注:可能有些圖片未能成功上傳,可在文檔處進行下載
鏈接:Python數據處理課程設計-房屋價格預測-機器學習文檔類資源-CSDN下載
課程設計報告
課程名稱
Python數據處理課程設計
項目名稱
房屋價格預測
目錄
一. 題目背景.. 3
1.選題背景... 3
2.研究意義... 3
3.題目描述... 3
4.選題數據... 3
二. 現有研究狀態... 4
三. 運用的技術手段和方法... 5
3.1 EDA(探索性數據分析)... 5
3.2 異常值的處理.. 5
3.3合並訓練集和測試集... 6
3.4 刪除多余的列.. 6
3.5 缺失值的處理.. 6
3.6 數據類型轉換.. 6
3.7 數據對數化處理... 6
3.8 得到數據特征的重要性並做成DataFrame形式... 6
3.9 對數據特征重要性數值進行可視化.. 6
3.10 對數據進行合並... 7
3.11 取出處理後的測試集數據... 7
3.12 使用機器學習模型對數據進行預測.. 7
四. 數據分析.. 7
4.1 EDA(探索性數據分析)... 7
4.2異常值處理.. 7
4.3合並訓練集和測試集... 11
4.4刪除多余的列... 11
4.5缺失值處理.. 11
4.6數據類型轉換... 14
4.7數據對數化處理.. 14
4.8 得到數據特征的重要性並做成DataFrame形式... 16
4.9 對數據特征重要性數值進行可視化.. 17
4.10 對數據進行合並... 18
4.11 取出處理後的測試集數據... 20
4.12使用機器學習模型對數據進行預測... 20
4.13 有意義的方面... 21
五. 項目總結.. 22
六. 參考文獻.. 23
1.選題背景
隨著經濟的持續發展,房地產行業已經成為了支柱產業,房屋價格不僅直接影響著居民的生活水平,也間接影響著國家經濟的持續、健康、平穩發展,房屋價格已經成為關系民生的熱點問題。房價是否合理,僅僅通過表面觀察和憑空想象是不能回答這些問題的,要通過科學的研究方法才能得出合理的結論。房屋價格受到很多因素的制約和影響,比如:地理位置、建造房子所用的材料、住宅風格、住宅類型、有無地下室、有無車庫、柵欄的質量、家庭的功能等,都會對房價產生影響。所以要選取的特征因素應當具有全面性、多樣性,選擇與房價密切相關的指標,對數據進行分析、處理,利用機器學習算法研究其對價格的影響程度,並構建出穩定性好、誤差小的價格預測模型,較為准確地預測出房子的最終價格,從而為政府相關部門宏觀調控、房地產開發商以及賣房或買房者提供科學的定價以及估價依據,更好地推進房屋市場的穩定發展。
2.研究意義
目前有人在對房屋價格的研究上已經取得了諸多成果,大多數人主要從政治、經濟、政策、人口等宏觀層面對房屋價格進行了分析,也有少數學者從房屋建築硬件設施等微觀因素展開了研究,也取得了較好的預測效果,但目前這方面還是相對較少。鑒於此,我將根據比賽的數據,構建特征變量集,選取有代表性的特征變量,在已有數據的基礎上,對數據進行處理,使用機器學習算法分析房價問題,選擇預測模型將其用於預測測試集的房屋價格。
