前言
創建索引
pd.Index
pd.IntervalIndex
pd.CategoricalIndex
pd.DatetimeIndex
pd.PeriodIndex
pd.TimedeltaIndex
讀取數據
set_index
reset_index
set_axis
操作行索引
操作列索引
rename
字典形式
函數形式
使用案例
按日統計總消費
按日、性別統計小費均值,消費總和
笨方法
總結
前言本文主要是介紹Pandas中行和列索引的4個函數操作:
set_index
reset_index
set_axis
rename
創建索引快速回顧下Pandas創建索引的常見方法:
pd.IndexIn [1]:
import pandas as pdimport numpy as npIn [2]:
# 指定類型和名稱s1 = pd.Index([1,2,3,4,5,6,7], dtype="int", name="Peter")s1Out[2]:
Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64', name='Peter')pd.IntervalIndex新的間隔索引 IntervalIndex 通常使用 interval_range()函數來進行構造,它使用的是數據或者數值區間,基本用法:
In [3]:
s2 = pd.interval_range(start=0, end=6, closed="left")s2Out[3]:
IntervalIndex([[0, 1), [1, 2), [2, 3), [3, 4), [4, 5), [5, 6)], closed='left', dtype='interval[int64]')pd.CategoricalIndexIn [4]:
s3 = pd.CategoricalIndex( # 待排序的數據 ["S","M","L","XS","M","L","S","M","L","XL"], # 指定分類順序 categories=["XS","S","M","L","XL"], # 排需 ordered=True, # 索引名字 name="category")s3Out[4]:
CategoricalIndex(['S', 'M', 'L', 'XS', 'M', 'L', 'S', 'M', 'L', 'XL'], categories=['XS', 'S', 'M', 'L', 'XL'], ordered=True, name='category', dtype='category')pd.DatetimeIndex以時間和日期作為索引,通過date_range函數來生成,具體例子為:
In [5]:
