This article mainly explains “ How to use it Python Realize translation HTML Text string in ”, Interested friends might as well come and have a look . The method introduced in this paper is simple and fast , Practical . Now let Xiaobian take you to learn “ How to use it Python Realize translation HTML Text string in ” Well !
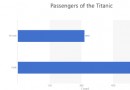
I believe everyone has used the translation function of the browser , For example, for the following English web page :
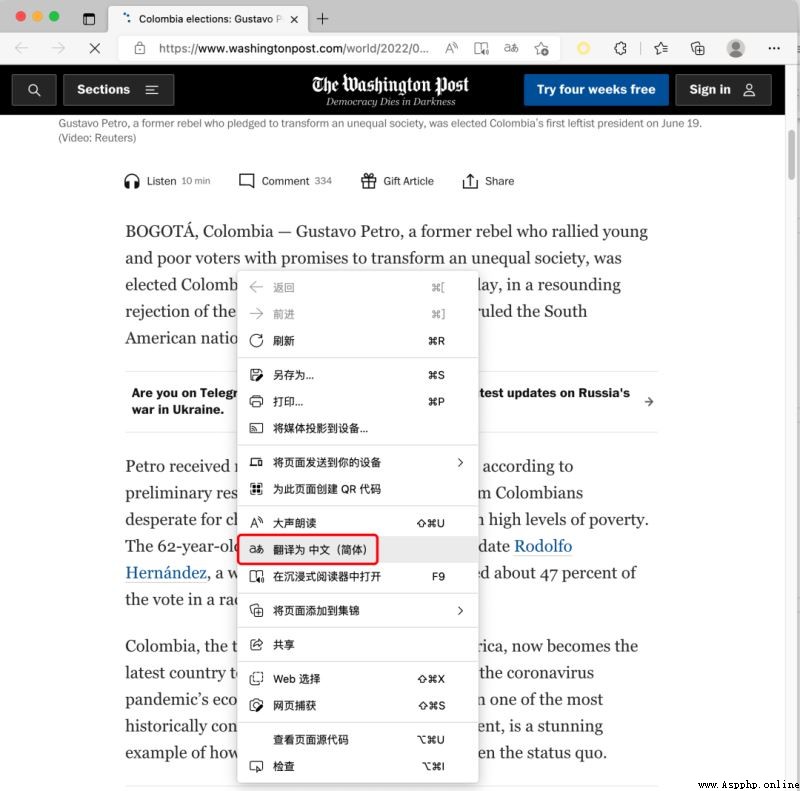
One click translation into Chinese is like this :
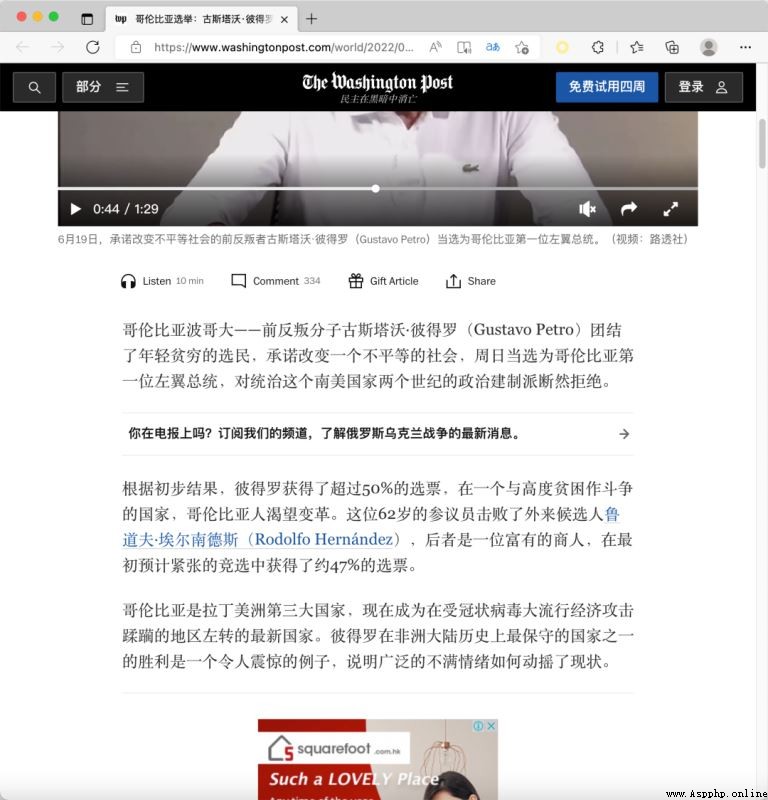
You may find this function very simple , It's just string substitution ? Then you can try the following HTML In the clip <p> The English under the label is translated into Chinese . Do not change other labels :
<div> <p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p></div>
stay <em> In the tag datetime and <span> In the tag datetime.datetime.now() There is no need to translate .