此外,無論是對於監管者還是消費者,是房產中介機構還是房地產開發商,只有深入了解房地產交易市場,才能進行合理監管與規劃;高效率推廣房源,在能滿足購房者需求的前提下科學定價,提高市場競爭優勢;有效規避風險,降低不必要的損失等。所以預測房屋價格能為人們在住房購買方面提供更多選擇,具有一定的參考作用。
3.題目描述
購房者描述了他們夢想中的房子,他們可能不會從地下室天花板的高度或東西向鐵路的距離開始。但這些數據證明,影響價格談判的因素遠大於臥室數量或白色柵欄。題目給出的變量幾乎描述了愛荷華州艾姆斯市住宅的各個方面。根據題目所給出的訓練集和測試集的數據,分析題目所給的80個變量,預測出測試集中1460條樣本的房價。
4.選題數據
賽題數據由以下兩部分構成:
訓練集包含1460條樣本,81個屬性:
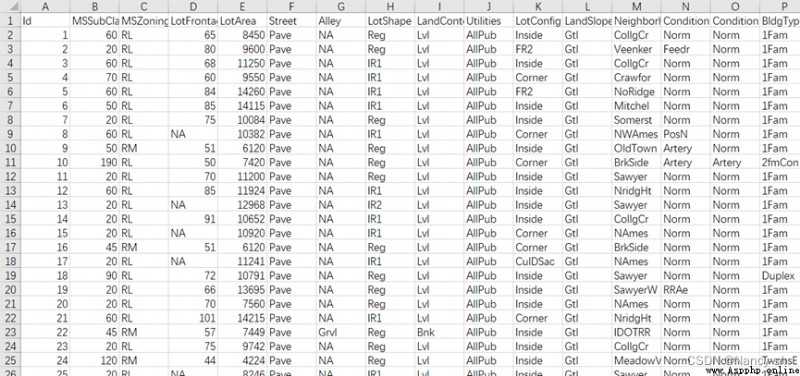
測試集包含1460條樣本,80個屬性:
一直以來,房價問題是社會各界討論較多的話題,已有諸多學者從不同視角探索了影響房價的因素,並取得了一定研究成果。同時也在嘗試探索如何構建更精確的模型去預測房價。
近年來,國內外大多學者以宏觀或微觀角度為切入點,展開對房價影響因素的研究。如:
在研究方法上大部分學者都使用了 Lasso回歸、隨機森林回歸、支持向量回歸、XGBoost 回歸、多元線性回歸等單一模型,使用的模型較為廣泛,也有部分研究所選取的特征維數有限,並不能全面反映影響房屋價格的制約因素,能夠分析處理的特征維數較少,並不能全面挖掘特征因素與房價之間的影響關系。
所以本文在對房屋價格的研究過程中,以Kaggle平台的房屋價格作為數據庫,建立影響房屋價格的多維因素與房屋價格之間的聯系,我選取了較多的變量組合對同一預測指標進行對比分析和模型評價,將多種算法融合使用並構建組合模型去預測房屋的價格,通過模型評價指標,選擇最優的預測模型,以為政府部門、中介機構和購房者等提供合理的對策建議。
3.1 EDA(探索性數據分析)
這是一個功能強大的庫,使用這個庫只需要一行代碼便可以得到數據EDA報告,生成的報告可以有效幫助我們熟悉數據集、了解數據集。報告中會有缺失值信息、重復值信息、每個變量的信息等內容,這些信息以便更好對數據進行的分析、處理。
3.2 異常值的處理
看到數據後,我首先考慮的是數據中異常值信息,對數據中異常值進行處理。在處理數據異常值這裡,我根據變量的相關矩陣圖選取了三個變量:建造年份、房屋的面積和地下室面積,構建了三個圖像:YearBuilt與SalePrice之間的箱型圖、GrLivArea與SalePrice之間的散點圖、TotalBsmSF與SalePrice之間的散點圖,通過得到的圖對異常的數據進行分析處理。
3.3合並訓練集和測試集
接下來便是把訓練集和測試集數據進行合並,以便後面方便對數據進行分析、處理。
3.4 刪除多余的列
把數據進行合並後,我發現Id列和索引值都是以1為間隔,升序排列的數值,所以我把Id列給刪除了,刪除Id列後,方便後面對數據的處理。
3.5 缺失值的處理
