use Python Do algorithms , Not much is used for string operations .
But with Python To deal with everyday life 、 Many problems in work , Like text processing , For office automation, string operation is often used .
therefore , It is necessary to Python To summarize the string operation methods in .
The sample code is as follows :
# Convert uppercase letters to lowercase
s1 = 'SUWENHAO'
s2 = s1.lower()
# Convert lowercase letters to uppercase
s3 = 'wanghong'
s4 = s3.upper()
# Uppercase to lowercase , Lower case to upper case
s5 = 'SuWenHao'
s6 = s5.swapcase()
# Capitalize every single word and initial letter
s7 = 'andy is a boy'
s8_1 = s7.title() # Every word is capitalized
s8_2 = s7.capitalize() # Capitalize only the first word
The operation results are as follows :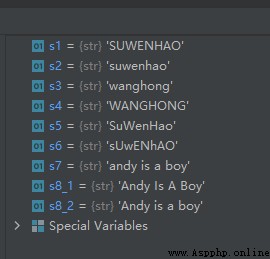
S.find(substr,[start,[end]])— return S It appears that substr The label of the first letter of , If S There is no substr Then return to -1,start and end The effect is equivalent to S[start:end] Mid search .
The sample code is as follows :
s1 = 'i love zi heng and zi man'
zi_index = s1.find('zi')
The operation results are as follows :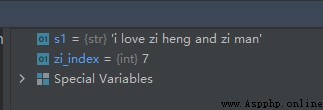
From the above results we can see that , The location index is from 0 At the beginning .
If you want a string substr Last position of occurrence , You can use functions rfind() Realization .
function index() Follow find() The method is the same , Just if substr be not in string An exception will be reported in , The sample code is as follows :
str.index(str, beg=0, end=len(string))
s1 = 'i love zi heng and zi man'
zi_index = s1.index('zi')
ci_index = s1.index('ci')
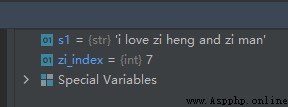
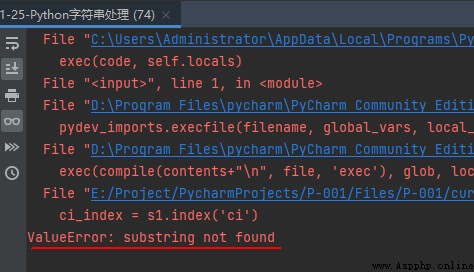
Again , If you want a string substr Last position of occurrence , You can use functions rindex() Realization .
The sample code is as follows :
s1 = 'i love zi heng and zi man'
zi_bool = 'zi' in s1
hong_bool = 'hong' in s1
The operation results are as follows :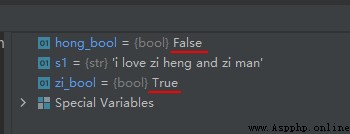
The sample code is as follows :
s1 = 'i love zi heng and zi man'
zi_bool = 'zi' not in s1
hong_bool = 'hong' not in s1
The operation results are as follows :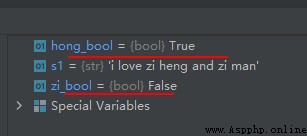
str.count(sub, start= 0,end=len(string))
sub – Search for substrings
start – Where the string starts searching . The default is the first character , The first character index value is 0.
end – Where to end the search in the string . The index of the first character in the character is 0. Default to the last position of the string .
The sample code is as follows :
s1 = 'i love zi heng and zi man'
zi_count = s1.count('zi')
The operation results are as follows :
analysis : character string “zi” stay s1 There were two times in , So the result is 2.
str.max(str)
str.min(str)
S.replace(oldstr,newstr,[count])— hold S Medium oldstar Replace with newstr,count The maximum number of replacements to be made ,count The default value is -1, Stands for replacing all .
