notes : Some pictures may not be uploaded successfully , It can be downloaded from the document
link :Python Course design of data processing - Housing price forecasts - Machine learning document resources -CSDN download
Course design report
Course name
Python Course design of data processing
Project name
Housing price forecasts
Catalog
One . Background .. 3
1. Background of the topic ... 3
2. Research significance ... 3
3. Title Description ... 3
4. Topic data ... 3
Two . Current research status ... 4
3、 ... and . Technical means and methods used ... 5
3.1 EDA( Exploratory data analysis )... 5
3.2 Handling of outliers .. 5
3.3 Combine training and test sets ... 6
3.4 Delete extra columns .. 6
3.5 Processing of missing values .. 6
3.6 Data type conversion .. 6
3.7 Logarithmic data processing ... 6
3.8 Get the importance of data characteristics and make DataFrame form ... 6
3.9 Visualize the value of data feature importance .. 6
3.10 Merge the data ... 7
3.11 Take out the processed test set data ... 7
3.12 Use machine learning models to predict data .. 7
Four . Data analysis .. 7
4.1 EDA( Exploratory data analysis )... 7
4.2 Exception handling .. 7
4.3 Combine training and test sets ... 11
4.4 Delete extra columns ... 11
4.5 Missing value processing .. 11
4.6 Data type conversion ... 14
4.7 Logarithmic data processing .. 14
4.8 Get the importance of data characteristics and make DataFrame form ... 16
4.9 Visualize the value of data feature importance .. 17
4.10 Merge the data ... 18
4.11 Take out the processed test set data ... 20
4.12 Use machine learning models to predict data ... 20
4.13 Meaningful aspects ... 21
5、 ... and . Project summary .. 22
6、 ... and . reference .. 23
1. Background of the topic
With the continuous development of economy , The real estate industry has become a pillar industry , Housing prices not only directly affect the living standards of residents , It also indirectly affects the sustainability of the national economy 、 health 、 Steady development , Housing price has become a hot issue concerning people's livelihood . Whether the house price is reasonable , It is impossible to answer these questions only through superficial observation and imagination , Only through scientific research methods can we draw reasonable conclusions . House prices are restricted and affected by many factors , such as : Location 、 The materials used to build the house 、 Residential style 、 Type of residence 、 Is there a basement 、 Is there a garage 、 The quality of the fence 、 Functions of the family, etc , Will have an impact on house prices . Therefore, the characteristic factors to be selected should be comprehensive 、 diversity , Select indicators closely related to house prices , Analyze the data 、 Handle , Using machine learning algorithm to study its impact on the price , And build a stable 、 Price forecasting model with small error , More accurately predict the final price of the house , So as to provide macro-control for relevant government departments 、 Real estate developers and sellers or buyers provide scientific pricing and valuation basis , Better promote the stable development of the housing market .
2. Research significance
At present, some people have made many achievements in the study of housing prices , Most people are mainly from politics 、 economic 、 policy 、 The housing price is analyzed at the macro level of population , There are also a few scholars who have carried out research on micro factors such as building hardware facilities , It has also achieved good prediction results , But at present, there are still relatively few in this regard . In view of this , I will use the game data , Building feature variable sets , Select representative characteristic variables , Based on the existing data , Process the data , Using machine learning algorithm to analyze house price problem , Select the prediction model and use it to predict the house price of the test set .
Besides , Whether for regulators or consumers , Is it a real estate intermediary or a real estate developer , Only a deep understanding of the real estate trading market , To carry out reasonable supervision and planning ; Efficient promotion of housing supply , Scientific pricing on the premise of meeting the needs of property buyers , Improve the market competitive advantage ; Effective risk aversion , Reduce unnecessary losses, etc . Therefore, predicting housing prices can provide people with more choices in housing purchase , It has a certain reference function .