在開始的時候,有考慮過要不要把有缺失的數據給刪除,但缺失值的數量還是挺多的,如果把缺失的數據都刪除的話,信息丟失會很大,所以還是選擇保留。
在對缺失數據進行填充時,我對部分字符類型的變量使用眾數進行填充,部分字符類型的變量用“None”進行填充,對數值類型的變量使用0進行填充。
3.6 數據類型轉換
從變量的數據類型信息圖中可以看到,有很多變量是字符串類型的,但計算機對字符串的特征是無能為力的,所以需要將字符串特征映射成數值類型。
3.7 數據對數化處理
由於一些變量不符合正態分布,對數據進行對數化處理可以使那些不完全具有正態分布的特征更符合正態分布,特征的正態性對回歸模型的擬合效果起到非常重要的作用。所以對數據進行對數轉換,不僅可以使特征正態化,而且也可以減少異常值對變量的影響。
3.8 得到數據特征的重要性並做成DataFrame形式
特征的選擇是非常關鍵的一步,好的特征選擇能夠提升模型的性能,更能幫助我們理解數據的特點、底層結構,這對進一步改善模型、算法都有著重要作用。特征沒有選擇好,對比賽結果也會產生不小的影響。這裡我選擇使用Lasoo回歸來得到數據特征的重要性數值,並將變量名和特征的重要性作為DataFrame的形式,方便後面進行可視化處理。
3.9 對數據特征重要性數值進行可視化
得到了變量特征的重要性後,由於得到的是一些數值,數字太抽象,圖表會更直觀、可以突出數據中的關注點,所以這裡對上面得到的數據進行可視化處理。
3.10 對數據進行合並
根據上面得到的數據特征重要性圖,對數據特征進行選擇與重做,對題目所給的變量,根據特征重要性值對特征進行加減乘除等運算,對部分數據進行合並。
3.11 取出處理後的測試集數據
將數據進行處理後,把測試集的數據取出,以便後面使用機器學習相關模型對數據進行預測。
3.12 使用機器學習模型對數據進行預測
對數據處理完成後,使用機器學習算法對的處理後的測試集進行預測,得到測試結果。
4.1 EDA(探索性數據分析)
首先我根據題目所給的數據,使用了pandas_profiling庫,生成了數據的EDA(探索性數據分析)報告:
從Overview部分可以看到,數據中沒有重復數據,不需要處理重復數據;但空值占比還是不小的,有5.9%,需要對空值進行處理。
4.2異常值處理
根據EDA報告中得到的變量相關矩陣圖:
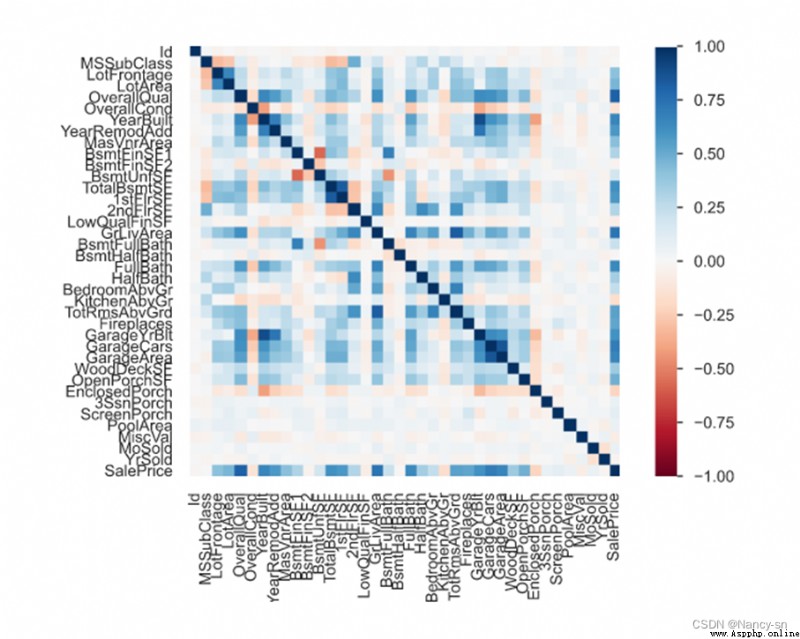
從這個相關矩陣圖的最後一列數據可以看出,SalePrice與其他變量的關系,從圖中可以看出房屋的面積(GrLivArea)、地下室面積(GrLivArea)、建造年份(YearBuilt)等變量與SalePrice的顏色較深,也有其他一些顏色較深的變量。顏色越深說明其相關性越大。我認為房屋的面積(GrLivArea)、地下室面積(TotalBsmSF)、建造年份(YearBuilt)與房屋的價格(SalePrice)關系還是挺大的,一般來講,面積越大房子的價格會越貴,房齡越久房子的價格也會較便宜。所以我構建了三個圖像:YearBuilt與SalePrice之間的箱型圖、GrLivArea與SalePrice之間的散點圖、TotalBsmSF與SalePrice之間的散點圖。