The sample code is as follows :
s1 = 'i love zi heng and zi man'
s2 = s1.replace('zi', 'su zi', 1) # Replace at most once
s3 = s1.replace('zi', 'su zi', 2) # At most two replacements
s4 = s1.replace('zi', 'su zi') # Replace all
The operation results are as follows :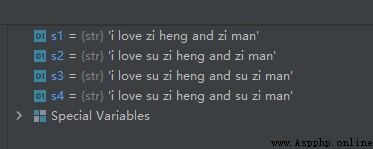
S.strip([chars])— hold S Left and right ends chars Remove all the characters in , Generally used to remove spaces .
S.lstrip([chars])— hold S Left side chars Remove all characters from the .
S.rstrip([chars])— hold S Right end chars Remove all characters from the .
The sample code is as follows :
s1 = '00000003210Runoob01230000000'
s2_both = s1.strip('0') # Remove the first and last characters "0"
s2_left = s1.lstrip('0') # Remove the left character "0"
s2_right = s1.rstrip('0') # Remove the right character "0"
s3 = ' Runoob '
s4_both = s3.strip(' ') # Remove the leading and trailing spaces
s4_left = s3.lstrip(' ') # Remove the left space
s4_right = s3.rstrip(' ') # Remove the right space
The operation results are as follows :
The sample code for these operations is not available for the time being .
The sample code is as follows :
str1 = 'hello suwenhao'
str2 = str1[:6] + 'wang hong!'
print(" Output :", str2, 'Nice to meet you!')
In the above code str2 It's made up of strings str1[:6] And string ‘wang hong!’ Connected .
character string str1[:6] It's interception str1 Of the 0 To 5 individual , The former 6 individual .
The operation results are as follows :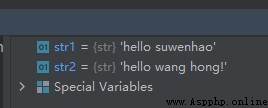

The sample code is as follows :
str1 = 'abc'
str2 = str1*3
The operation results are as follows :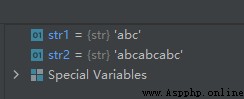
The sample code is as follows :
str1 = 'abcdef'
str2 = str1[:3]
The operation results are as follows :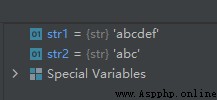
print(r'i love you \n\r')
print(R'i hate you \n\r')
The operation results are as follows :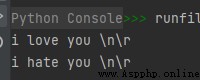
From the above code and results , Add lowercase before the string r And capital R Can achieve this effect .
The sample code is as follows :
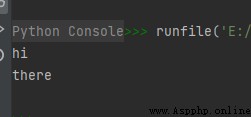
hi = '''hi there'''
print(hi)
The operation results are as follows :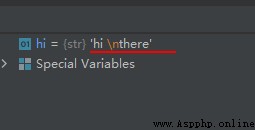
Three quotation marks free programmers from the quagmire of quotation marks and special strings , Maintaining the format of a small string throughout is called WYSIWYG( What you see is what you get ) Format .
A typical use case is , When you need a piece of HTML perhaps SQL when , In this case, mark with three quotation marks , Using the traditional escape character system will be very laborious .
Unicode( Unified code 、 unicode 、 Single code ) It's a character encoding used on a computer .
Unicode It is to solve the limitation of traditional character coding scheme , It sets a uniform and unique binary encoding for each character in each language , To meet cross language needs 、 Cross platform text conversion 、 Handling requirements .1990 R & D started in ,1994 Officially announced in .
It uses all the words in the world 2 The two bytes are uniformly encoded .Unicode Use numbers 0-0x10FFFF To map these characters , Maximum capacity 1114112 Characters , Or there is 1114112 A code bit .
python2.x The default character encoding is ASCII, The default file pass code is also ASCII.
python 3.x The default character encoding is unicode, The default file code is utf-8.
therefore , In fact, the string is represented by Unicode Code is mainly used for python2.x.
say concretely , stay Python You can define a string consisting of Unicode To code .