3. Title Description
Buyers describe their dream house , They may not start from the height of the basement ceiling or the distance from east to west to the railway . But these data prove , The factors influencing the price negotiation are far greater than the number of bedrooms or white fences . The variables given in the title describe almost all aspects of housing in Ames, Iowa . According to the data of the training set and the test set given by the topic , Analyze the questions given 80 A variable , Predict the test set 1460 The house price of the sample .
4. Topic data
The contest data consists of the following two parts :
The training set contains 1460 Samples ,81 Attributes :
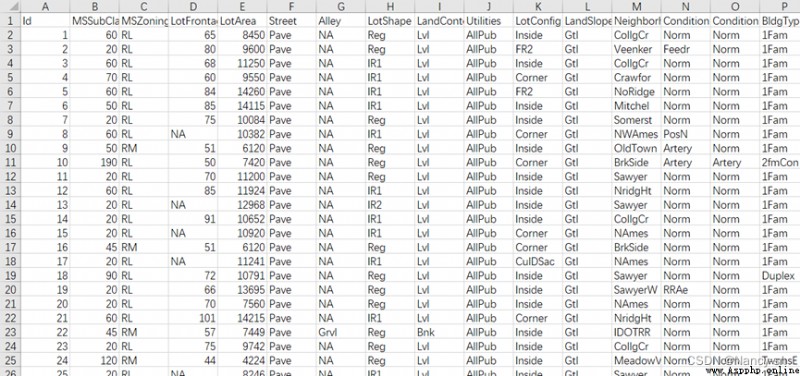
The test set contains 1460 Samples ,80 Attributes :
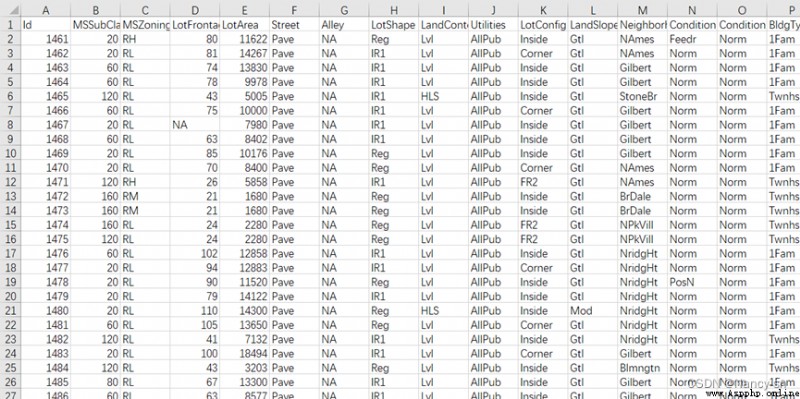
all the time , The problem of housing price is a topic discussed by all walks of life , Many scholars have explored the factors that affect house prices from different perspectives , And achieved certain research results . At the same time, we are trying to explore how to build a more accurate model to predict house prices .
In recent years , Most scholars at home and abroad take the macro or micro perspective as the starting point , Research on the influencing factors of housing prices . Such as :
Most scholars have used Lasso Return to 、 Random forest regression 、 Support vector regression 、XGBoost Return to 、 Multiple linear regression and other single models , The models are widely used , There are also some studies that have limited feature dimensions , It does not fully reflect the constraints affecting housing prices , The feature dimension that can be analyzed and processed is less , We can not fully explore the relationship between characteristic factors and house prices .
Therefore, in the process of studying the housing price , With Kaggle The house price of the platform is used as the database , Establish the relationship between the multidimensional factors that affect the housing price and the housing price , I have selected many variable combinations to conduct comparative analysis and model evaluation on the same prediction index , Combine various algorithms and build a combination model to predict the house price , Through the model evaluation index , Choose the best prediction model , Think the government department 、 Intermediary agencies and property buyers provide reasonable countermeasures and suggestions .
