Preface
One 、User-Agent
Two 、 Send a request
3、 ... and 、 Parsing data
Four 、 structure ip Agent pool , testing ip Is it available
5、 ... and 、 Complete code
summary
PrefaceWhen using reptiles , Many websites have certain anti climbing measures , Even when crawling large amounts of data or frequently visiting the website many times, you may face ip banned , So at this time, we can usually find some agents ip To continue the crawler test .
Let's start with a brief introduction to crawling free agents ip To build your own agent ip pool : This climb is free ip The agent's website :http://www.ip3366.net/free/
Tips : The following is the main body of this article , The following cases can be used for reference
One 、User-AgentWhen sending a request , Usually do a simple reverse climb . You can use fake_useragent Module to set a request header , Used to disguise as a browser , You can do either of the following .
from fake_useragent import UserAgentheaders = { # 'User-Agent': UserAgent().random # The request header of common browsers is disguised ( Such as : firefox , Google ) 'User-Agent': UserAgent().Chrome # Google browser }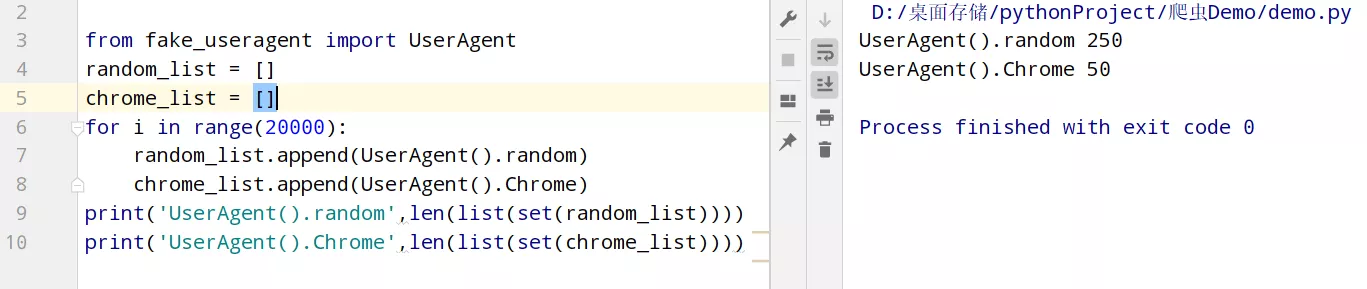
response = requests.get(url='http://www.ip3366.net/free/', headers=request_header()) # text = response.text.encode('ISO-8859-1') # print(text.decode('gbk')) 3、 ... and 、 Parsing data We just need to parse out ip、port that will do .
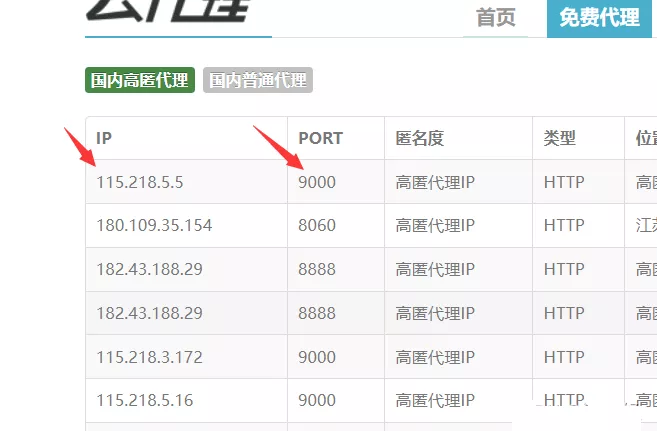
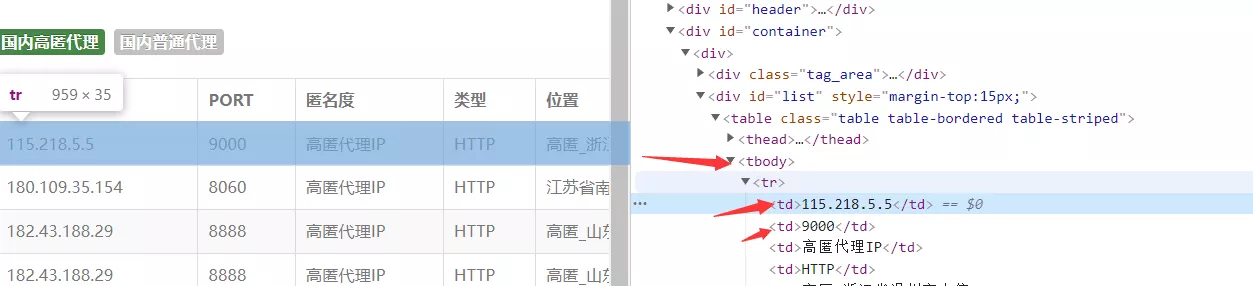
Use xpath analysis ( I like to use )( Of course, there are many parsing methods , Such as : Regular ,css Selectors ,BeautifulSoup wait ).
