本篇內容主要講解“如何利用Python實現翻譯HTML中的文本字符串”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何利用Python實現翻譯HTML中的文本字符串”吧!
相信大家都用過浏覽器的翻譯網頁功能,例如對於下圖這個英文網頁:
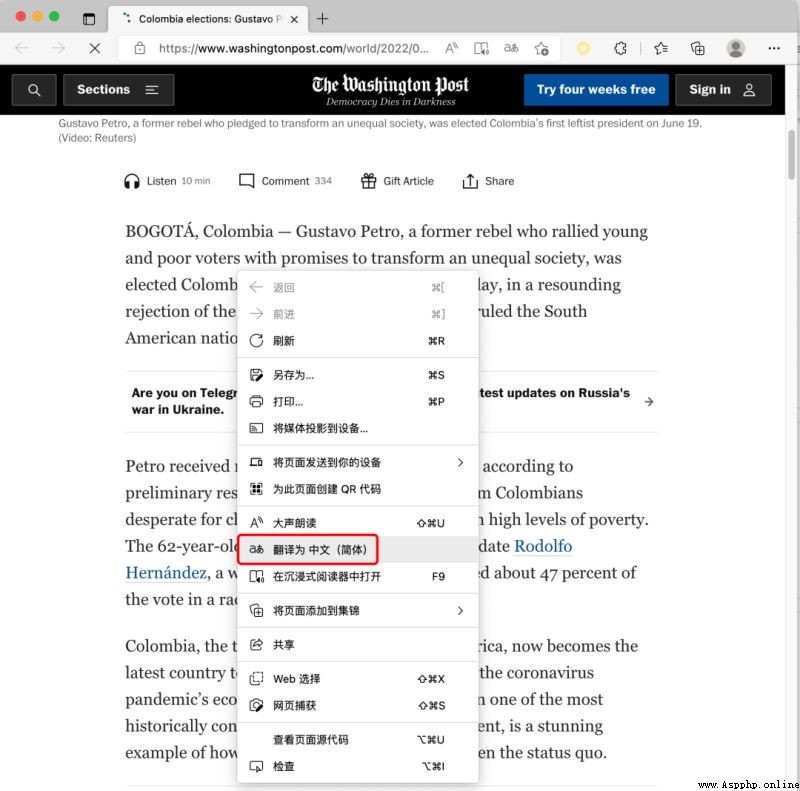
一鍵翻譯成中文以後是這樣的:
你可能會覺得這個功能很簡單,不就是字符串替換嗎?那你可以試一試把下面這個HTML片段中的<p>標簽下面的英文翻譯成中文。其它標簽中的不要改動:
<div> <p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p></div>
在<em>標簽中的datetime和<span>標簽中的datetime.datetime.now()不需要翻譯。
你一拍腦袋,馬上寫出了下面這幾行代碼(假設你已經有了一個現成的translate()函數,傳入英文,輸出中文):
from lxml.html import fromstringsource = '''<div> <p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p></div>'''selector = fromstring(source)text_list = selector.xpath('//p/text()')for text in text_list: chinese = translate(text) ...當你寫到這裡,你應該會愣一下。因為你突然發現一個問題,怎麼把中文替換回去?
不用嘗試去百度了。在今天(2022-06-20)之前,整個中文網絡裡面,你找不到解決方法。
一個比較笨的辦法是直接對原始的HTML字符串進行文本替換:
for text in text_list: chinese = translate(text) source = source.replace(text, chinese)
但這樣做,效率非常低。因為你要不停掃描整個HTML字符串。一般一個中型網站的HTML就有幾千上萬行,十幾二十萬個字符。你每翻譯一小段就全文替換一次,這個時間會非常漫長。
那有沒有辦法只對當前這一個<p>標簽裡面的文本進行替換呢?關鍵的問題來了,你替換可以,但是怎麼才能不影響這個<p>標簽下面的兩個子標簽?要保證文本和子標簽的相對位置不改變。
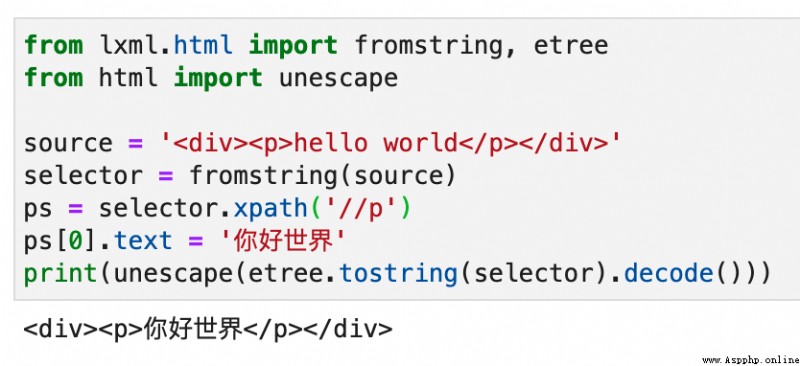
如果<p>標簽下面只有一段文本,沒有子標簽,那麼非常簡單,如下圖所示:
但現在的問題是,<p>標簽下面有三段文本。每段文本之間還插入了其它的子標簽。我們怎麼樣對每一段文本進行替換,但是又保持文本的相對順序,並且還不能影響子標簽?