# 日期作為索引,D代表天s4 = pd.date_range("2022-01-01",periods=6, freq="D")s4Out[5]:
DatetimeIndex(['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04','2022-01-05', '2022-01-06'], dtype='datetime64[ns]', freq='D')pd.PeriodIndexpd.PeriodIndex是一個專門針對周期性數據的索引,方便針對具有一定周期的數據進行處理,具體用法如下:
In [6]:
s5 = pd.PeriodIndex(['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'], freq = '2H')s5Out[6]:
PeriodIndex(['2022-01-01 00:00', '2022-01-02 00:00', '2022-01-03 00:00','2022-01-04 00:00'], dtype='period[2H]', freq='2H')pd.TimedeltaIndexIn [7]:
data = pd.timedelta_range(start='1 day', end='3 days', freq='6H')dataOut[7]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00', '1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00', '2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'], dtype='timedelta64[ns]', freq='6H')In [8]:
s6 = pd.TimedeltaIndex(data)s6Out[8]:
TimedeltaIndex(['1 days 00:00:00', '1 days 06:00:00', '1 days 12:00:00', '1 days 18:00:00', '2 days 00:00:00', '2 days 06:00:00', '2 days 12:00:00', '2 days 18:00:00', '3 days 00:00:00'], dtype='timedelta64[ns]', freq='6H')讀取數據下面通過一份 簡單的數據來講解4個函數的使用。數據如下:
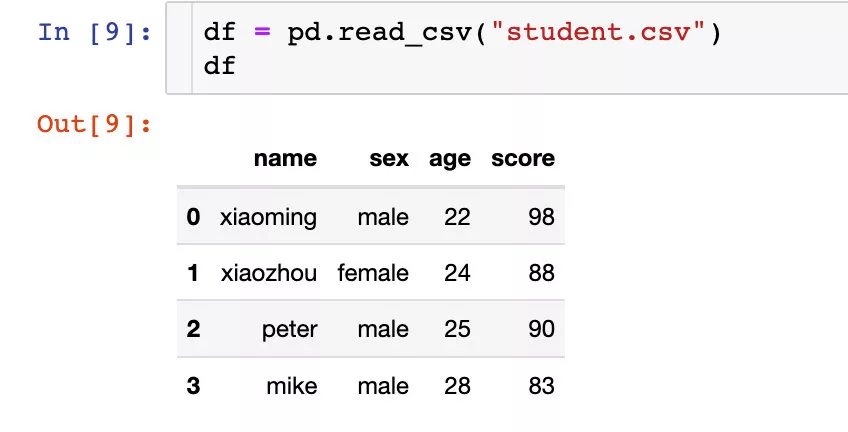
設置單層索引
In [10]:
# 設置單層索引df1 = df.set_index("name")df1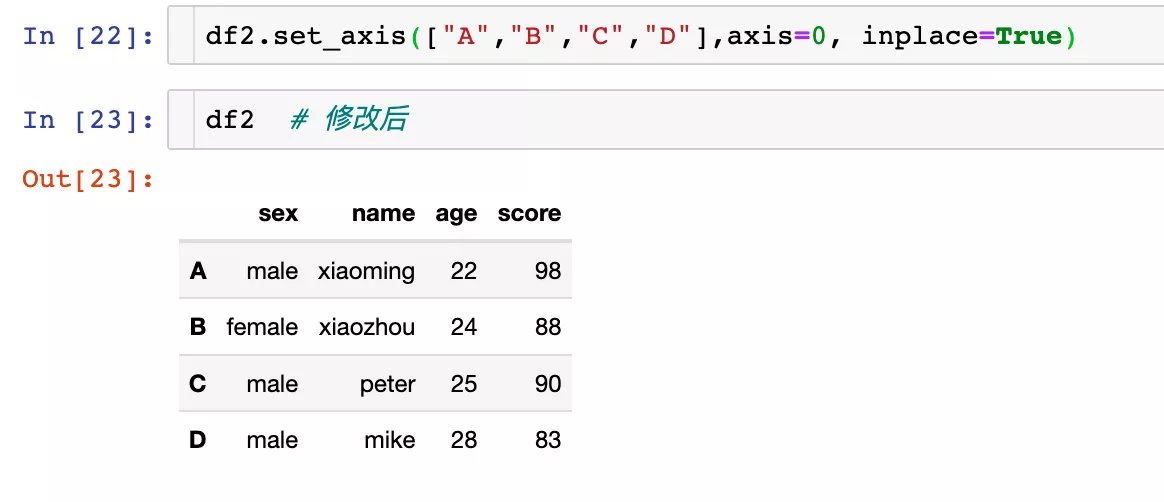
我們發現df1的索引已經變成了name字段的相關值。
