記錄一下自己的爬蟲踩過的坑,上一次倒是寫了一些,但是寫得不夠清楚,這次,寫清楚爬取的過程。
這個網站是某省的志願服務網。
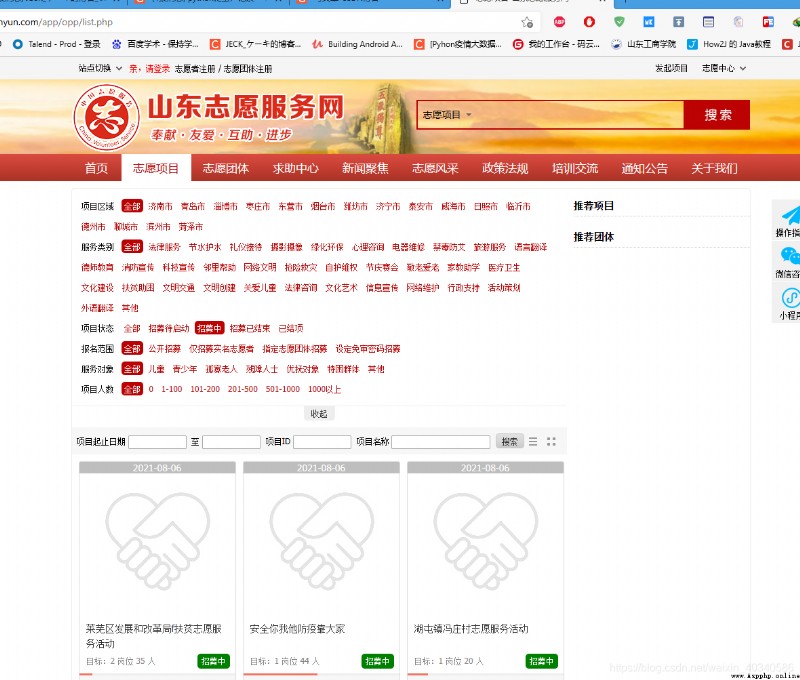
就是它了。
我向爬取一些組織開展過的活動,比如這一個組織,
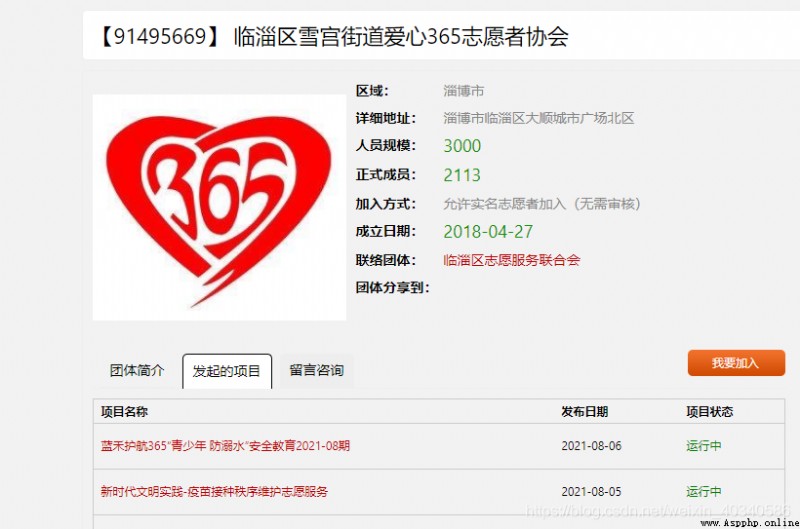
這個組織的頁面找打它不存在什麼問題,組織的網址只需要拼接就可以了。
看似很容易。
基礎網址是:https://sd.zhiyuanyun.com/app/org/view.php?id=(*****)
前面是一堆,後面只需要把id後面的組織的ID放進去就可以,組織的ID也很好找。就是直接從首頁一頁頁爬也行。這個網站的首頁也不復雜。
但是現在我要得到這個組織開展的活動列表。
比如這個組織。
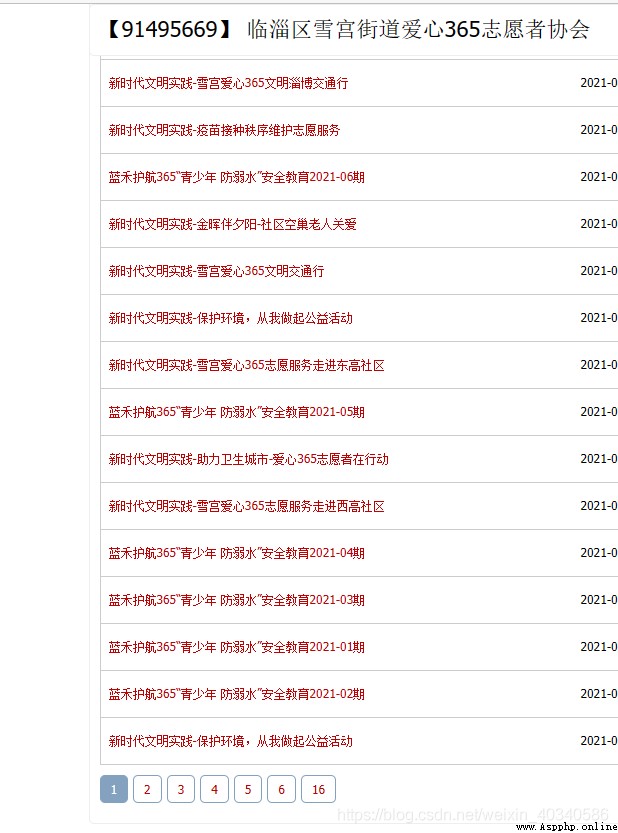
這個組織開展的活動蠻多的,看出來會有16頁,最下面有標簽,16.
難點是我怎麼能知道最後一個頁是16,就是最大的數, 有的組織只有1頁,有的7,有的8.我得知道這個最末頁的數,才能寫一個循環。不能直接寫一個while true 來一個break吧。
這時候,就需要研究一下這個網頁的請求方式了。
這個網頁請求使用的是post,而不是get。如果是get, 那麼只能得到的頁面是。
