前言
一、User-Agent
二、發送請求
三、解析數據
四、構建ip代理池,檢測ip是否可用
五、完整代碼
總結
前言在使用爬蟲的時候,很多網站都有一定的反爬措施,甚至在爬取大量的數據或者頻繁地訪問該網站多次時還可能面臨ip被禁,所以這個時候我們通常就可以找一些代理ip來繼續爬蟲測試。
下面就開始來簡單地介紹一下爬取免費的代理ip來搭建自己的代理ip池:本次爬取免費ip代理的網址:http://www.ip3366.net/free/
提示:以下是本篇文章正文內容,下面案例可供參考
一、User-Agent在發送請求的時候,通常都會做一個簡單的反爬。這時可以用fake_useragent模塊來設置一個請求頭,用來進行偽裝成浏覽器,下面兩種方法都可以。
from fake_useragent import UserAgentheaders = { # 'User-Agent': UserAgent().random #常見浏覽器的請求頭偽裝(如:火狐,谷歌) 'User-Agent': UserAgent().Chrome #谷歌浏覽器 }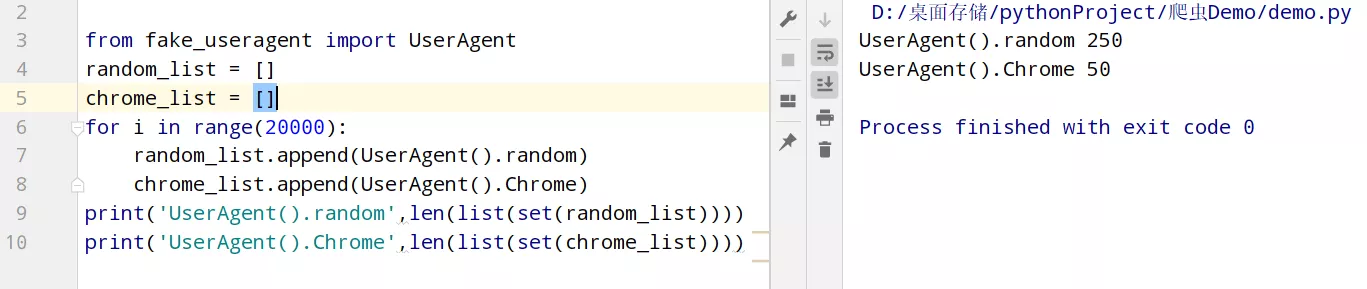
response = requests.get(url='http://www.ip3366.net/free/', headers=request_header()) # text = response.text.encode('ISO-8859-1') # print(text.decode('gbk'))三、解析數據我們只需要解析出ip、port即可。
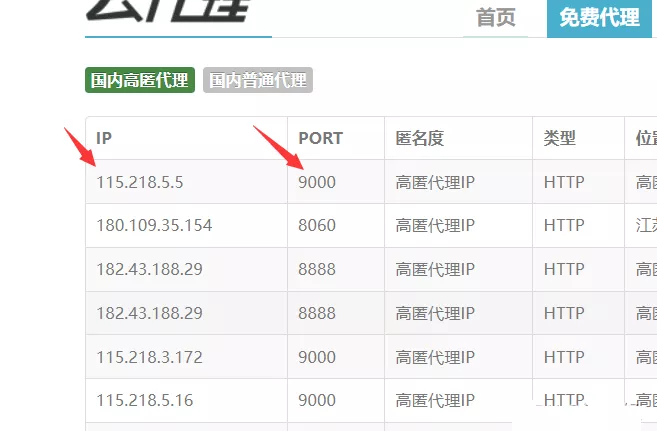
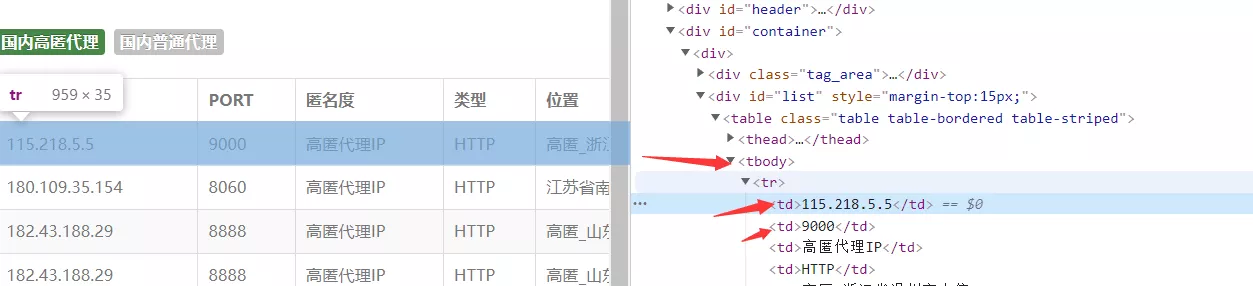
使用xpath解析(個人很喜歡用)(當然還有很多的解析方法,如:正則,css選擇器,BeautifulSoup等等)。
#使用xpath解析,提取出數據ip,端口 html = etree.HTML(response.text) tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr') for td in tr_list: ip_ = td.xpath('./td[1]/text()')[0] #ip port_ = td.xpath('./td[2]/text()')[0] #端口 proxy = ip_ + ':' + port_ #115.218.5.5:9000四、構建ip代理池,檢測ip是否可用#構建代理ipproxy = ip + ':' + portproxies = { "http": "http://" + proxy, "https": "http://" + proxy, # "http": proxy, # "https": proxy, } try: response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) #設置timeout,使響應等待1s response.close() if response.status_code == 200: print(proxy, '\033[31m可用\033[0m') else: print(proxy, '不可用') except: print(proxy,'請求異常')五、完整代碼import requests #導入模塊from lxml import etreefrom fake_useragent import