下面是設置多層索引:
# 設置兩層索引df2 = df.set_index(["sex","name"])df2
對索引的重置:
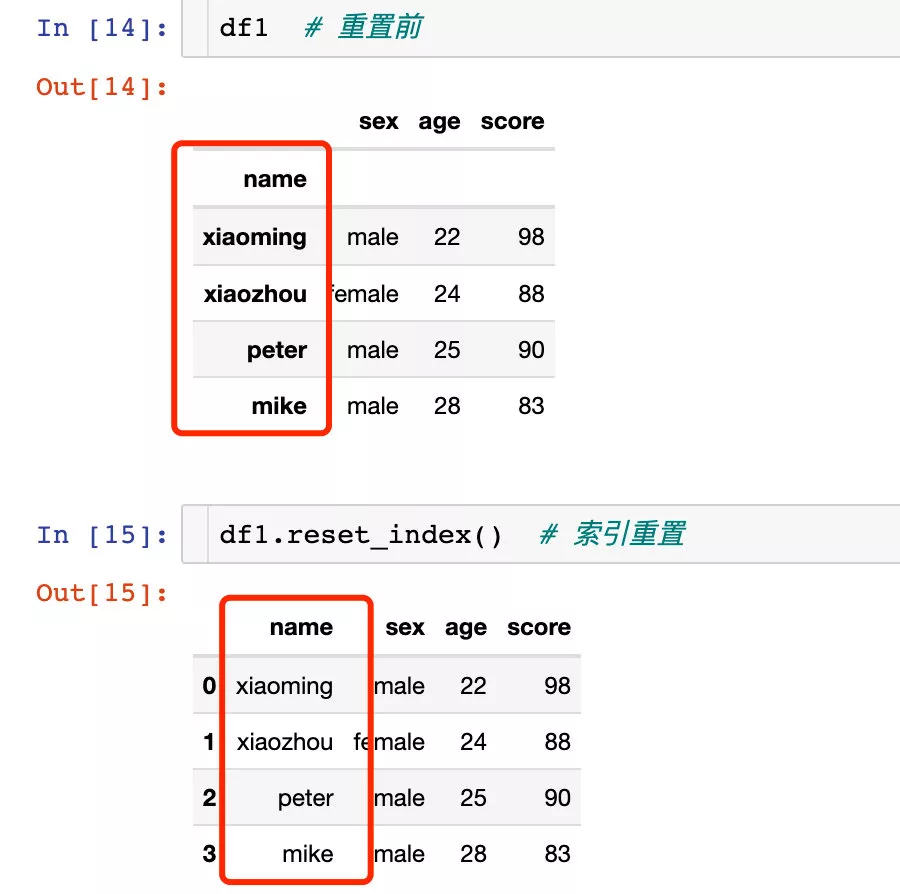
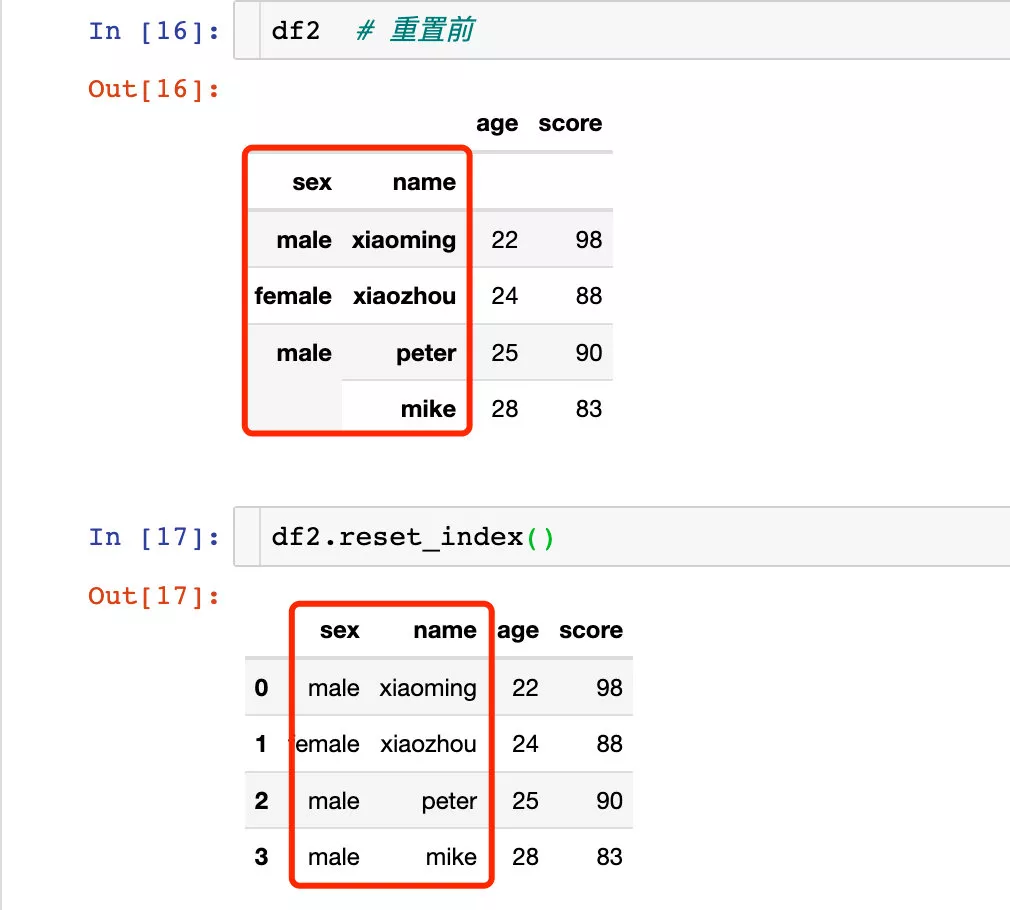
針對多層索引的重置:
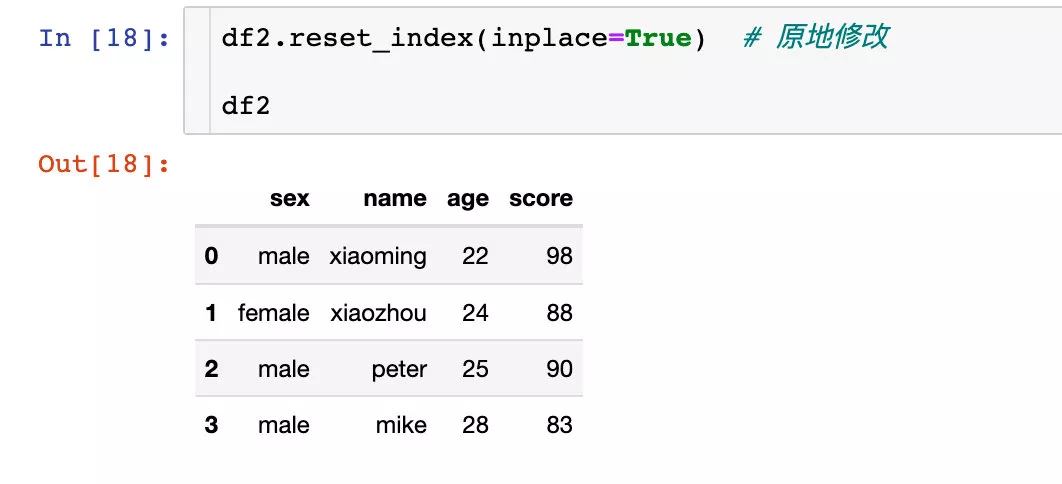
多層索引直接原地修改:
將指定的數據分配給所需要的軸axis。其中axis=0代表行方向,axis=1代表列方向。
兩種不同的寫法:
axis=0 等價於 axis="index"axis=1 等價於 axis="columns"操作行索引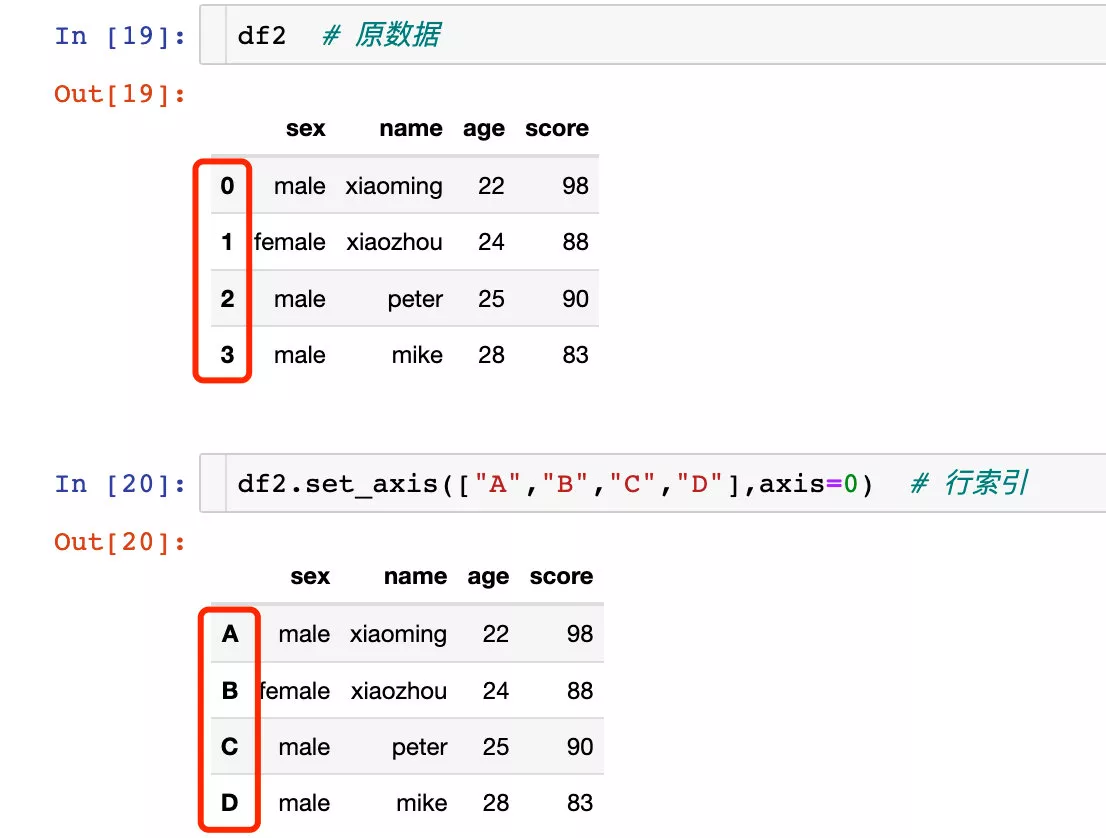
使用 index 效果相同:
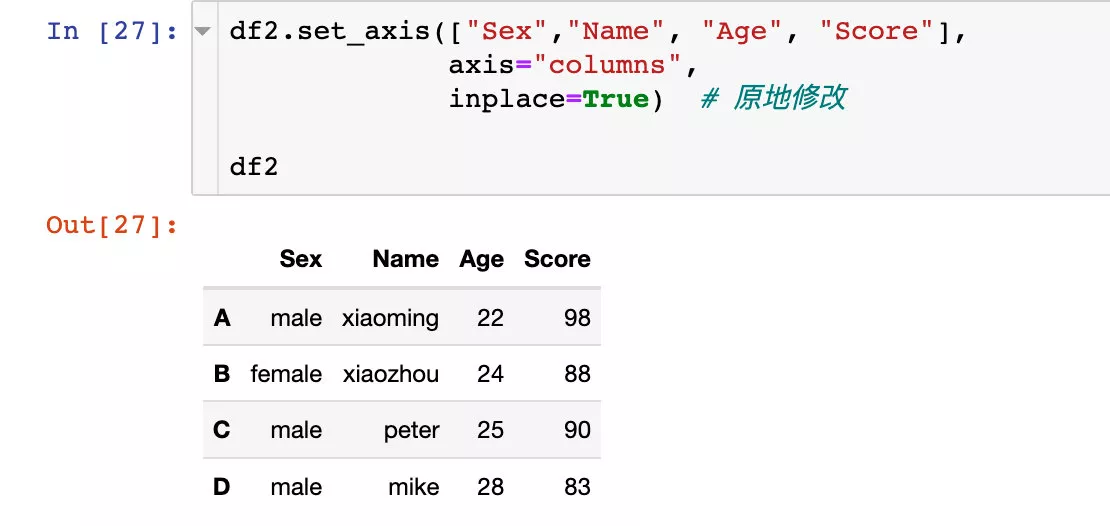
原來的df2是沒有改變的。如果我們想改變生效,同樣也可以直接原地修改:
針對axis=1或者axis="columns"方向上的操作。
1、直接傳入我們需要修改的新名稱:
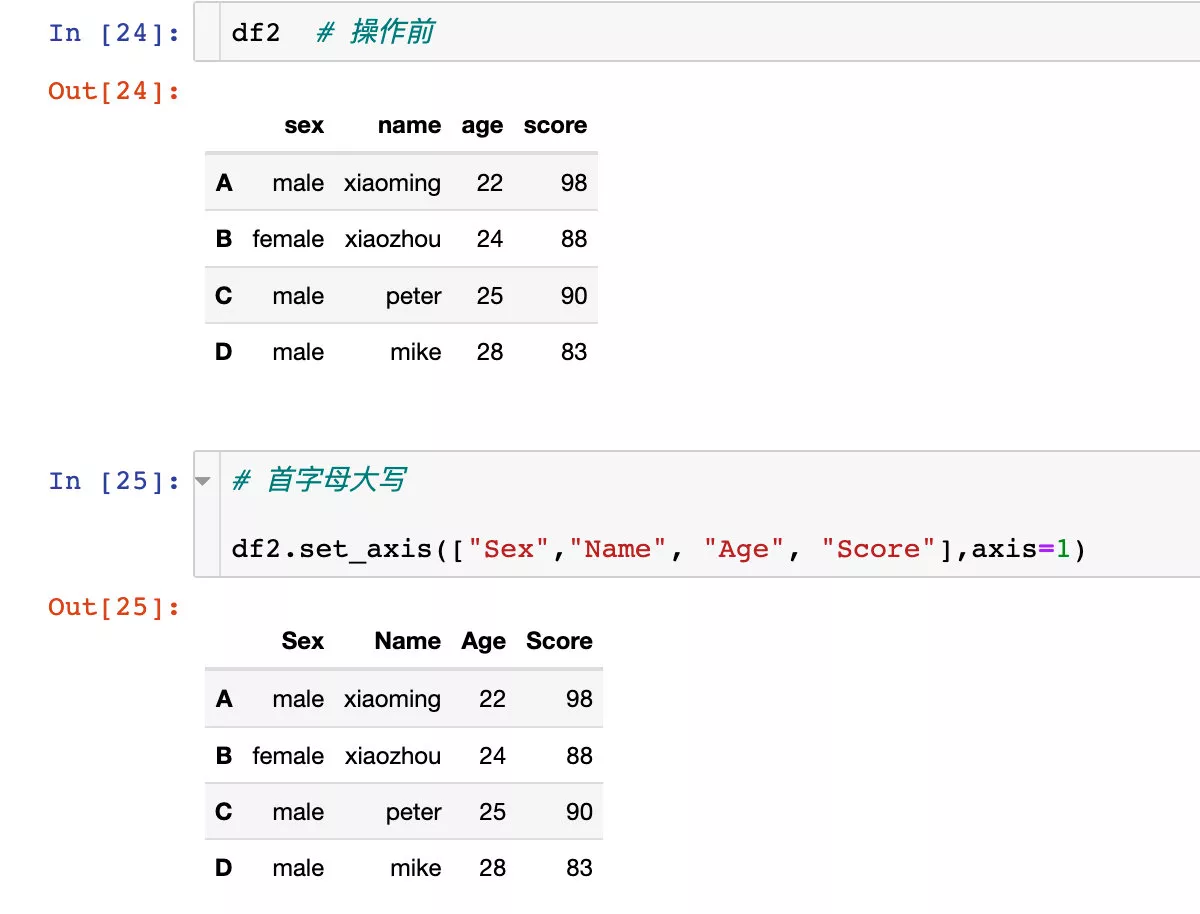
使用axis="columns"效果相同:
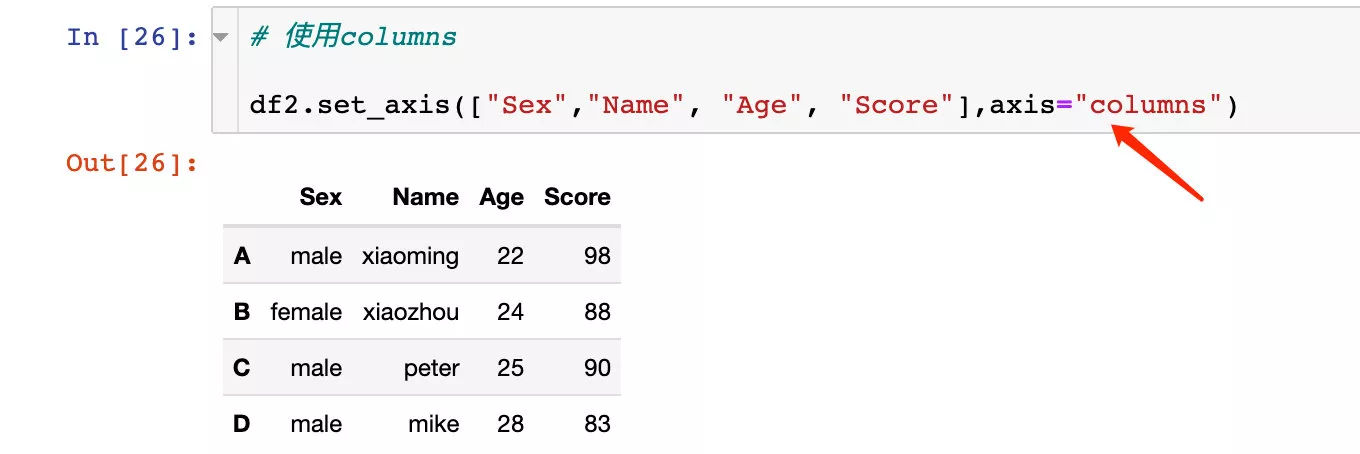