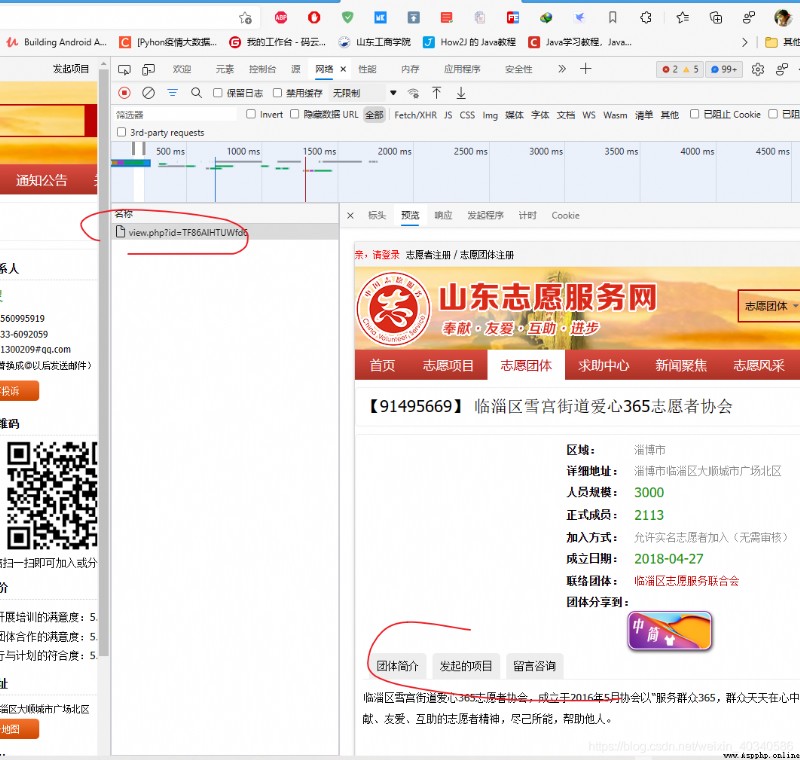
是這樣一個頁面,get請求的網址也是沒錯的。
https://sd.zhiyuanyun.com/app/org/view.php?id=TF86AlHTUWfd6
但是發起的項目這個部分,是看不到的。再仔細研究看看。其實在請求過程中,還有一個js請求。
剛開始我以為是xhr,即ajax,找了半天也沒找到。
清空一下網絡請求信息,點一下某一頁的項目。就會看到一個post請求的
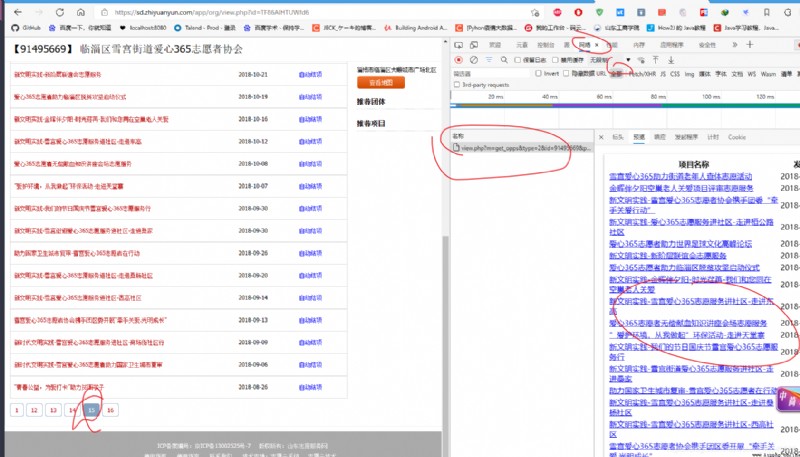
這個post請求,復制出來,注意是復制curl (bash)
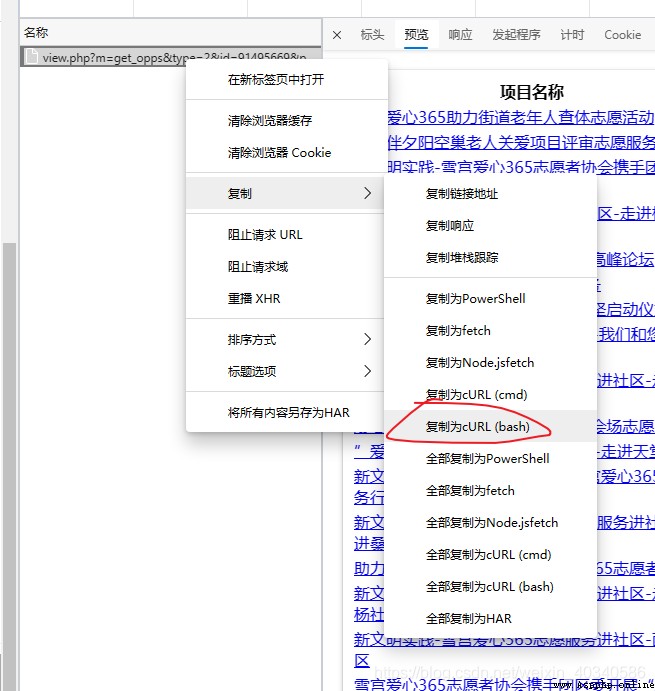
把這個貼進去 生成請求的網頁,就可以得到python的請求代碼。
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, and Rust code (trillworks.com)
Convert curl command syntax to Python requests, Ansible URI, browser fetch, MATLAB, Node.js, R, PHP, Strest, Go, Dart, Java, JSON, Elixir, and Rust code