# Use xpath analysis , Extract the data ip, port html = etree.HTML(response.text) tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr') for td in tr_list: ip_ = td.xpath('./td[1]/text()')[0] #ip port_ = td.xpath('./td[2]/text()')[0] # port proxy = ip_ + ':' + port_ #115.218.5.5:9000 Four 、 structure ip Agent pool , testing ip Is it available # Build agents ipproxy = ip + ':' + portproxies = { "http": "http://" + proxy, "https": "http://" + proxy, # "http": proxy, # "https": proxy, } try: response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) # Set up timeout, Wait for response 1s response.close() if response.status_code == 200: print(proxy, '\033[31m You can use \033[0m') else: print(proxy, ' Unavailable ') except: print(proxy,' Request exception ') 5、 ... and 、 Complete code import requests # The import module from lxml import etreefrom fake_useragent import UserAgent# Simple reverse climbing , Set a request header to disguise as a browser def request_header(): headers = { # 'User-Agent': UserAgent().random # The request header of common browsers is disguised ( Such as : firefox , Google ) 'User-Agent': UserAgent().Chrome # Google browser } return headers''' Create two lists to hold the agent ip'''all_ip_list = [] # Used to store... Captured from the website ipusable_ip_list = [] # It is used to store the products that have passed the test ip Can I use # Send a request , Get the response def send_request(): # Crawling 7 page , You can modify for i in range(1,8): print(f' We're grabbing number one {i} page ……') response = requests.get(url=f'http://www.ip3366.net/free/?page={i}', headers=request_header()) text = response.text.encode('ISO-8859-1') # print(text.decode('gbk')) # Use xpath analysis , Extract the data ip, port html = etree.HTML(text) tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr') for td in tr_list: ip_ = td.xpath('./td[1]/text()')[0] #ip port_ = td.xpath('./td[2]/text()')[0] # port proxy = ip_ + ':' + port_ #115.218.5.5:9000 all_ip_list.append(proxy) test_ip(proxy) # Start detecting the acquired ip Whether it can be used print(' Grab complete !') print(f' I caught it ip The number is :{len(all_ip_list)}') print(f' serviceable ip The number is :{len(usable_ip_list)}') print(' There were :\n', usable_ip_list)# testing ip Whether it can be used def test_ip(proxy): # Build agents ip proxies = { "http": "http://" + proxy, "https": "http://" + proxy, # "http": proxy, # "https": proxy, } try: response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) # Set up timeout, Wait for response 1s response.close() if response.status_code == 200: usable_ip_list.append(proxy) print(proxy, '\033[31m You can use \033[0m') else: print(proxy, ' Unavailable ') except: print(proxy,' Request exception ')if __name__ == '__main__': send_request() summary This is about Python Crawler implementation build agent ip This is the end of Chi's article , More about Python agent ip Please search the previous articles of SDN or continue to browse the related articles below. I hope you will support SDN more in the future !