同樣也可以直接原地修改:
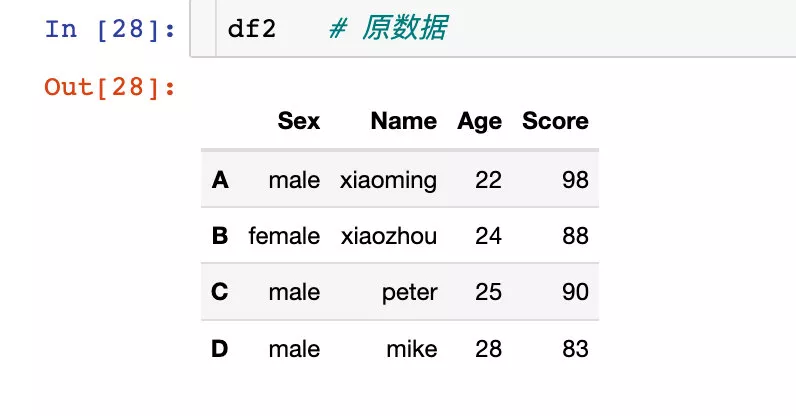
給行索引或者列索引進行重命名,假設我們的原始數據如下:
1、通過傳入的一個或者多個屬性的字典形式進行修改:
In [29]:
# 修改單個列索引;非原地修改df2.rename(columns={"Sex":"sex"})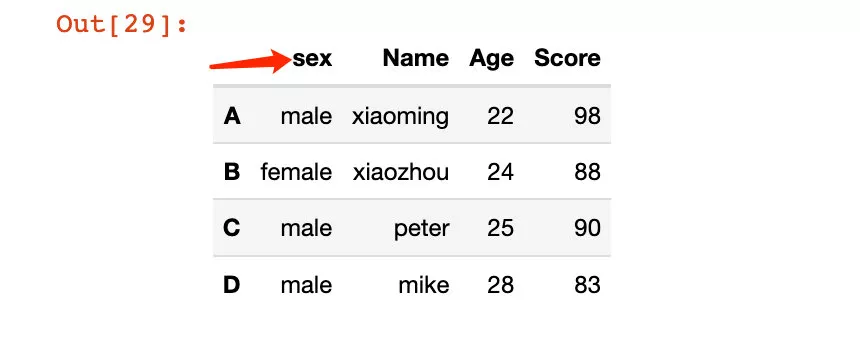
同時修改多個列屬性的名稱:
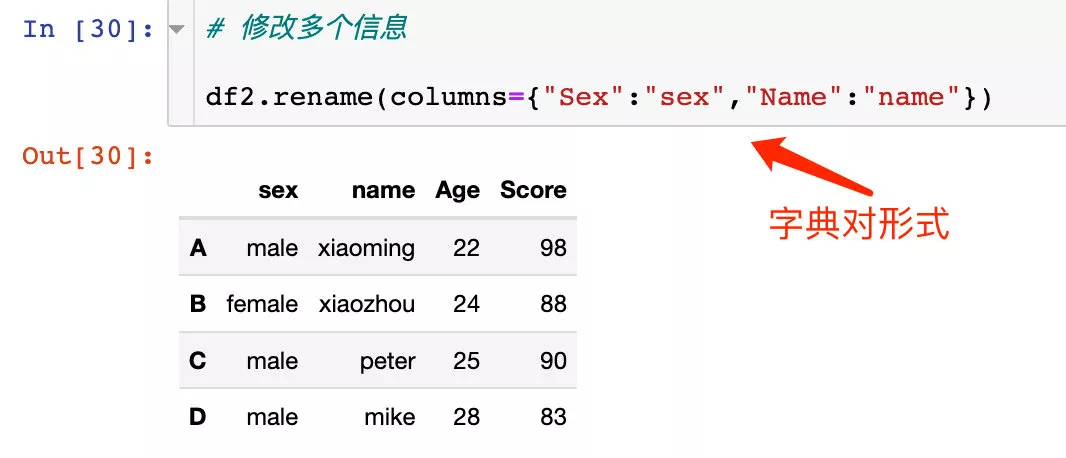
2、通過傳入的函數進行修改:
In [31]:
# 傳入函數df2.rename(str.upper, axis="columns")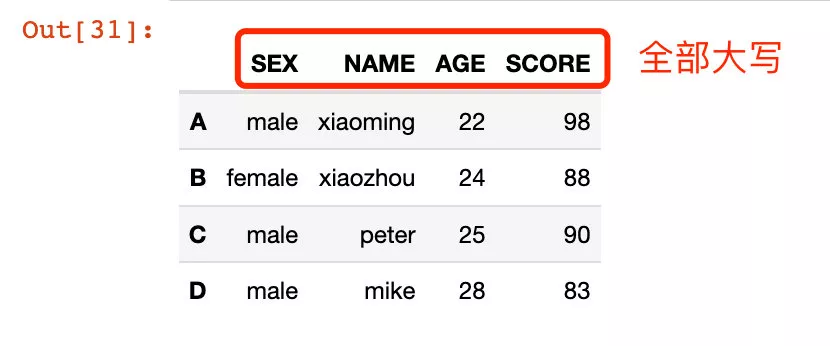
也可以使用匿名函數lambda:
# 全部變成小寫df2.rename(lambda x: x.lower(), axis="columns")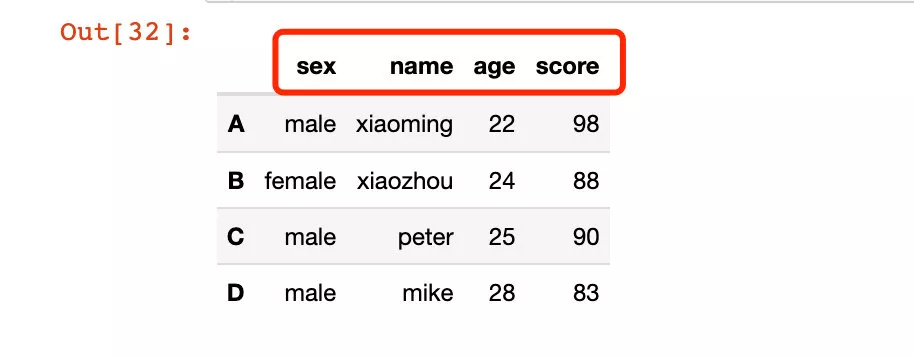
In [33]:
在這裡我們使用的是可視化庫plotly_express庫中的自帶數據集tips:
import plotly_express as pxtips = px.data.tips() tips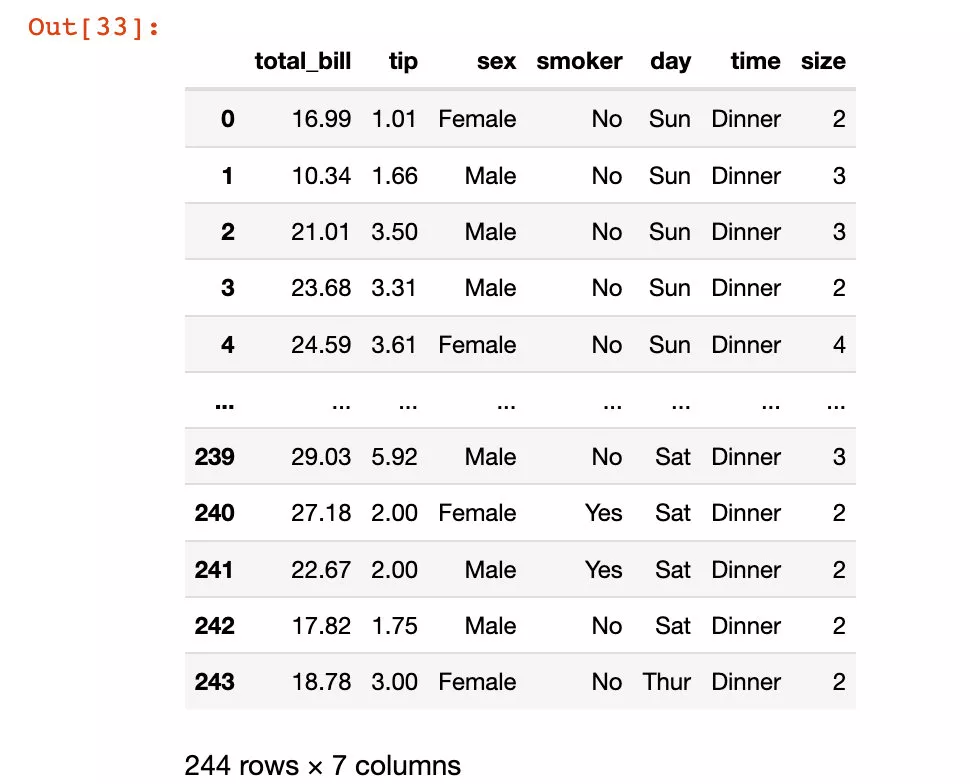