https://curl.trillworks.com/
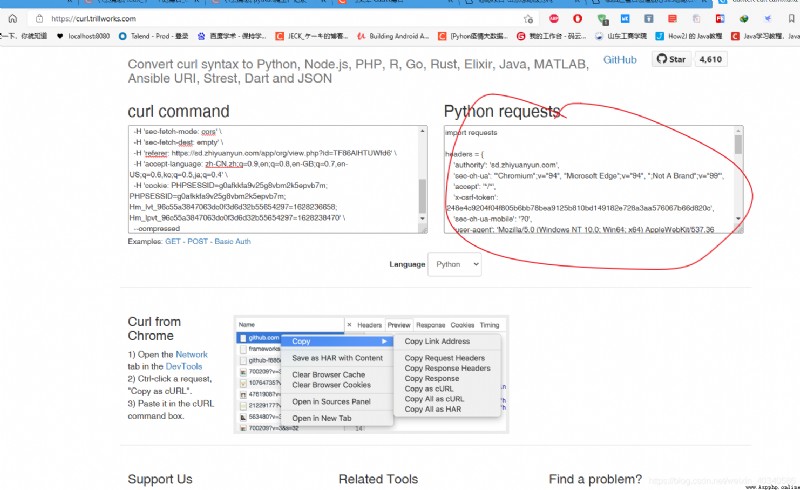
右側的代碼部分復制出來,放到pycharm裡,
可以看到是這樣的。
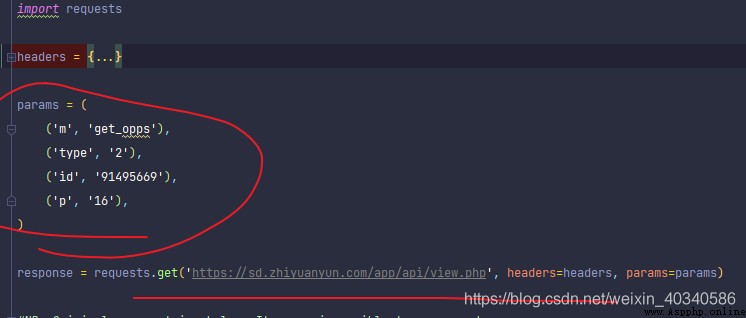
header部分省略了。重要是參數部分。
注意到這裡的實際請求網址應該是這樣的,每一個參數都是組合成 & 和= 號組合起來的。基礎網址是橫線上的。
https://sd.zhiyuanyun.com/app/api/view.php?m=get_opps&type=2&id=91495669&p=16
所以打開這個網址,就可以得到實際請求的網頁。是這樣的,一個簡單的表單網頁。結構很簡單。
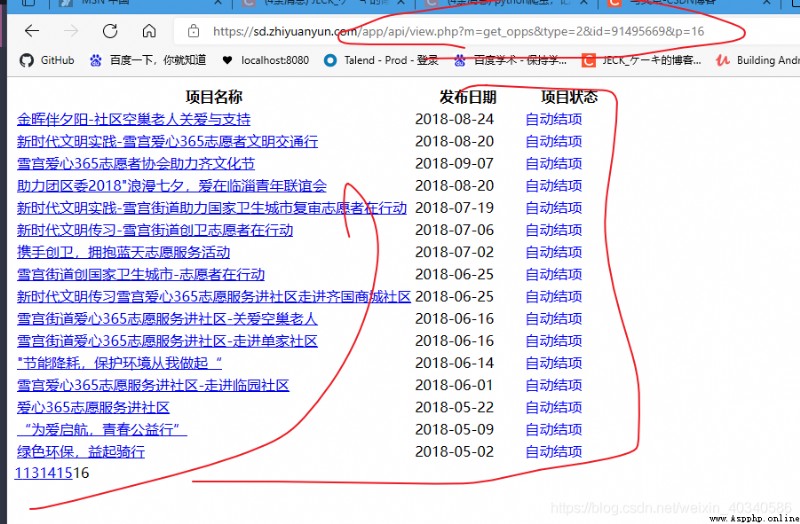
地址欄是我們拼接的網址,?後面是請求的參數,每一個參數的名和值用=鏈接,中間用&鏈接。
那麼就得到了。
這是請求過程。
接下來是保存數據的過程。
對於這種表單,我一直覺得麻煩, 所以直接就是保存成列表,放入字典。
以後用的時候再拆開。
請求得到結果如圖
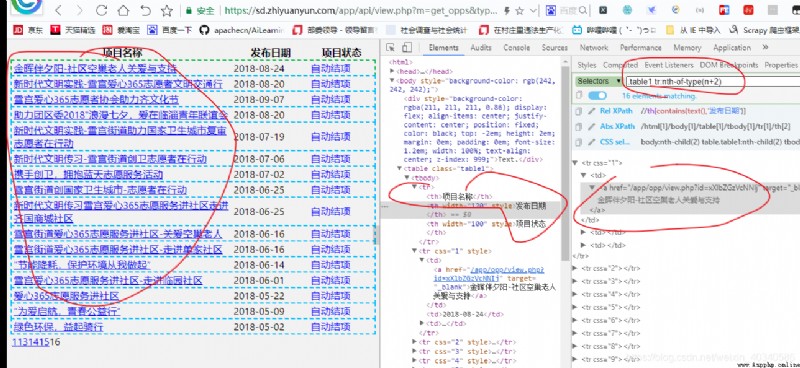