3.1 EDA( Exploratory data analysis )
This is a powerful library , Using this library requires only one line of code to get the data EDA The report , The generated report can effectively help us to familiarize ourselves with data sets 、 Learn about datasets . There will be missing value information in the report 、 Duplicate value information 、 Information of each variable, etc , This information is useful for better analysis of data 、 Handle .
3.2 Handling of outliers
After seeing the data , My first consideration is outlier information in the data , Handle outliers in data . In dealing with data outliers , I selected three variables according to the correlation matrix of variables : Year of construction 、 The area of the house and the area of the basement , Three images are constructed :YearBuilt And SalePrice Box diagram between 、GrLivArea And SalePrice Scatter diagram between 、TotalBsmSF And SalePrice Scatter diagram between , Analyze and process the abnormal data through the obtained graph .
3.3 Combine training and test sets
The next step is to merge the training set and test set data , So as to facilitate the analysis of data later 、 Handle .
3.4 Delete extra columns
After merging the data , I find Id Both column and index values are 1 interval , Values in ascending order , So I put Id Column has been deleted , Delete Id After column , It is convenient to deal with the data later .
3.5 Processing of missing values
At the beginning , I have considered whether to delete the missing data , But there are still a lot of missing values , If you delete all the missing data , The loss of information can be significant , So choose to keep .
When populating missing data , I use... For variables of some character types The number of Fill in , Variables of some character types use “None” Fill in , Use... For variables of numeric type 0 Fill in .
3.6 Data type conversion
From the data type information diagram of the variable, you can see , There are many variables of string type , But the computer can do nothing about the character of the string , So you need to map string features to numeric types .
3.7 Logarithmic data processing
Because some variables do not conform to the normal distribution , Logarithmic processing of data can make those that do not have complete Normal distribution Is more in line with the normal distribution , The normality of features plays a very important role in the fitting effect of regression model . So log transform the data , It can not only normalize the characteristics , It can also reduce the influence of outliers on variables .
3.8 Get the importance of data characteristics and make DataFrame form
Feature selection is a key step , Good feature selection can improve the performance of the model , It can help us to understand the characteristics of data 、 The underlying structure , This will further improve the model 、 Algorithms play an important role . Features are not selected well , It will also have a great impact on the result of the game . Here I choose to use Lasoo Regression is used to get the importance value of data characteristics , The importance of variable names and characteristics is taken as DataFrame In the form of , It is convenient for later visual processing .
3.9 Visualize the value of data feature importance
After getting the importance of variable characteristics , Because we get some numerical values , Numbers are too abstract , Charts will be more intuitive 、 Can highlight concerns in the data , Therefore, the above data is visualized here .
3.10 Merge the data
According to the data feature importance diagram obtained above , Select and redo data features , The variables given to the topic , Add, subtract, multiply and divide features according to their importance value , Merge some data .
3.11 Take out the processed test set data
After processing the data , Take out the data of the test set , In order to use machine learning related models to predict the data later .
3.12 Use machine learning models to predict data
After data processing , Use machine learning algorithm to predict the processed test set , Get test results .
4.1 EDA( Exploratory data analysis )
First of all, according to the data given by the title , Used pandas_profiling library , Generated data EDA( Exploratory data analysis ) The report :
from Overview Part of it can be seen , There is no duplicate data in the data , No need to deal with duplicate data ; However, the proportion of null values is not small , Yes 5.9%, Null values need to be processed .
4.2 Exception handling
according to EDA The variable correlation matrix obtained in the report :

From the last column of the correlation matrix, we can see ,SalePrice Relationship with other variables , You can see the area of the house from the picture (GrLivArea)、 Basement area (GrLivArea)、 Year of construction (YearBuilt) Equal variables and SalePrice The color of is darker , There are also other darker variables . The darker the color, the greater the correlation . I think the size of the house (GrLivArea)、 Basement area (TotalBsmSF)、 Year of construction (YearBuilt) And the price of the house (SalePrice) The relationship is still very big , In general , The larger the area, the more expensive the house will be , The older the house, the cheaper it will be . So I built three images :YearBuilt And SalePrice Box diagram between 、GrLivArea And SalePrice Scatter diagram between 、TotalBsmSF And SalePrice Scatter diagram between .
