Common types of string encoding :utf-8,gb2312,cp936,gbk etc. .
python in , We use decode() and encode() To decode and encode
stay python in , Use unicode Type as the base type of encoding . namely
decode encode
str ---------> unicode --------->str
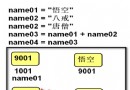
u = u' chinese ' # According to specified unicode Type object u
str = u.encode('gb2312') # With gb2312 Code pair unicode Encode images
str1 = u.encode('gbk') # With gbk Code pair unicode Encode images
str2 = u.encode('utf-8') # With utf-8 Code pair unicode Encode images
u1 = str.decode('gb2312')# With gb2312 Code for string str decode , In order to get unicode
u2 = str.decode('utf-8')# If the utf-8 Coding pairs for str The result of decoding , You will not be able to restore the original unicode type Like the code above ,str\str1\str2 Are of string type (str), It brings more complexity to string operation .
The good news is here. , That's it python3, In the new version of python3 in , To cancel the unicode type , In its place is the use of unicode Character string type (str), String type (str) Become the base type as follows , After encoding, it becomes byte type (bytes), But the use of the two functions does not change :
decode encode
bytes ------> str(unicode)------>bytes
u = ' chinese ' # Specifies a string type object u
str = u.encode('gb2312') # With gb2312 Code pair u Encoding , get bytes Type object str
u1 = str.decode('gb2312')# With gb2312 Code for string str decode , Get string type object u1
u2 = str.decode('utf-8')# If the utf-8 Coding pairs for str The result of decoding , You will not be able to restore the original string contents Inevitably , File reading problem :
Suppose we read a file , When the file is saved , The encoding format used , Determines the encoding format of the content we read from the file , for example , Let's create a new text file from Notepad test.txt, Edit content , Be careful when saving , The encoding format is optional , For example, we can choose gb2312, So use python Read file contents , The way is as follows :
f = open('test.txt','r')
s = f.read() # Read file contents , If it is unrecognized encoding Format ( Identification of the encoding The type depends on the system used ), Here, the read fails
''' Assume that the file is saved in gb2312 Encoding preservation '''
u = s.decode('gb2312') # Decode the content in a file save format , get unicode character string
''' Now we can perform various encoding transformations on the content '''
str = u.encode('utf-8')# Convert to utf-8 Encoded string str
str1 = u.encode('gbk')# Convert to gbk Encoded string str1
str1 = u.encode('utf-16')# Convert to utf-16 Encoded string str1python Provided us with a package codecs Read the file , The... In this bag open() The function can specify the type of encoding :
import codecs
f = codecs.open('text.text','r+',encoding='utf-8')# The coding format of the document must be known in advance , Here, the file code is used utf-8
content = f.read()# If open The use of encoding And the document itself encoding In case of disagreement , Then there will be an error
f.write(' The information you want to write ')
f.close()encode() and decode()