只是個人筆記,沒有觀賞價值。
'''
7.2 檢測和過濾異常值
'''
data = pd.DataFrame(np.random.randn(1000, 4))
data.describe()
col = data[2]
col
col[np.abs(col) > 3]
data
data.head()
data.columnnames =['a', 'b', 'c', 'd']
###################
# columnnames 不會改變列的名字, 那會改變什麼呢?
data
data.columns = ['a', 'b', 'c', 'd']
data[data['a'] > 3].idxmax()
data['a'] > 3
data[data['a'] > 3]
c = data['c']
c.idxmax()
c
data['c'].nlargest()
c.argmax(2)
np.argpartition(c, )
x = np.array([4, 3, 2, 1])
np.argpartition(x, 3)[0]
np.argpartition(x, 3)
np.argpartition(x,3)
np.argpartition(x,2)
np.argpartition(x,5)
np.argwhere(x, 3)
data[(np.abs(data)> 3).any(1)]
data[data>3].any(1)
(data>3).any(1)
######################### 看來必須用上面的方式寫,
data[(data>3.5).any(1)]
data[(np.abs(data) > 3).any(1)]
col[(np.abs(col) > 2).any(1)]
data[(data > 3).any(1)]
data[(data > 3).any(1)]
data[(data > 3).any()]
data[np.abs(data) > 3] = np.sign(data) * 3
data
data.describe()這裡學習一下any的應用。
dataframe 裡查找某個符合條件的數字
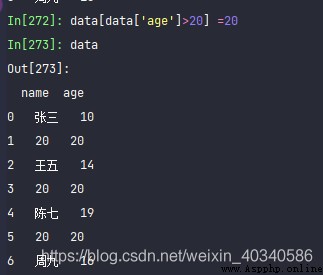
data = pd.DataFrame({
'name':['張三', '李四', '王五', '趙六', '陳七', '鄭八', '周九'],
'age':np.random.randint(10, 30, 7)
})
data
data.loc[data['age']> 20, 'age']
data.loc[data['age']> 20, 'name']
data.loc[data['age']> 20, 'name'].values使用loc,就可以得到想要的結果。

'''
如果我想批量替換,把大於25的替換25, 那麼該這樣。
'''
data[data['age']>20] =20
data