One 、 Full code display
Two 、 explain
1.with closing
with usage ( Realize context management )
closing usage ( Solve these problems perfectly )
2. File stream stream
3.response.headers['content-length']
4.response.iter_content()
5.\r and %
3、 ... and 、 Result display
Four 、 summary
Preface :
When crawling and downloading videos on the web , We need a real-time progress bar , This can help us see the video more intuitively Download progress .
One 、 Full code displayfrom contextlib import closingfrom requests import geturl = 'https://v26-web.douyinvod.com/57cdd29ee3a718825bf7b1b14d63955b/615d475f/video/tos/cn/tos-cn-ve-15/72c47fb481464cfda3d415b9759aade7/?a=6383&br=2192&bt=2192&cd=0%7C0%7C0&ch=26&cr=0&cs=0&cv=1&dr=0&ds=4&er=&ft=jal9wj--bz7ThWG4S1ct&l=021633499366600fdbddc0200fff0030a92169a000000490f5507&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=ank7OzU6ZnRkNjMzNGkzM0ApNmY4aGU8MzwzNzo3ZjNpZWdiYXBtcjQwLXNgLS1kLTBzczYtNS0tMmE1Xi82Yy9gLTE6Yw%3D%3D&vl=&vr='with closing(get(url, stream=True)) as response: chunk_size = 1024 # Single request maximum # response.headers['content-length'] The data type obtained is str instead of int content_size = int(response.headers['content-length']) # Total file size data_count = 0 # Current transmitted size with open(' file name .mp4', "wb") as file: for data in response.iter_content(chunk_size=chunk_size): file.write(data) done_block = int((data_count / content_size) * 50) # The size of the file that has been downloaded data_count = data_count + len(data) # Real time progress bar now_jd = (data_count / content_size) * 100 # %% Express % print("\r [%s%s] %d%% " % (done_block * '█', ' ' * (50 - 1 - done_block), now_jd), end=" ")notes : above url Has expired , You need to find the video on the website by yourself url
Two 、 explain 1.with closingWhen we read file resources everyday , Often used with open() as f: Sentences .
But use with The sentence is Conditions required Of , Any object , As long as context management is implemented correctly , You can use with sentence , Context management is achieved through __enter__ and __exit__ These two methods achieve .
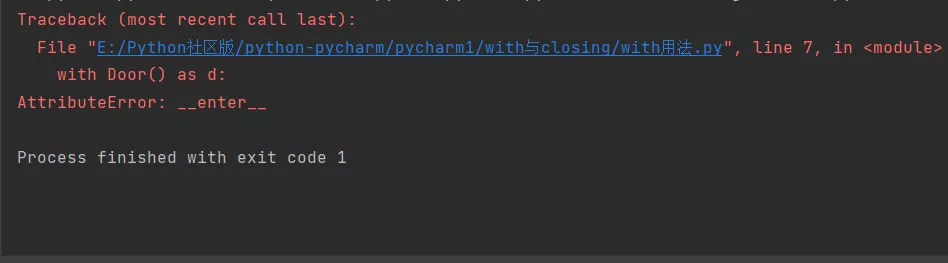
with usage ( Context management is not implemented )
class Door(): def open(self): print('Door is opened') def close(self): print('Door is closed')with Door() as d: d.open() d.close()It turned out to be wrong :
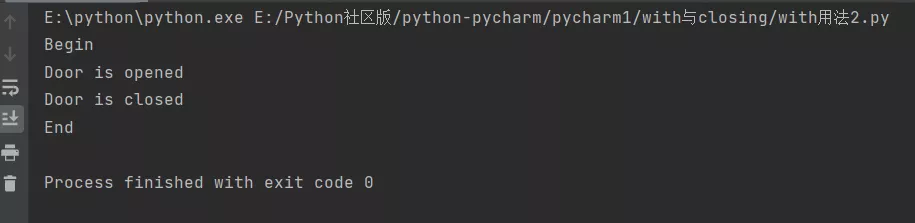
use __enter__ and __exit__ Context management is realized
class Door(): def open(self): print('Door is opened') def close(self): print('Door is closed')with Door() as d: d.open() d.close()The result is correct :
An object has no implementation context , We can't use it for with sentence . This is the time , It can be used contextlib Medium
closing() Come and take the Object becomes a context object .
class Door(): def __enter__(self): print('Begin') return self def __exit__(self, exc_type, exc_value, traceback): if exc_type: print('Error') else: print('End') def open(self): print('Door is opened') def close(self): print('Door is closed')with Door() as d: d.open() d.close()for example : use with Statements use requests Medium get(url)
That is the case in this paper , Use with closing() Download Video ( In the web page )
2. File stream streamImagine , If reading a file is compared to pumping water into a pool , Synchronization blocks programs , Asynchronously waits for results , What if the pool is very big ?
So there's a file stream , It's like you smoke and take , Don't wait until the pool is full ,
So for some large files ( How many? G In the video ) This parameter is generally used .( For small files, you can also use )
3.response.headers['content-length']This represents the total size of the fetch file , But the data type of the result it gets is str instead of int, Therefore, data type conversion is required .
4.response.iter_content()This method is generally used to download files and web pages from the Internet ( Need to use requests.get(url))
among chunk_size Indicates the maximum value of a single request .
5.\r and %\r Said the enter ( Back to the beginning of the line )
% It's a placeholder
And for %%, first % Played the role of escape , Make the result output as a percent sign %
3、 ... and 、 Result display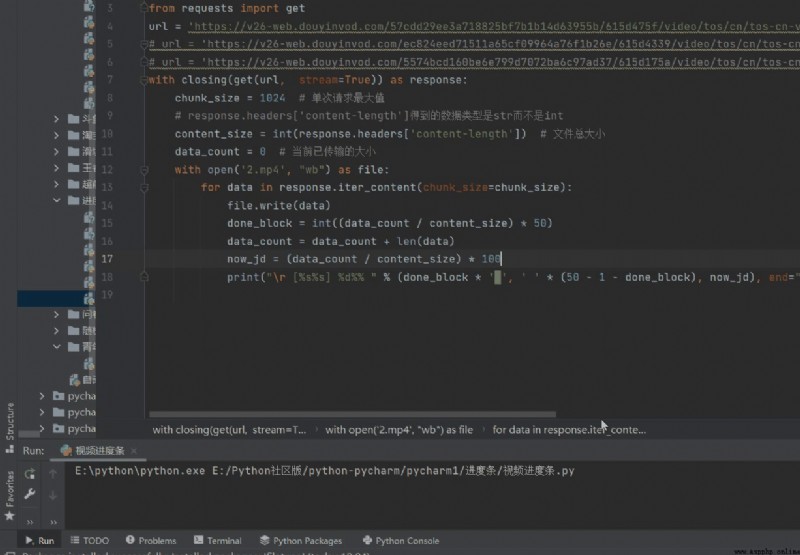
I've seen a lot of progress bars before , These progress bars can move , But it can't be loaded according to the contents of the file ( The parameters inside are either dead , Or it has nothing to do with the file size ), Can't achieve real interaction function , This progress bar is a good display , You can try !!
The download video shows that the progress bar is against a url, You can add it to your reptile's cycle , So you can show the real-time progress bar when climbing each video !!
This is about how to implement python This is the end of the article about real-time progress bar display when crawler crawls video , More about python Crawl to display the progress bar content, please search the previous articles of the software development network or continue to browse the relevant articles below. I hope you can support the software development network in the future !