First , Regular replacement of some words , This is still very useful , For example, Yao replaced a character of a person's name with *, Privacy protection , One or two manual operation is OK. If it is too much, it will be troublesome .
For example, there is a list of names

I want to quickly replace the middle character with * Number .
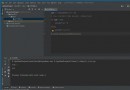
for k, v in dct230.items():
print(k)
k2 = re.sub(r"([\u4e00-\u9fa5])([\u4e00-\u9fa5])([\u4e00-\u9fa5]{0,1})", r"\1*\3", k)
print(k2)
dct230[k2] = dct230.pop(k)stay python Inside , Solve the regularization problem by grouping , Use parentheses when grouping , When you replace it, you do it \1, \2, \3 To represent the selected content .
Replacement completed , Replace the original dictionary with the replaced key name .
use
pop Take out the original key value , A new pair of .
then , Use a dictionary to generate dataframe when , There will be mistakes . Directly generate , It will prompt for an error .
ValueError: If using all scalar values, you must pass an indexYou can use :
pd.DataFrame(dct230, index=[0])
pd.DataFrame.from_dict(dct230, orient='index')
pd.DataFrame(list(dct230.itemsru ()))All these methods are OK .