In [34]:
df3 = tips.groupby("day")["total_bill"].sum()df3Out[34]:
dayFri 325.88Sat 1778.40Sun 1627.16Thur 1096.33Name: total_bill, dtype: float64In [35]:
我們發現df3其實是一個Series型的數據:
type(df3) # Series型的數據Out[35]:
pandas.core.series.SeriesIn [36]:
下面我們通過reset_index函數將其變成了DataFrame數據:
df4 = df3.reset_index()df4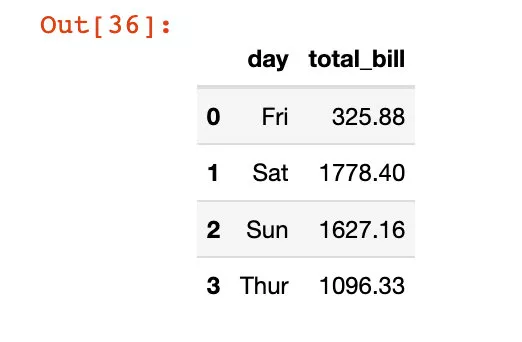
我們把列方向上的索引重新命名下:
In [37]:
# 直接原地修改df4.rename(columns={"day":"Day", "total_bill":"Amount"}, inplace=True)df4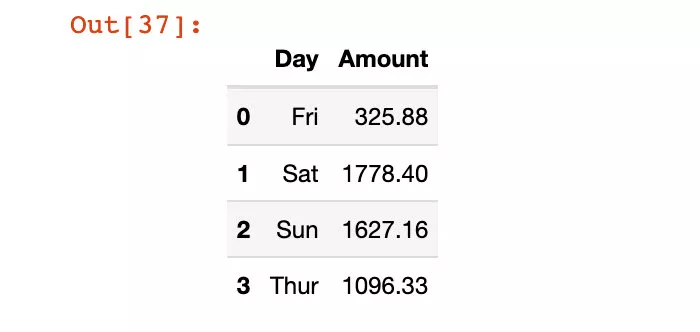
In [38]:
df5 = tips.groupby(["day","sex"]).agg({"tip":"mean", "total_bill":"sum"})df5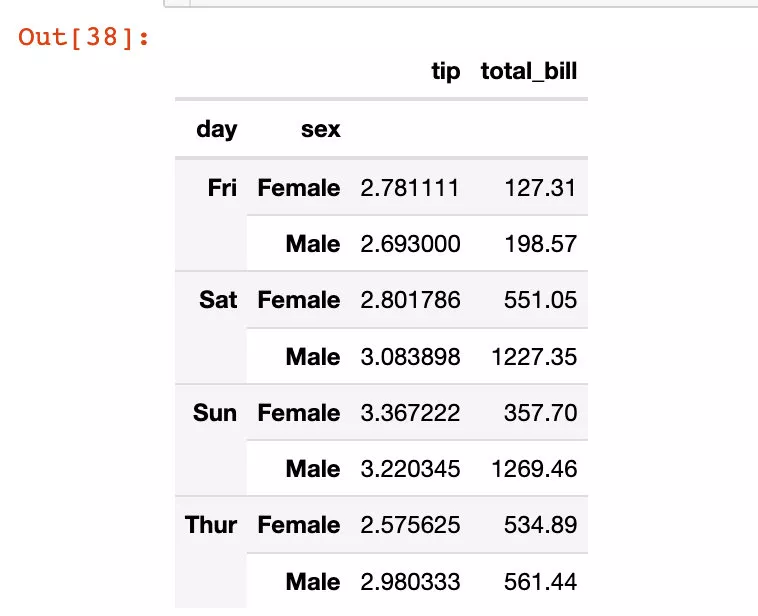