You slap your head , I immediately wrote the following lines of code ( Suppose you already have a ready-made translate() function , Incoming English , Output Chinese ):
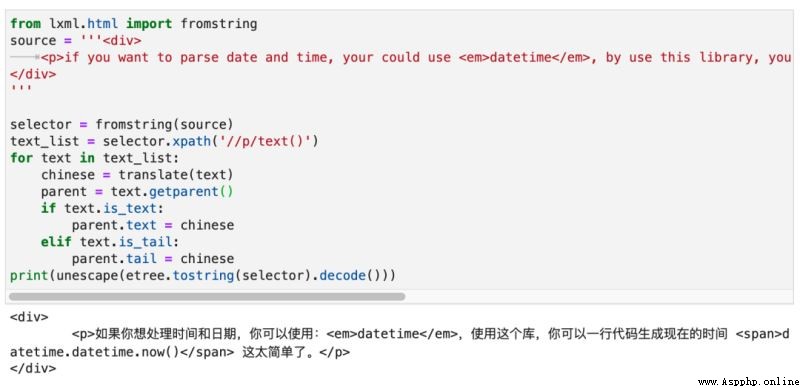
from lxml.html import fromstringsource = '''<div> <p>if you want to parse date and time, your could use <em>datetime</em>, by use this library, you can generate now time by one line code <span>datetime.datetime.now()</span> this is so easy.</p></div>'''selector = fromstring(source)text_list = selector.xpath('//p/text()')for text in text_list: chinese = translate(text) ...When you write here , You should be stunned . Because you suddenly find a problem , How to replace Chinese ?
Don't try to go to Baidu . In today's (2022-06-20) Before , The whole Chinese network , You can't find a solution .
A clumsy way is to direct the original HTML String for text substitution :
for text in text_list: chinese = translate(text) source = source.replace(text, chinese)
But to do so , Very inefficient . Because you keep scanning the whole HTML character string . Generally a medium-sized website HTML There are thousands of lines , Hundreds of thousands of characters . Every time you translate a short paragraph, you replace it with the full text , This time will be very long .
Is there any way to deal only with the current one <p> Replace the text in the tag ? Here comes the key question , You can replace , But how can it not affect this <p> Two sub Tags below the tag ? Make sure that the relative position of the text and sub tags does not change .
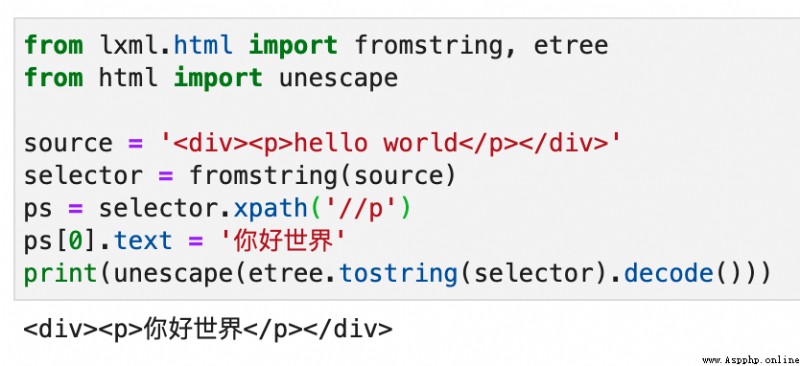
If <p> There is only one paragraph of text below the label , No sub tags , So it's very simple , As shown in the figure below :
But here's the problem ,<p> There are three paragraphs of text under the label . Other sub tags are inserted between each paragraph of text . How do we replace each paragraph of text , But keep the relative order of the text , And it can not affect the sub tags ?
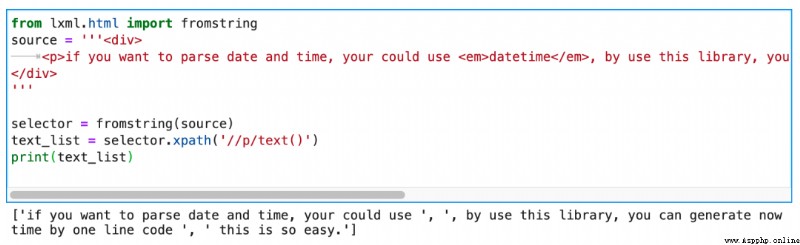
p.text This way of writing can first rule out , Because it has no way to specify which paragraph of text to replace .
The reason why you find this problem difficult to solve , Because you have an illusion , Look at the screenshot above , I printed text_list. It prints out a list of strings . So you might think . Use lxml Write Xpath When ,/text() Always return a list containing strings .
