement 25, Well, that's it .
'''
data[data['age']>20] =20
data