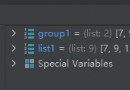
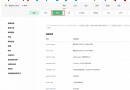
用Python做算法,對字符串的操作用到的不多。
但是用Python來處理日常生活、工作中的許多問題,比如文本處理,辦公自動化等就常常要用到字符串的操作了。
所以,有必要把Python中的字符串操作方法總結一下。
示例代碼如下:
# 字母大寫轉換成小寫
s1 = 'SUWENHAO'
s2 = s1.lower()
# 字母小寫轉換成大寫
s3 = 'wanghong'
s4 = s3.upper()
# 字母大寫轉換小寫,小寫轉換成大寫
s5 = 'SuWenHao'
s6 = s5.swapcase()
# 將每一個單中大寫和首字母大寫
s7 = 'andy is a boy'
s8_1 = s7.title() # 每一個單詞都大寫
s8_2 = s7.capitalize() # 只大寫第一個單詞
運行結果如下:
S.find(substr,[start,[end]])—返回S中出現substr的第一個字母的標號,如果S中沒有substr則返回-1,start和end作用就相當於在S[start:end]中搜索。
示例代碼如下:
s1 = 'i love zi heng and zi man'
zi_index = s1.find('zi')
運行結果如下: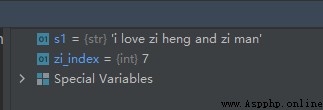
從上面的結果我們可以看出,位置索引是從0開始的。
如果想得到字符串substr出現的最後位置,可以用函數rfind()實現。
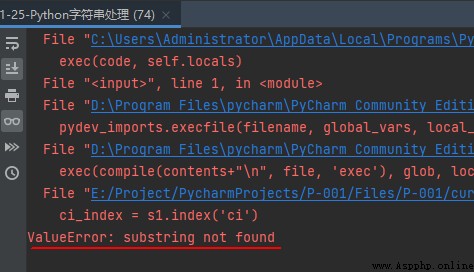
函數index()跟find()方法一樣,只不過如果substr不在 string中會報出一個異常,其示例代碼如下:
str.index(str, beg=0, end=len(string))
s1 = 'i love zi heng and zi man'
zi_index = s1.index('zi')
ci_index = s1.index('ci')
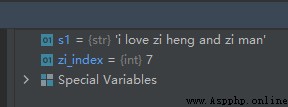
同樣,如果想得到字符串substr出現的最後位置,可以用函數rindex()實現。
示例代碼如下:
s1 = 'i love zi heng and zi man'
zi_bool = 'zi' in s1
hong_bool = 'hong' in s1
運行結果如下: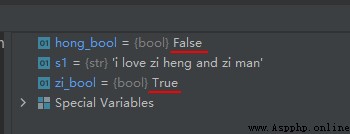
示例代碼如下:
s1 = 'i love zi heng and zi man'
zi_bool = 'zi' not in s1
hong_bool = 'hong' not in s1
運行結果如下: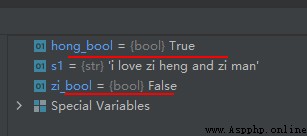
str.count(sub, start= 0,end=len(string))
sub – 搜索的子字符串
start – 字符串開始搜索的位置。默認為第一個字符,第一個字符索引值為0。
end – 字符串中結束搜索的位置。字符中第一個字符的索引為 0。默認為字符串的最後一個位置。
示例代碼如下:
s1 = 'i love zi heng and zi man'
zi_count = s1.count('zi')
運行結果如下:
分析:字符串“zi”在s1中出現了兩次,所以結果為2。
str.max(str)
str.min(str)
S.replace(oldstr,newstr,[count])—把S中的oldstar替換為newstr,count為最多做多少次替換次數,count的默認值為-1,代表替換所有。
示例代碼如下:
s1 = 'i love zi heng and zi man'
s2 = s1.replace('zi', 'su zi', 1) # 最多替換一次
s3 = s1.replace('zi', 'su zi', 2) # 最多替換兩次
s4 = s1.replace('zi', 'su zi') # 替換所有
運行結果如下: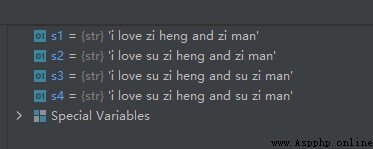
S.strip([chars])—把S左右兩端chars中有的字符全部去掉,一般用於去除空格。
S.lstrip([chars])—把S左端chars中所有的字符全部去掉。
S.rstrip([chars])—把S右端chars中所有的字符全部去掉。
示例代碼如下:
s1 = '00000003210Runoob01230000000'
s2_both = s1.strip('0') # 去除首尾字符"0"
s2_left = s1.lstrip('0') # 去除左端的字符"0"
s2_right = s1.rstrip('0') # 去除右端的字符"0"
s3 = ' Runoob '
s4_both = s3.strip(' ') # 去除首尾空格
s4_left = s3.lstrip(' ') # 去除左端空格
s4_right = s3.rstrip(' ') # 去除右端空格
運行結果如下:
這些操作的示例代碼就暫不上了。
示例代碼如下:
str1 = 'hello suwenhao'
str2 = str1[:6] + 'wang hong!'
print("輸出 :", str2, 'Nice to meet you!')