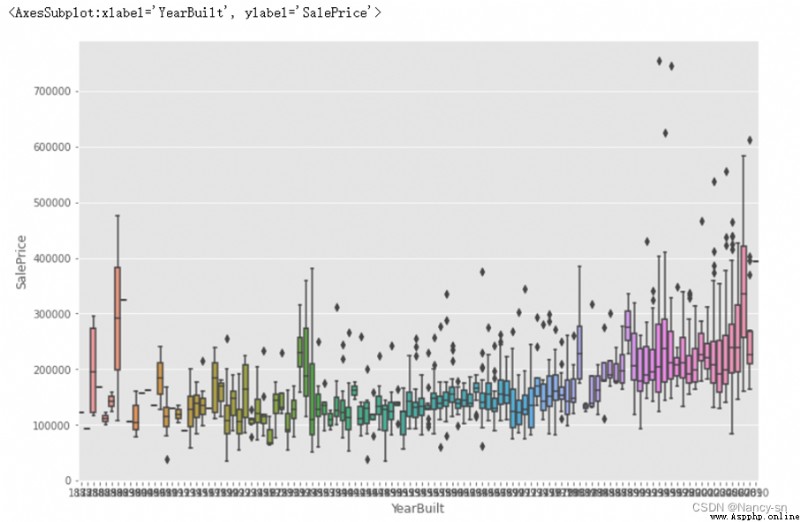
It can be seen from the box diagram that : There is no strong trend relationship between the year of building and the sales price , But according to my common sense , I think there is a certain relationship between them , So I will focus on it in the later processing .
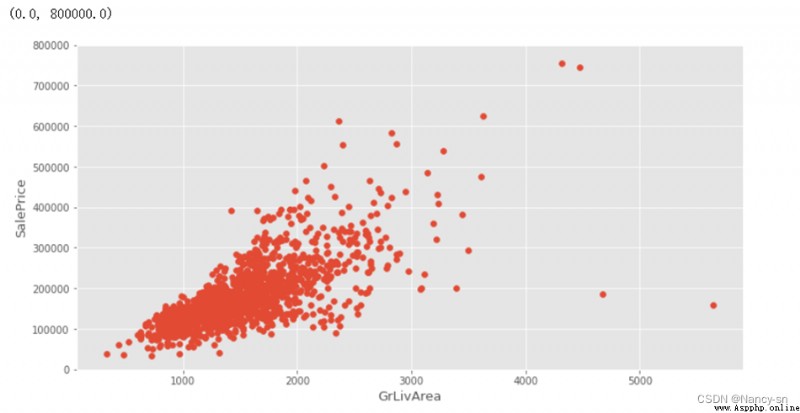
According to the obtained scatter diagram , It can be seen that there is a certain linear relationship between the house area and the house price , But there is also a small amount of data that deviates from the linear relationship , Because there are only two data , So here I use the two data that deviate too much from linearity drop() Function deleted , The scatter diagram obtained after deletion is as follows :
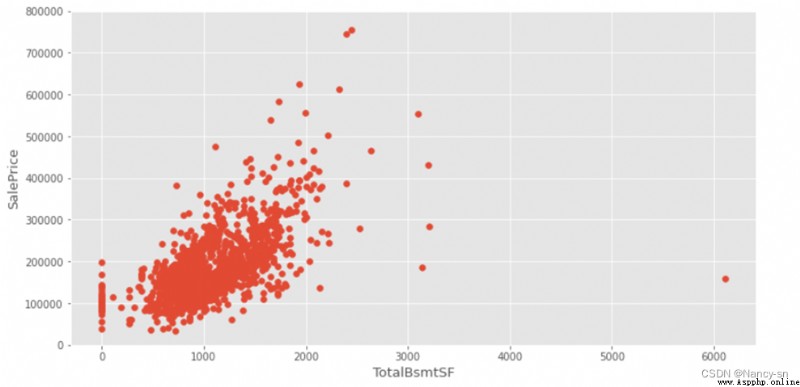
According to the obtained scatter diagram , It can be seen that there is a certain linear relationship between the basement area and the house price , But there are also data that deviate from the linear relationship , So here I use the data on the right that deviates too much from linearity drop() Function deleted , The scatter diagram obtained after deletion is as follows :
4.3 Combine training and test sets
After handling the outliers of the training set , I use training set and test set data concat() Function to merge , So as to facilitate the analysis and processing of data later .