得到的response實際上就是一個表單組成的網頁。用selector解析一下。
from scrapy.selector import Selector
import requests
headers = {*********************}
params = (
('m', 'get_opps'),
('type', '2'),
('id', '91495669'),
('p', '16'),
)
response = requests.get('https://sd.zhiyuanyun.com/app/api/view.php', headers=headers, params=params)
selector = Selector(response)
這時,我想要的就是表單裡的信息,不想要表頭,所以我用css選擇器,選擇從tr開始,tr裡面,第一欄的tr是表頭,所以不要表頭,用
.table1 tr:nth-of-type(n+2)
這樣的到下
tr = selector.css(".table1 tr:nth-of-type(n+2)")
for xi in tr:
a = xi.css('td a::text').extract_first()
href = xi.css('td a::attr(href)').extract_first()
print( a , href)
面的,然後再做一個遍歷,就可以提取所有的項目名稱和時間等信息。
這裡我只想要的是 項目名和鏈接,打印出來可以看到,是這樣的。
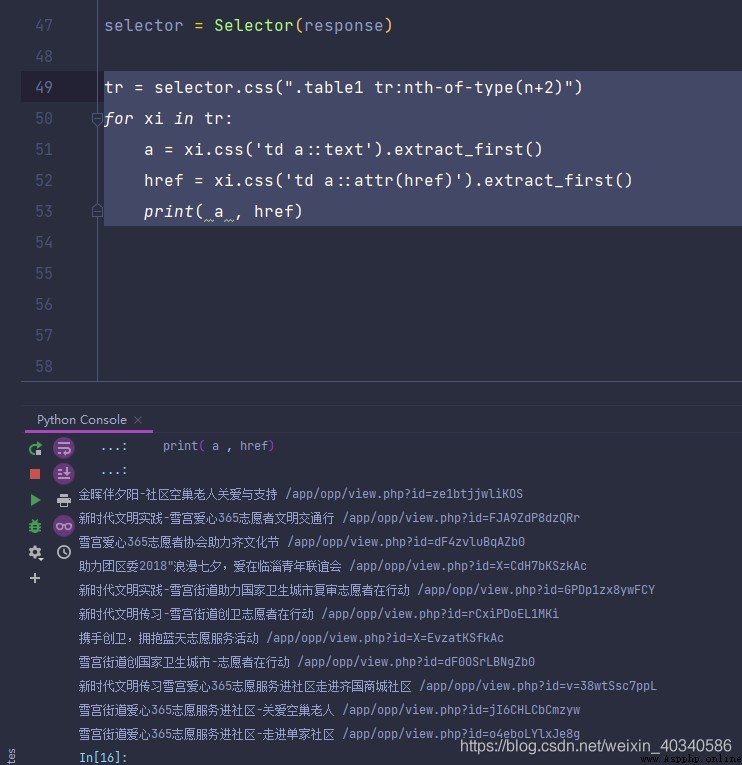
tr = selector.css(".table1 tr:nth-of-type(n+2)")
name_list = []
href_list = []
for xi in tr:
a = xi.css('td a::text').extract_first()
href = xi.css('td a::attr(href)').extract_first()
# print( a , href)
name_list.append(a)
href_list.append(href)
print(name_list, href_list)
dct_app = {}
dct_app.update(name = name_list, href = href_list)
dct_app
保存成字典,最後,就是把所有的組織都爬下來,這個是看願意爬多少了。還有就是上面請求的參數部分,參數裡的組織的鏈接是遺傳字符,而請求組織的ID確實一串數字,這一串數字在每一個組織的名字前的方括號裡,因此,這個信息也是必須的。