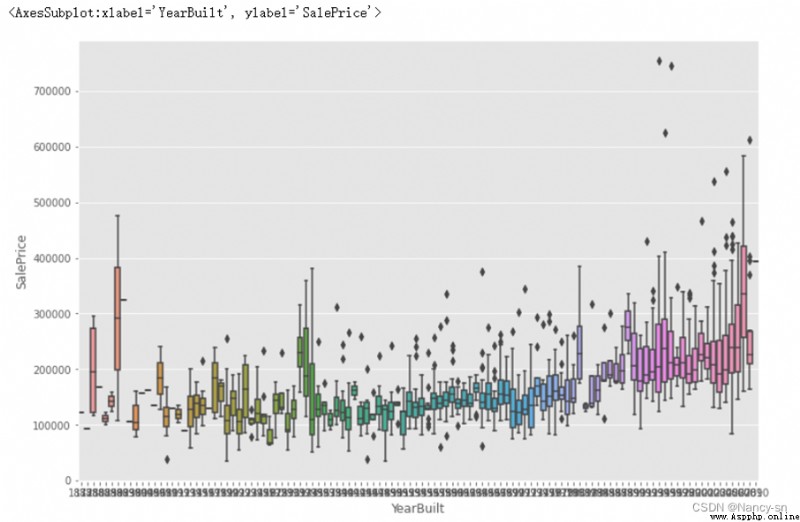
從這個箱型圖可以看出:房屋建造年份和銷售價格並沒有很強的趨勢關系, 但根據我平時的常識來說,我覺得他們兩者之間還是有一定的關系,所以在後面處理時我還是將它重點考慮了。
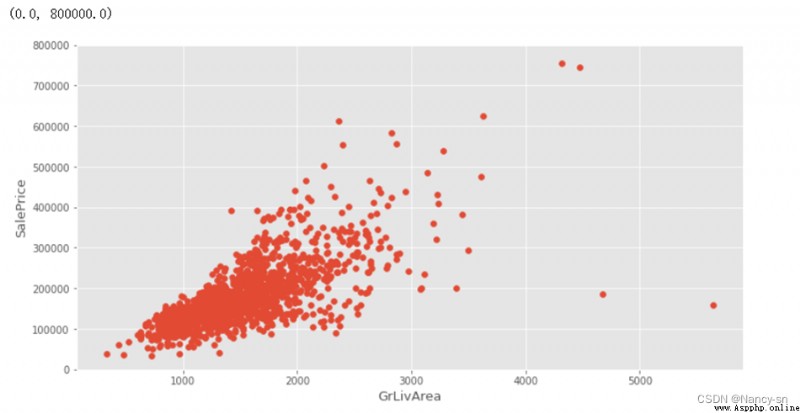
根據得到的散點圖,可以看出房屋面積和房屋的價格存在著一定的線性關系,但也有少量的數據偏離線性關系,由於數據只有兩個,所以這裡我把太偏離線性的那兩個數據使用drop()函數刪除掉了,刪除後得到的散點圖如下:
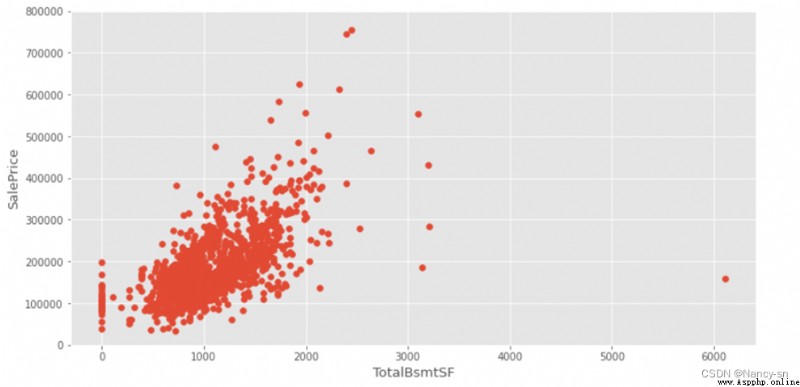
根據得到的散點圖,可以看出地下室面積和房屋的價格存在著一定的線性關系,但也有數據偏離線性關系,所以這裡我把右邊太偏離線性的那個數據使用drop()函數刪除掉了,刪除後得到的散點圖如下:
4.3合並訓練集和測試集
處理好了訓練集的異常值後,我把訓練集和測試集數據使用concat()函數進行合並,以便後面方便對數據進行分析處理。
4.4刪除多余的列
把數據進行合並後,我發現Id列和索引值都是以1 為間隔升序的數值:
所以我把Id列給刪除,刪除Id列後,方便後面對數據的處理,刪除後:
4.5缺失值處理
在得到的EDA報告中可以看出訓練集中缺失值占比不少:
從圖中可以看出,空白部分代表的是缺失值,部分變量缺失值占比很大。
把數據合並後,我使用了isnull()和sum()函數來統計數據中缺失值的個數,並使用sort_values()函數對缺失數據從低到高進行排序:
由於存在空值的變量較多,我使用了info()方法查看80個變量的信息:
從得到的信息可以看出,有些缺失數據時字符串類型的,有些是數值類型的,所以在使用fillna()函數對缺失值進行填充時,我先對字符串類型的變量進行分析,決定對這些變量:MSZoning (一般分區分類)、BsmtFullBath (地下室全浴室)、BsmtHalfBath (地下室半浴室)、KitchenQual (廚房質量)、SaleType (銷售類型)、Exterior1st (房屋外牆)、Exterior2nd (房屋的外部覆蓋物)、Utilities(公用設施)、Functional(家庭功能評級)、Electrical(電氣設備)使用眾數進行填充;對數值類型的變量用0進行填充;對剩下的字符型變量使用“None”進行填充:
填充完成後,查看是否有還有未填充的數據:
發現只有房屋價格一列存在缺失,故把目前把空值填充完成。
4.6數據類型轉換
從上面得到數據類型信息圖中可以看到,有很多變量是字符串類型的,但計算機對字符串的特征是無能為力的,所以需要將字符串特征映射成數值類型。我使用了fit_transform()函數對數據進行轉換,fit_transform()是fit()和transform()的組合,這個函數先對部分數據進行擬合fit,然後根據具體轉換的目的,對該數據進行轉換,從而實現數據的標准化:
可以看到轉換後字符類型的值轉換為數值類型的值。
4.7數據對數化處理
由於一些變量不符合正態分布,對數據進行對數化處理可以使那些不完全具有正態分布的特征更符合正態分布,特征的正態性對回歸模型的擬合效果會起到非常重要的作用。所以我對部分數據進行對數轉換:
SalePrice(房屋價格):
處理前:
處理後:
由於變量數較多,所以我篩選了部分變量,選擇了skew(偏差)大於0.75的變量,共有12個,對這12個變量進行了轉換,下面是前後對比圖:
4.8 得到數據特征的重要性並做成DataFrame形式
特征的選擇是非常關鍵的一步,好的特征選擇能夠提升模型的性能,更能幫助我們理解數據的特點、底層結構,這對進一步改善模型、算法都有著重要作用。特征沒有選擇好,對比賽結果也會產生不小的影響。在得到數據特征的重要性時,我考慮到了Lasso回歸和Ridge回歸,但由於Lasso回歸中求得的值會有更少的非零分量,所以這裡我選擇使用Lasoo回歸來得到數據特征的重要性數值:
得到後,將變量名和特征的重要性作為DataFrame的形式,方便後面進行可視化處理:
4.9 對數據特征重要性數值進行可視化
得到了變量特征的重要性後,由於得到的是一些數值,數字太抽象,圖表會更直觀、可以突出數據中的關注點,所以這裡對上面得到的數據進行可視化處理:
4.10 對數據進行合並
根據上面得到的數據特征重要性圖,對數據特征進行選擇與重做,對題目所給的變量,根據特征重要性值對特征進行加減乘除等運算,對部分數據進行合並,我構造了一個轉換函數transform():
下面是我構建這個轉換函數的想法:
以上19條便是我根據數據特征重要性圖和自己的想法來對數據進行特征的選擇和重做。
4.11 取出處理後的測試集數據
將數據進行處理後,把測試集的數據取出,以便後面使用機器學習相關模型對數據進行預測:
4.12使用機器學習模型對數據進行預測
對數據處理完成後,使用機器學習算法對的處理後的測試集進行預測,得到測試結果:
①首先構建了模型評估方法:我選擇使用交叉驗證法。使用交叉驗證法,每個樣例都會剛好在測試集中出現一次,對數據的使用更加高效,更多的數據可以得到更為精確的模型。
②接下來使用網格搜索:網格搜索是一種調參手段,可以實現自動調參並返回最佳的參數組合。
③接下來就是對模型的選擇:我使用了6個模型,這些模型之間有一些相同的點,但各個模型都有各自的優點所在:
Lasso回歸:該方法是以縮小變量集(降階)為思想的壓縮估計方法。
嶺回歸:在不拋棄任何一個變量的情況下,縮小了回歸系數,使得模型相對而言會比較穩定。
支持向量回歸:這是一種“寬容的回歸模型”,在線性函數兩側制造了一個“間隔帶”,對於所有落入到間隔帶內的樣本,都不計算損失。
核嶺回歸:這個回歸會產生近似形式的解,在中度規模的數據時效率高。
彈性網絡:彈性網絡它永遠可以產生有效解,它不會產生交叉的路徑。
貝葉斯回歸:貝葉斯回歸易於訓練,可以用於在預估階段的參數正則化,通過手動調節數據值來實現。