4.4 Delete extra columns
After merging the data , I find Id Both column and index values are 1 Values in ascending order of intervals :
So I put Id List to delete , Delete Id After column , It is convenient to deal with the data later , After deleting :
4.5 Missing value processing
In getting EDA It can be seen from the report that there are many missing values in the training set :
As you can see from the diagram , Blanks represent missing values , The missing values of some variables account for a large proportion .
Merge the data , I use the isnull() and sum() Function to count the number of missing values in the data , And use sort_values() Function to sort missing data from low to high :
Because there are many variables with null values , I use the info() Method view 80 Information about variables :
From the information obtained, it can be seen that , String type when some data is missing , Some are numerical , So it's using fillna() Function to fill in missing values , I will first analyze variables of string type , Decide on these variables :MSZoning ( General zoning classification )、BsmtFullBath ( All bathrooms in the basement )、BsmtHalfBath ( Basement and half bathroom )、KitchenQual ( Kitchen quality )、SaleType ( Type of sale )、Exterior1st ( The outer wall of the house )、Exterior2nd ( The outer covering of a house )、Utilities( Utilities )、Functional( Family function rating )、Electrical( Electrical equipment ) Use The number of Fill in ; For variables of numeric type, use 0 Fill in ; Use... For the remaining character variables “None” Fill in :
After filling , Check if there is any unfilled data :
It is found that only the housing price column is missing , Therefore, the current null value is filled .
4.6 Data type conversion
From the above data type information diagram, you can see , There are many variables of string type , But the computer can do nothing about the character of the string , So you need to map string features to numeric types . I use the fit_transform() Function to convert data ,fit_transform() yes fit() and transform() The combination of , This function first fits part of the data fit, Then according to the specific purpose of the conversion , Convert the data , So as to realize the standardization of data :
You can see that after conversion, the value of character type is converted to the value of numeric type .
4.7 Logarithmic data processing
Because some variables do not conform to the normal distribution , Logarithmic processing of data can make those that do not have complete Normal distribution Is more in line with the normal distribution , The normality of features will play a very important role in the fitting effect of regression model . So I do logarithmic conversion on some data :
SalePrice( House price ):
Before processing :
After processing :
Due to the large number of variables , So I filtered some variables , I chose skew( deviation ) Greater than 0.75 The variable of , share 12 individual , For this 12 Variables were converted , The following is a comparison chart :
4.8 Get the importance of data characteristics and make DataFrame form
Feature selection is a key step , Good feature selection can improve the performance of the model , It can help us to understand the characteristics of data 、 The underlying structure , This will further improve the model 、 Algorithms play an important role . Features are not selected well , It will also have a great impact on the result of the game . When getting the importance of data characteristics , I thought about it Lasso Regression and Ridge Return to , But because of Lasso The value obtained in the regression will have fewer non-zero components , So here I choose to use Lasoo Regression is used to get the importance value of data characteristics :
When you get it , Consider the importance of variable names and characteristics as DataFrame In the form of , It is convenient for later visual processing :
4.9 Visualize the value of data feature importance
After getting the importance of variable characteristics , Because we get some numerical values , Numbers are too abstract , Charts will be more intuitive 、 Can highlight concerns in the data , Therefore, the above data is visualized here :
4.10 Merge the data
According to the data feature importance diagram obtained above , Select and redo data features , The variables given to the topic , Add, subtract, multiply and divide features according to their importance value , Merge some data , I constructed a transformation function transform():
Here is my idea for building this conversion function :
above 19 It means that I select and redo the features of the data according to the data feature importance diagram and my own ideas .
