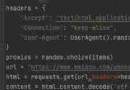
首先,正則替換部分字,這個還是挺有用的,比如姚把人名的某一個字符替換成*,保障隱私,一個兩個手動還可以多了就麻煩。
比如有一個名字列表

我要快速把中間的字符替換成*號。
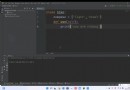
for k, v in dct230.items():
print(k)
k2 = re.sub(r"([\u4e00-\u9fa5])([\u4e00-\u9fa5])([\u4e00-\u9fa5]{0,1})", r"\1*\3", k)
print(k2)
dct230[k2] = dct230.pop(k)在python裡面,用分組解決正則問題,分組時用括號,替換時喲弄\1, \2, \3來代表選中的內容。
替換完了,把原來的字典換成替換後的鍵名。
用
pop取出原來的鍵值,生成了一副新的。
然後,用字典生成dataframe時,會有錯誤。直接生成,會提示報錯。
ValueError: If using all scalar values, you must pass an index這時可以使用:
pd.DataFrame(dct230, index=[0])
pd.DataFrame.from_dict(dct230, orient='index')
pd.DataFrame(list(dct230.itemsru ()))這幾種方式都可以。