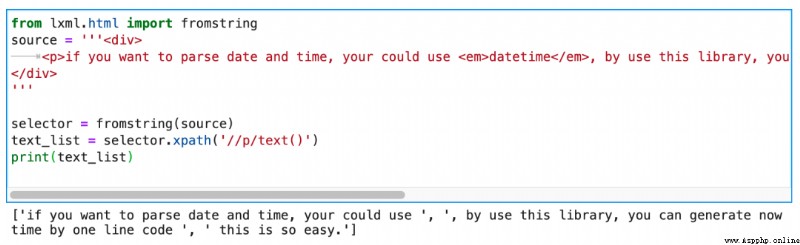
p.text這種寫法首先就可以排除了,因為它沒有辦法指定替換第幾段文本。
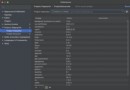
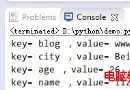
你之所以會覺得這個問題很難解決,是因為你有一個錯覺,請看上面這張截圖,我打印了text_list。打印出來是一個包含字符串的列表。所以你可能會覺得。使用lxml寫Xpath的時候,/text()返回的總是包含字符串的列表。
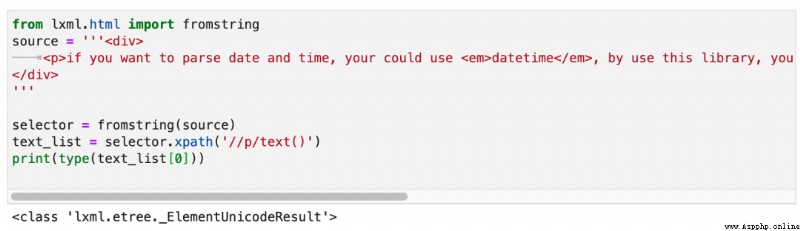
但實際上,返回的列表裡面的元素並不是字符串,而是_ElementUnicodeResult對象。如下圖所示:
不是字符串就簡單了,那麼我們可以獲取每一個文本對象的父標簽。然後修改父標簽下面的文本就可以了。
看到這裡,你肯定會問,這三個文本節點的父標簽,不都是同一個<p>嗎?如果你覺得是,那你就犯了想當然的錯誤。我們用代碼來看看:

其實只有第一段文本的父標簽是<p>。第二段文本的父標簽,竟然是<p>的子標簽<em>。第三段文本的父標簽,是<span>。
等等,如果第二段文本的父標簽是<em>,那麼<em>datetime</em>裡面的datetime的父標簽是什麼?它的父標簽也是<em>!那麼問題來了,<em>的text()文本節點,怎麼可能又是datetime,又是<p>下面的第二段文本呢?
實際上,<em>的text()始終都是datetime。如下圖所示:
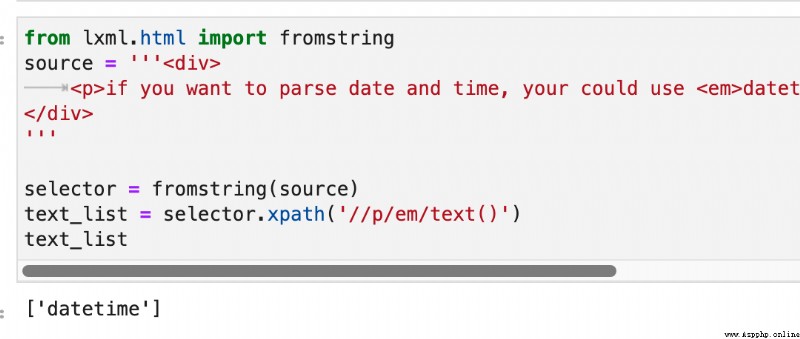
那麼,<p>的第二段文本跟這個<em>標簽是什麼關系?實際上,這個關系叫做tail。如下圖所示:
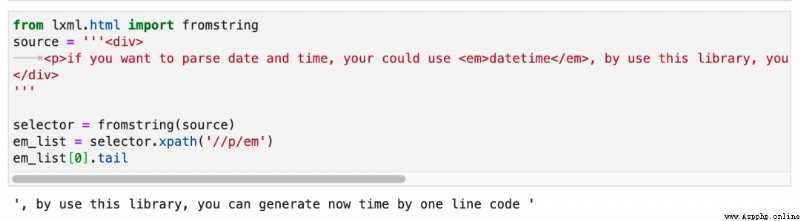
在一個標簽裡面,只有第一段text是它真正的text(),如果這個標簽有子標簽,那麼位於子標簽後面的文本,是這個子標簽的tail。只不過當我們在正則表達式裡面寫/text()的時候,lxml會幫我們把所有子標簽的tail都算作當前標簽的text。
我們可以使用文本節點的.is_text和.is_tail來判斷它屬於哪種文本。最終運行效果如下圖所示:
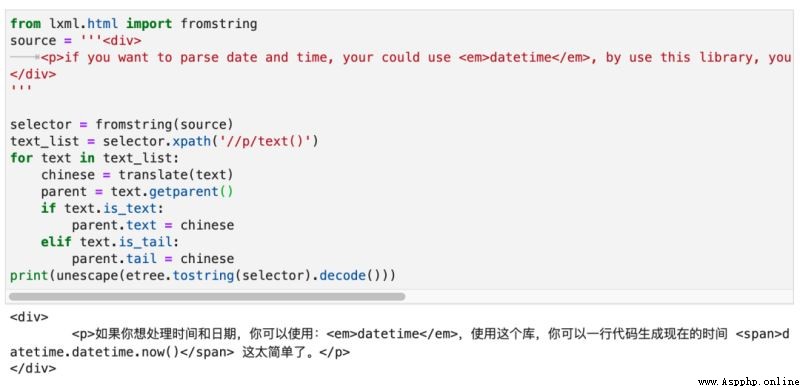
到此,相信大家對“如何利用Python實現翻譯HTML中的文本字符串”有了更深的了解,不妨來實際操作一番吧!這裡是億速雲網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!