UserAgent#簡單的反爬,設置一個請求頭來偽裝成浏覽器def request_header(): headers = { # 'User-Agent': UserAgent().random #常見浏覽器的請求頭偽裝(如:火狐,谷歌) 'User-Agent': UserAgent().Chrome #谷歌浏覽器 } return headers'''創建兩個列表用來存放代理ip'''all_ip_list = [] #用於存放從網站上抓取到的ipusable_ip_list = [] #用於存放通過檢測ip後是否可以使用#發送請求,獲得響應def send_request(): #爬取7頁,可自行修改 for i in range(1,8): print(f'正在抓取第{i}頁……') response = requests.get(url=f'http://www.ip3366.net/free/?page={i}', headers=request_header()) text = response.text.encode('ISO-8859-1') # print(text.decode('gbk')) #使用xpath解析,提取出數據ip,端口 html = etree.HTML(text) tr_list = html.xpath('/html/body/div[2]/div/div[2]/table/tbody/tr') for td in tr_list: ip_ = td.xpath('./td[1]/text()')[0] #ip port_ = td.xpath('./td[2]/text()')[0] #端口 proxy = ip_ + ':' + port_ #115.218.5.5:9000 all_ip_list.append(proxy) test_ip(proxy) #開始檢測獲取到的ip是否可以使用 print('抓取完成!') print(f'抓取到的ip個數為:{len(all_ip_list)}') print(f'可以使用的ip個數為:{len(usable_ip_list)}') print('分別有:\n', usable_ip_list)#檢測ip是否可以使用def test_ip(proxy): #構建代理ip proxies = { "http": "http://" + proxy, "https": "http://" + proxy, # "http": proxy, # "https": proxy, } try: response = requests.get(url='https://www.baidu.com/',headers=request_header(),proxies=proxies,timeout=1) #設置timeout,使響應等待1s response.close() if response.status_code == 200: usable_ip_list.append(proxy) print(proxy, '\033[31m可用\033[0m') else: print(proxy, '不可用') except: print(proxy,'請求異常')if __name__ == '__main__': send_request()總結到此這篇關於Python爬蟲實現搭建代理ip池的文章就介紹到這了,更多相關Python代理ip池內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!