4.11 Take out the processed test set data
After processing the data , Take out the data of the test set , In order to use machine learning related models to predict the data later :
4.12 Use machine learning models to predict data
After data processing , Use machine learning algorithm to predict the processed test set , Get test results :
① Firstly, the model evaluation method is constructed : I choose to use cross validation . Using cross validation , Each sample will appear just once in the test set , More efficient use of data , More data can lead to more accurate models .
② Next, use the grid search : Grid search is a method of parameter adjustment , It can automatically adjust parameters and return the best parameter combination .
③ The next step is to select the model : I use the 6 A model , There are some similarities between these models , But each model has its own advantages :
Lasso Return to : The method is to reduce the variable set ( reduced order ) A compression estimation method for ideas .
Ridge return : Without discarding any variables , The regression coefficient is reduced , Make the model relatively stable .
Support vector regression : This is a kind of “ Tolerant regression model ”, On both sides of the linear function “ Septal band ”, For all samples falling into the spacer , Don't calculate the loss .
Nuclear ridge return : This regression produces an approximate solution , The data timeliness rate in the medium scale is high .
Elastic network : Elastic network it can always produce efficient solutions , It does not produce intersecting paths .
Bayes regression : Bayesian regression is easy to train , It can be used for parameter regularization in the estimation stage , This is achieved by manually adjusting the data values .
④ Selection of optimal parameters : Use the model evaluation method defined above to evaluate the selected model , The optimal parameters of each model are as follows :
⑤ Integration of models : After obtaining the optimal parameters of the selected model , Integrate the model , I used two methods to integrate the model :
Weighted average : Use the optimal parameters selected above , Assign different proportions of weights to each model , Find the mean value of cross validation :
Stacking of models : The model stacking function is defined ( First, the data is analyzed 5 Break down , Divide the data set into 5 Share , Then use the model to fit ), Then you can predict the data according to this function .
⑥ model training 、 Predicted results : Put the processed test set data into the stacked model for calculation , Get the results , And save the result to csv In file :
4.13 Meaningful aspects
I think data processing The meaningful aspects of :
Merge features :
wait ...
The above is my list 10 A more meaningful data processing .
The subject of house price forecast seems simple , Just need to get 1460 The house price of sample data is enough . But there are also difficulties in essence , Its properties are 80 individual , There are many missing values , In the data preprocessing, I also changed it many times .
Especially when selecting and redoing data features , I don't know how to deal with it , Finally, I decided to build a feature importance graph of the data , Select the parameters according to the data in the data feature importance diagram , Then merge the attributes 、 Separation and other operations .
When selecting a model , First, the choice of the model , Then integrate the model 、 The stack , By changing the weight of each model , Finally, a better result is obtained .
I have learned a lot through this course design , A great harvest , Dealing with missing values 、 Data consolidation 、 Data visualization 、 Selection of data features, etc . I also understand the importance of data processing , The analysis of data is also very important , The results obtained by different methods may vary greatly . This experiment , I am right. Python With a better understanding , It has a large and active scientific computing community , It has a pandas、sklearn And other powerful libraries and tools , This course design made me deeply realize the power of some libraries and tools .
But I think my data preprocessing is not good enough , When null values are filled , Only the mean value is used 、 Mode, etc , I think we can also use the standard deviation value for filling , Here it is , I have to continue my study ; In the selection and combination of variable characteristics , I think we can consider more comprehensive 、 More comprehensive , Build different new features , Further strengthen the prediction accuracy , Continuous improvement , Finally get better grades .
The result of the competition :