我們發現df5是df5是一個具有多層索引的數據框:
In [39]:
type(df5) Out[39]:
pandas.core.frame.DataFrame我們可以選擇重置其中一個索引:
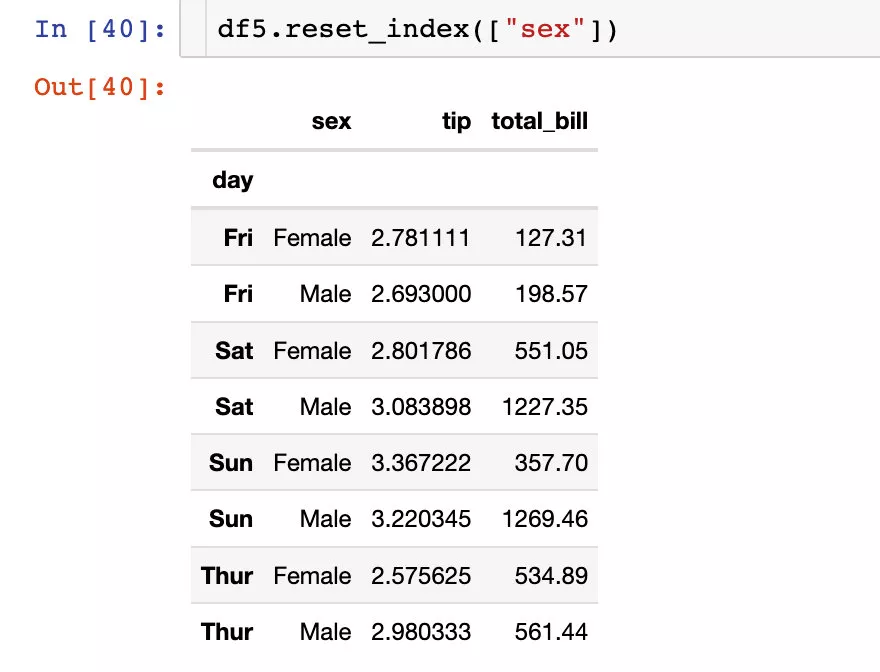
在重置索引的同時,直接丟棄原來的字段信息:下面的sex信息被刪除
In [41]:
df5.reset_index(["sex"],drop=True) # 非原地修改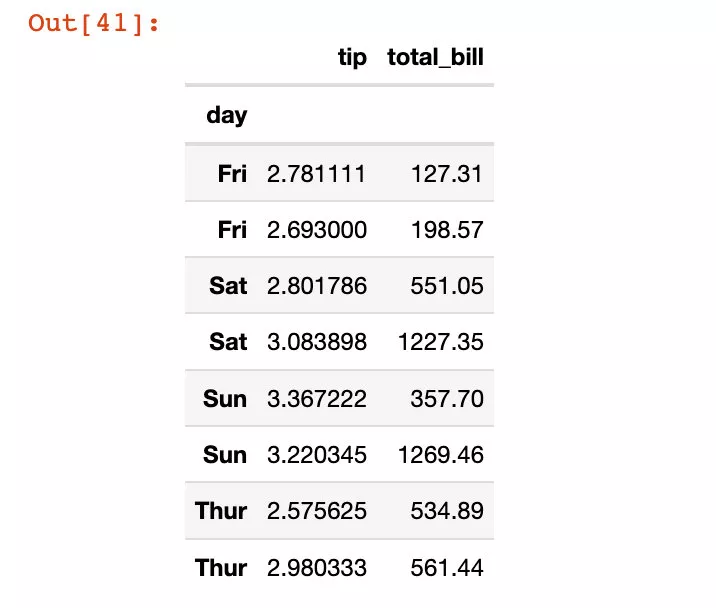
列方向上的索引直接原地修改:
df5.reset_index(inplace=True) # 原地修改df5 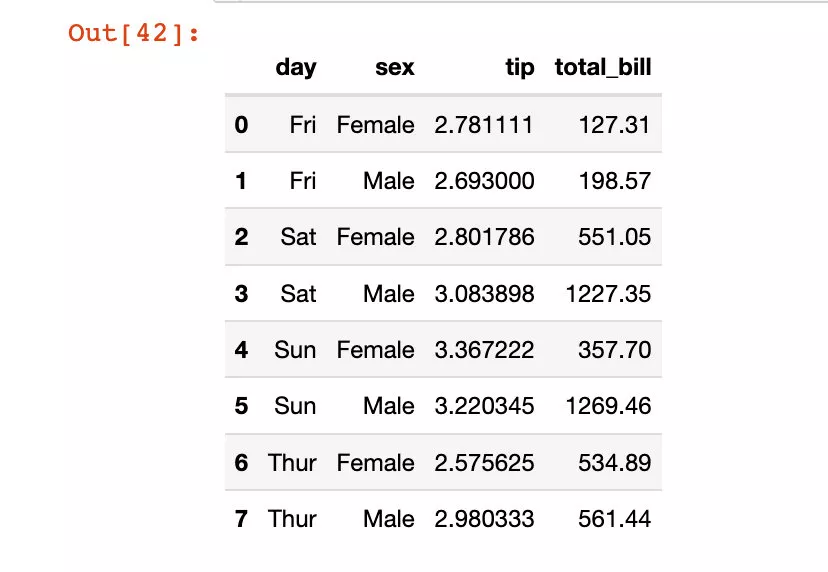
最後介紹一個笨方法來修改列索引的名稱:就是將新的名稱通過列表的形式全部賦值給數據框的columns屬性
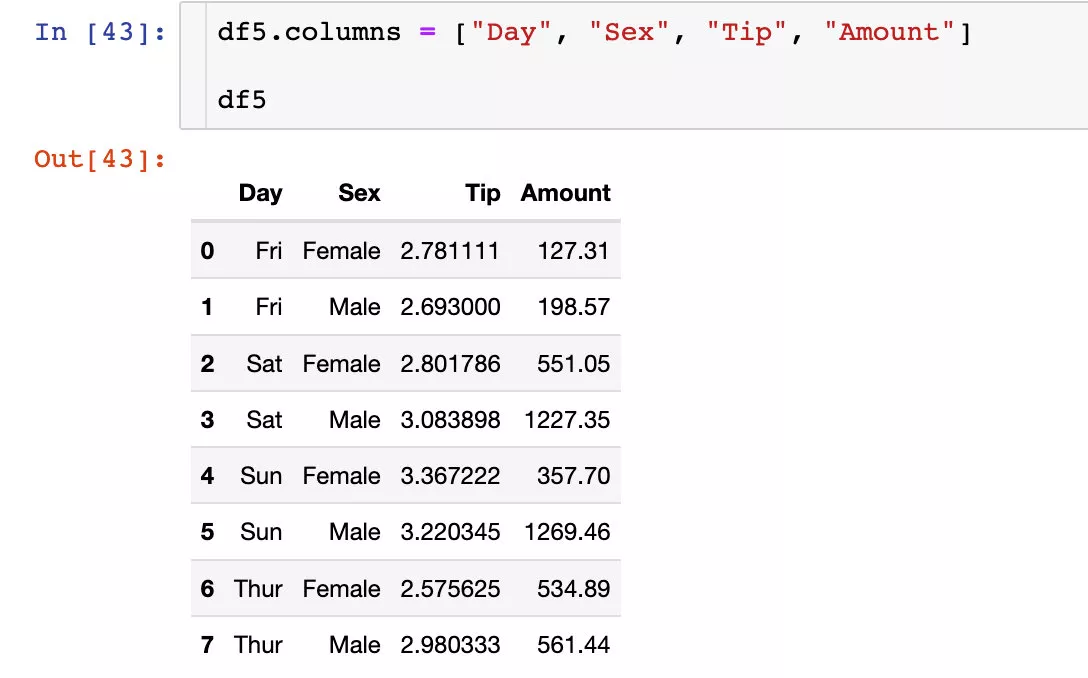
在列索引個數少的時候用起來挺方便的,如果多了不建議使用。
總結到此這篇關於Python pandas索引的設置和修改的文章就介紹到這了,更多相關pandas索引設置和修改內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!