上面代碼中的str2是由字符串str1[:6] 和字符串 ‘wang hong!’ 連接起來的。
字符串str1[:6]是截取str1的第0到5個,即前6個。
運行結果如下:

示例代碼如下:
str1 = 'abc'
str2 = str1*3
運行結果如下: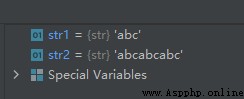
示例代碼如下:
str1 = 'abcdef'
str2 = str1[:3]
運行結果如下: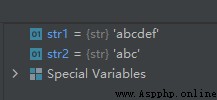
print(r'i love you \n\r')
print(R'i hate you \n\r')
運行結果如下: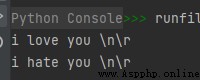
從上面的代碼和結果來看,在字符串前加小寫的r和大寫的R都可以實現這個效果。
示例代碼如下:
hi = '''hi there'''
print(hi)
運行結果如下: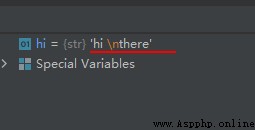
三引號讓程序員從引號和特殊字符串的泥潭裡面解脫出來,自始至終保持一小塊字符串的格式是所謂的WYSIWYG(所見即所得)格式的。
一個典型的用例是,當你需要一塊HTML或者SQL時,這時當用三引號標記,使用傳統的轉義字符體系將十分費神。
Unicode(統一碼、萬國碼、單一碼)是一種在計算機上使用的字符編碼。
Unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一並且唯一的二進制編碼,以滿足跨語言、跨平台進行文本轉換、處理的要求。1990年開始研發,1994年正式公布。
它將世界上所有的文字用2個字節統一進行編碼。Unicode用數字0-0x10FFFF來映射這些字符,最多可以容納1114112個字符,或者說有1114112個碼位。
python2.x默認的字符編碼是ASCII,默認的文件遍碼也是ASCII.
python 3.x默認的字符編碼是unicode,默認的文件編碼是utf-8。
所以,其實將字符串以Unicode碼進行編碼主要是針對python2.x。
具體來說,在Python中可按下面這樣定義一個字符串由Unicode碼進行編碼。
示例代碼如下:
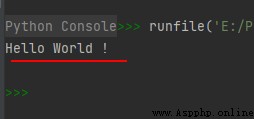
str1 = u'Hello World !'
引號前小寫的"u"表示這裡創建的是一個 Unicode 字符串。如果你想加入一個特殊字符,可以使用 Python 的 Unicode-Escape 編碼。如下例所示:
str1 = u'Hello\u0020World !'
print(str1)
運行結果如下所示:
被替換的 \u0020 標識表示在給定位置插入編碼值為 0x0020 的 Unicode 字符(空格符)。
編碼:
str.encode(encoding='UTF-8',errors='strict')
encoding – 把字符串用什麼碼進行編碼,如UTF-8、gb2312、gbk、 big5…等
errors – 設置不同錯誤的處理方案。默認為 ‘strict’,意為編碼錯誤引起一個UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通過 codecs.register_error() 注冊的任何值。
解碼:
str.decode(encoding='UTF-8',errors='strict')
encoding – 原來的字符串是什麼碼進行編碼的,如UTF-8、gb2312、gbk、 big5…等
errors – 設置不同錯誤的處理方案。默認為 ‘strict’,意為編碼錯誤引起一個UnicodeError。 其他可能得值有 ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ 以及通過 codecs.register_error() 注冊的任何值。
注意:函數decode是把字符串解碼成unicode編碼,而不是encoding代表的編碼,參數encoding只是告訴函數我原來的編碼是什麼。
上面兩個函數使用示例如下:
str1 = 'this is string example'
str2 = str1.encode('big5', 'strict')
str3 = str2.decode('big5', 'strict') # 將big5解碼成unicode編碼
運行結果如下:
str.center(width[, fillchar])
示例:
str1 = 'haohong'
str2 = str1.center(20, '*')
print(str2)
運行結果如下: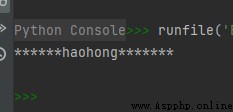
ljust() 方法返回一個原字符串左對齊,並使用空格填充至指定長度的新字符串。如果指定的長度小於原字符串的長度則返回原字符串。
str.ljust(width[, fillchar])
width – 指定字符串長度。
fillchar – 填充字符,默認為空格。
使用示例如下:
str1 = "i love my city"
print(str1.ljust(30, '#'))
運行結果如下: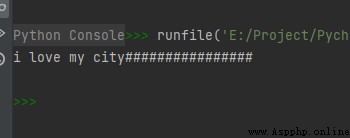
rjust() 方法返回一個原字符串左對齊,並使用空格填充至指定長度的新字符串。如果指定的長度小於原字符串的長度則返回原字符串。
str.rjust(width[, fillchar])
width – 指定字符串長度。