④最優參數的選取:使用上面所定義的模型評估方法對選擇的模型進行評估,得出每個模型的最優參數如下:
⑤模型的集成:得到了選取模型的最優參數後,對模型進行集成,我使用了兩個方法對模型進行集成:
加權平均法:使用上面所選取的最優參數,對每個模型分配不同比例的權重,求出交叉驗證的均值:
模型的堆疊:定義了模型堆疊函數(先把數據進行了5折劃分,把數據集分成了5份,然後使用模型進行擬合),後面便可以根據這個函數對數據進行預測。
⑥模型訓練、預測結果:把處理後得到的測試集數據放到堆疊的模型中進行計算,得到結果,並將結果保存到csv文件中:
4.13 有意義的方面
我認為數據處理的有意義方面有:
將特征進行合並:
等等。。。
以上便是我列舉的10個較有意義的數據處理。
房價預測這個題目看似簡單,只需要得到1460個樣本數據的房價即可。但實質上也有難度,它的屬性有80個,缺失值也很多,在數據預處理這裡我也更改了多次。
特別是在對數據特征進行選擇和重做時,我也是有點不知道該怎樣處理,最後我決定構建出數據的特征重要性圖,根據數據特征重要性圖中的數據對參數進行選擇,再把屬性進行合並、分拆等操作。
在選擇模型的時候,先是對模型的選擇,再對模型進行集成、堆疊,通過更改每個模型的權重,最後得到了一個較好的結果。
通過這次的課程設計有學到很多,收獲很大,對缺失值的處理、數據的合並、數據可視化處理、對數據特征的選擇等。我也明白了數據處理的重要性,對數據的分析也很重要,使用不同的方法得出的結果可能會有很大的差別。這次實驗,我對Python有了更好的了解,它擁有著巨大且活躍的科學計算社區,它有著pandas、sklearn等功能強大的庫和工具,這次的課程設計讓我深刻體會到了一些庫和工具的強大。
但我覺得我在數據預處理部分還是處理的不夠好,在填充空值時,只使用了均值、眾數等進行填充,我認為這裡還可以使用標准偏差值進行填充,在這一塊,我還得繼續學習;在變量特征的選取及合並方面,我認為還可以考慮更綜合、更全面,構建出不一樣的新特征,進一步加強預測精度,不斷改進,最後拿到更好的成績。
競賽結果:
 Python+pygame realizes the brick playing game -- you can define the bullet speed, skip levels, and increase levels
Python+pygame realizes the brick playing game -- you can define the bullet speed, skip levels, and increase levels
python+pygame Realize the bric
 Self learning Python to find complementary DNA sequences of known DNA templates
Self learning Python to find complementary DNA sequences of known DNA templates
Catalog DNA Sequence Briefly