The sample code is as follows :
str1 = u'Hello World !'
Lowercase before quotation marks "u" Indicates that what is created here is a Unicode character string . If you want to add a special character , have access to Python Of Unicode-Escape code . As shown in the following example :
str1 = u'Hello\u0020World !'
print(str1)
The running results are as follows :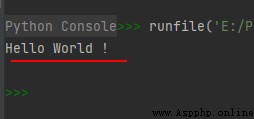
Replaced by \u0020 The identifier indicates that the code value inserted at the given position is 0x0020 Of Unicode character ( Space character ).
code :
str.encode(encoding='UTF-8',errors='strict')
encoding – What code is used to encode the string , Such as UTF-8、gb2312、gbk、 big5… etc.
errors – Set up different error handling schemes . The default is ‘strict’, A coding error causes a UnicodeError. Others may be worth ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ And by codecs.register_error() Any value registered .
decode :
str.decode(encoding='UTF-8',errors='strict')
encoding – What code is used to encode the original string , Such as UTF-8、gb2312、gbk、 big5… etc.
errors – Set up different error handling schemes . The default is ‘strict’, A coding error causes a UnicodeError. Others may be worth ‘ignore’, ‘replace’, ‘xmlcharrefreplace’, ‘backslashreplace’ And by codecs.register_error() Any value registered .
Be careful : function decode Is to decode a string into unicode code , instead of encoding Represents the code , Parameters encoding Just tell the function what my original code is .
The use examples of the above two functions are as follows :
str1 = 'this is string example'
str2 = str1.encode('big5', 'strict')
str3 = str2.decode('big5', 'strict') # take big5 Decoded into unicode code
The operation results are as follows :
str.center(width[, fillchar])
Example :
str1 = 'haohong'
str2 = str1.center(20, '*')
print(str2)
The operation results are as follows :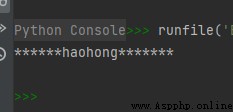
ljust() Method returns a left aligned original string , And fill the new string with spaces to the specified length . If the specified length is less than the length of the original string, return the original string .
str.ljust(width[, fillchar])
width – Specify string length .
fillchar – Fill character , Default is space .
An example is as follows :
str1 = "i love my city"
print(str1.ljust(30, '#'))
The operation results are as follows :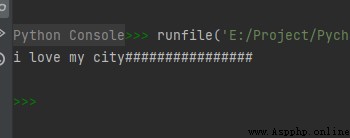
rjust() Method returns a left aligned original string , And fill the new string with spaces to the specified length . If the specified length is less than the length of the original string, return the original string .
str.rjust(width[, fillchar])
width – Specify string length .
fillchar – Fill character , Default is space .
An example is as follows :
str1 = "i love my city"
print(str1.rjust(30, '#'))
The operation results are as follows :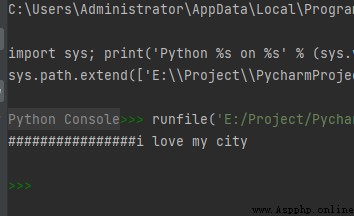
The prototype is as follows :
str.zfill(width)
The sample code is as follows :
str1 = "i love my city"
print(str1.zfill(30))
The operation results are as follows :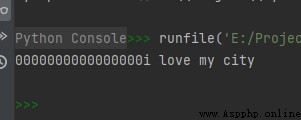
str.endswith(suffix[, start[, end]])
suffix – The parameter can be a string or an element .
start – The starting position in the string .
end – End position in character .
If the string contains the specified suffix, return True, Otherwise return to False.
The sample code is as follows :
str1 = 'this is string example'
str2 = 'example'
str3 = 'fuck'
end_bool1 = str1.endswith(str2)
end_bool2 = str1.endswith(str3)
The operation results are as follows :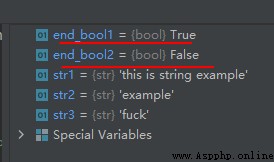
str.startswith(str, beg=0,end=len(string));
str – Detected string .
strbeg – Optional parameters are used to set the starting position of string detection .
strend – Optional parameters are used to set the end position of string detection .