But actually , The elements in the returned list are not strings , It is _ElementUnicodeResult object . As shown in the figure below :
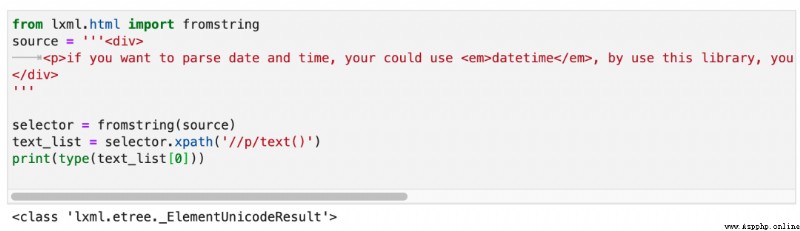
It's not just a string , Then we can get the parent tag of each text object . Then modify the text under the parent tag .
See here , You're sure to ask , The parent labels of these three text nodes , Not all the same <p> Do you ? If you think it's , Then you made the mistake of taking it for granted . Let's look at it in code :
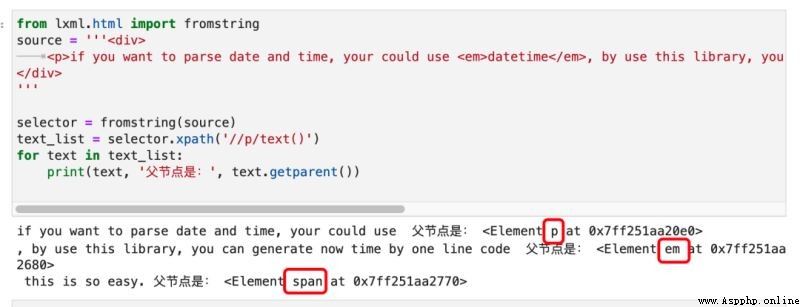
In fact, only the parent tag of the first paragraph of text is <p>. The parent label of the second paragraph of text , Turned out to be <p> The child tag of <em>. The parent label of the third paragraph of text , yes <span>.
wait , If the parent tag of the second paragraph of text is <em>, that <em>datetime</em> Inside datetime What is the parent tag of ? Its parent tag is also <em>! So here comes the question ,<em> Of text() Text node , How could it be datetime, again <p> The second paragraph below ?
actually ,<em> Of text() It's always datetime. As shown in the figure below :
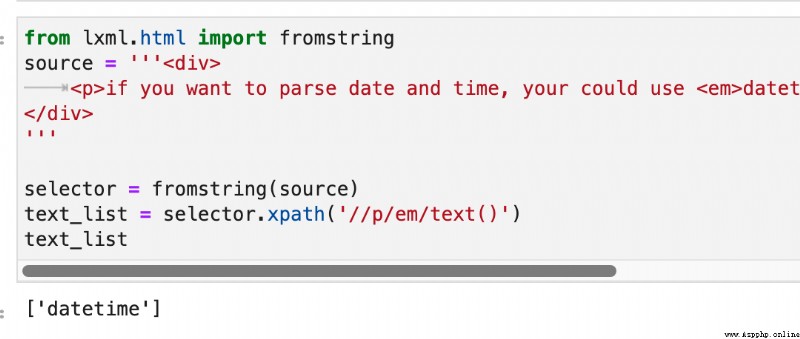
that ,<p> The second paragraph of the text follows this <em> What is the relationship between labels ? actually , This relationship is called tail. As shown in the figure below :
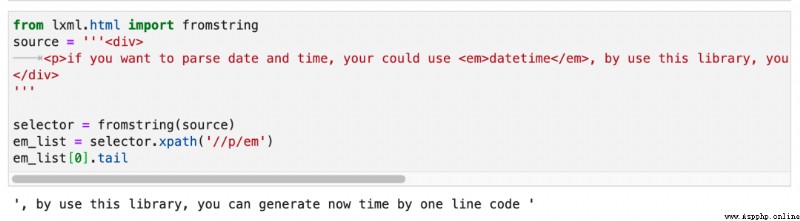
In a label , Only the first paragraph text It's really text(), If this tag has sub tags , So the text after the sub tag , It's for this sub tag tail. It's just that when we write in regular expressions /text() When ,lxml Will help us put all the sub tags tail Are counted as the current tag text.
We can use the... Of the text node .is_text and .is_tail To determine which text it belongs to . The final running effect is shown in the figure below :
Here we are , I'm sure you're right “ How to use it Python Realize translation HTML Text string in ” Have a deeper understanding of , You might as well put it into practice ! This is the Yisu cloud website , For more relevant contents, you can enter the relevant channels for inquiry , Pay attention to our , Continue to learn !