fillchar – 填充字符,默認為空格。
使用示例如下:
str1 = "i love my city"
print(str1.rjust(30, '#'))
運行結果如下: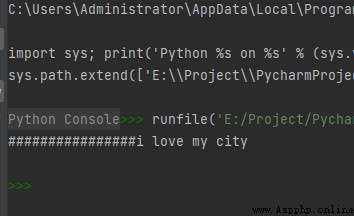
原型如下:
str.zfill(width)
示例代碼如下:
str1 = "i love my city"
print(str1.zfill(30))
運行結果如下: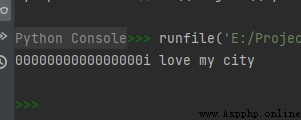
str.endswith(suffix[, start[, end]])
suffix – 該參數可以是一個字符串或者是一個元素。
start – 字符串中的開始位置。
end – 字符中結束位置。
如果字符串含有指定的後綴返回True,否則返回False。
示例代碼如下:
str1 = 'this is string example'
str2 = 'example'
str3 = 'fuck'
end_bool1 = str1.endswith(str2)
end_bool2 = str1.endswith(str3)
運行結果如下: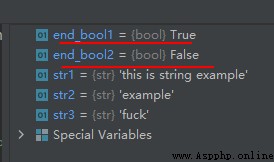
str.startswith(str, beg=0,end=len(string));
str – 檢測的字符串。
strbeg – 可選參數用於設置字符串檢測的起始位置。
strend – 可選參數用於設置字符串檢測的結束位置。
如果檢測到字符串則返回True,否則返回False。
示例代碼如下:
str1 = 'this is string example'
str2 = 'thi'
str3 = 'fuck'
end_bool1 = str1.startswith(str2)
end_bool2 = str1.startswith(str3)
運行結果如下: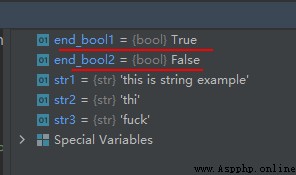
string.expandtabs(tabsize=8)
把字符串 string 中的 tab 符號轉為空格,tab 符號默認的空格數是 8。
示例代碼如下:
str1 = 'AAA\tBBB' # \t代表制表符
str2 = str1.expandtabs(tabsize=8)
print(str1)
print(str2)
運行結果如下: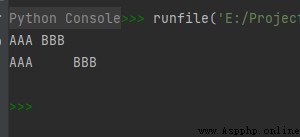
這個的詳細情況和使用示例見博文 https://blog.csdn.net/wenhao_ir/article/details/125390532
示例代碼如下:
str1 = "-"
seq = ("a", "b", "c") # 字符串序列
print(str1.join(seq))
運行結果如下: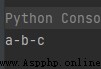
str.maketrans(intab, outtab)
示例代碼如下:
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab)
str1 = "this is string example....wow!!!"
print(str1.translate(trantab))
運行結果如下: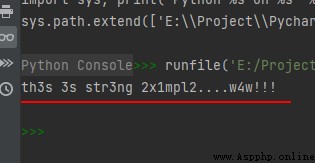
partition() 方法用來根據指定的字符串作為分割符將字符串進行分割。
如果字符串包含指定的分隔符,則返回一個3元的元組,第一個為分隔符左邊的子串,第二個為分隔符本身,第三個為分隔符右邊的子串。
示例代碼如下:
str1 = "blog.csdn.net/wenhao_ir"
print(str1.partition("net/"))
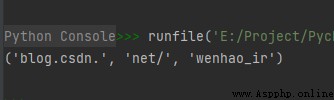
如果想從右邊開始查找分割符,則可用函數rpartition() 實現。
str.split(str="", num=string.count(str))
split() 通過指定分隔符對字符串進行切片,如果參數 num 有指定值,則分隔 num+1 個子字符串。
str – 分隔符,默認為所有的空字符,包括空格、換行(\n)、制表符(\t)等。
num – 分割次數。默認為 -1, 即分隔所有。
示例代碼如下:
txt = "Google#CSDN#Taobao#Facebook"
x1 = txt.split("#")
x2 = txt.split("#", 1)
x3 = txt.split("#", 2)
print(x1)
print(x2)
print(x3)
運行結果如下: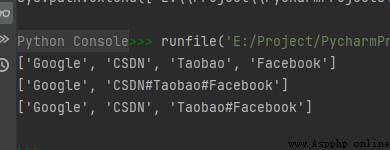
str.splitlines([keepends])
keepends – 在輸出結果裡是否保留換行符(‘\r’, ‘\r\n’, \n’),默認為 False,不包含換行符,如果為 True,則保留換行符。
示例代碼如下:
str1 = 'ab c\n\nde fg\rkl\r\n'
print(str1.splitlines())
str2 = 'ab c\n\nde fg\rkl\r\n'
print(str2.splitlines(True))
運行結果如下: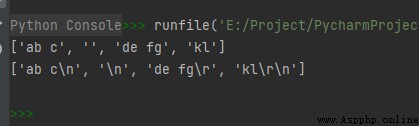
本文參考自:
https://blog.csdn.net/wenhao_ir/article/details/125100220