Returns if a string is detected True, Otherwise return to False.
The sample code is as follows :
str1 = 'this is string example'
str2 = 'thi'
str3 = 'fuck'
end_bool1 = str1.startswith(str2)
end_bool2 = str1.startswith(str3)
The operation results are as follows :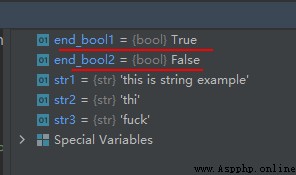
string.expandtabs(tabsize=8)
Put the string string Medium tab Turn the symbol into a space ,tab The default number of spaces for symbols is 8.
The sample code is as follows :
str1 = 'AAA\tBBB' # \t For tab
str2 = str1.expandtabs(tabsize=8)
print(str1)
print(str2)
The operation results are as follows :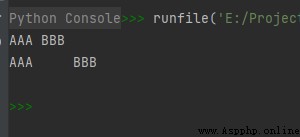
See the blog for details and usage examples https://blog.csdn.net/wenhao_ir/article/details/125390532
The sample code is as follows :
str1 = "-"
seq = ("a", "b", "c") # String sequence
print(str1.join(seq))
The operation results are as follows :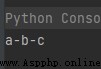
str.maketrans(intab, outtab)
The sample code is as follows :
intab = "aeiou"
outtab = "12345"
trantab = str.maketrans(intab, outtab)
str1 = "this is string example....wow!!!"
print(str1.translate(trantab))
The operation results are as follows :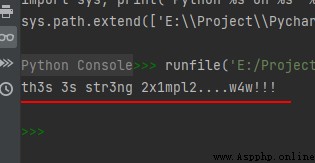
partition() Method is used to split a string according to the specified string as a delimiter .
If the string contains the specified separator , Returns a 3 A tuple of elements , The first is the substring to the left of the separator , The second is the separator itself , The third is the substring to the right of the separator .
The sample code is as follows :
str1 = "blog.csdn.net/wenhao_ir"
print(str1.partition("net/"))
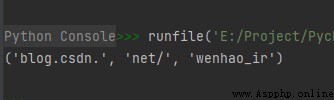
If you want to find the separator from the right , Available functions rpartition() Realization .
str.split(str="", num=string.count(str))
split() Slice a string by specifying a separator , If parameters num There is a specified value , Then separate num+1 Substring .
str – Separator , The default is all empty characters , Including Spaces 、 Line break (\n)、 tabs (\t) etc. .
num – Number of divisions . The default is -1, To separate all .
The sample code is as follows :
txt = "Google#CSDN#Taobao#Facebook"
x1 = txt.split("#")
x2 = txt.split("#", 1)
x3 = txt.split("#", 2)
print(x1)
print(x2)
print(x3)
The operation results are as follows :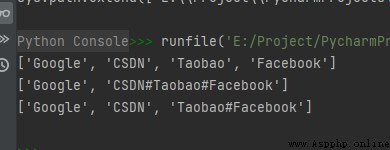
str.splitlines([keepends])
keepends – Do you want to keep line breaks in the output (‘\r’, ‘\r\n’, \n’), The default is False, Does not contain line breaks , If True, Keep the newline .
The sample code is as follows :
str1 = 'ab c\n\nde fg\rkl\r\n'
print(str1.splitlines())
str2 = 'ab c\n\nde fg\rkl\r\n'
print(str2.splitlines(True))
The operation results are as follows :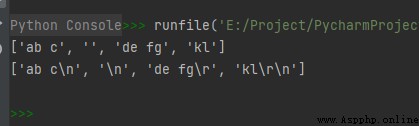
This article references from :
https://blog.csdn.net/wenhao_ir/article/details/125100220