開發者自己創建的一種字體,但是恰恰是由於是自己創造的,所以我們查看網頁源代碼的時候發現是亂碼,因為我們系統識別不到。
但是又因為是前端展示,如果將常見的幾千個中文重新全部創建一遍,那麼每次訪問該網站都需要下載十幾兆的內容,所以往往只是對於數字,或者一些敏感的字進行重造。
當我們爬取網站過多的時候,是不是會發現一種情況,就是說明明在網頁看到了實際的數據,但是當你使用python爬蟲爬取下來之後,數據就變成亂碼了,識別不到是什麼內容。
比如說我們看到了網頁的數據是:價錢:100/元
但是當我們使用python爬蟲技術獲取到該頁面的html代碼之後,原來能看到的數據看不到了,是亂碼了,且我們通過所有常用的編碼格式,都無法識別,這就是這個網站的開發者為了數據保密而自行創建的一種字體。
而我們電腦並沒有存儲這個字體庫,所有無法識別到而導致的亂碼,那麼我們如果需要將亂碼轉換成明文,我們首先需要了解下如何創建字體。這是一種什麼方法。
這裡我們使用一個軟件,名字叫做FontCreator,這個軟件既可以創建字體,也可以解析字體,由於我們主要是解析,那麼我們來演示下解析吧;
軟件包獲取方法:
微信公眾號“運維家”後台回復:FontCreator
即可獲取該軟件的下載地址了;
然後我們一步步安裝之後,打開界面如下:
我們這裡選擇一個系統自帶的字體,看看打開之後是什麼樣子吧。
首先我們需要知道我們要解析哪個字體庫,這裡這裡我們選擇C:\Windows\Fonts這個目錄下的任一文件,因為這裡存放的是我們自己電腦的所有字體,選擇其一復制到其他位置;
點擊FontCreator右上角的File–Open,打開我們剛復制的字體庫,界面如下:
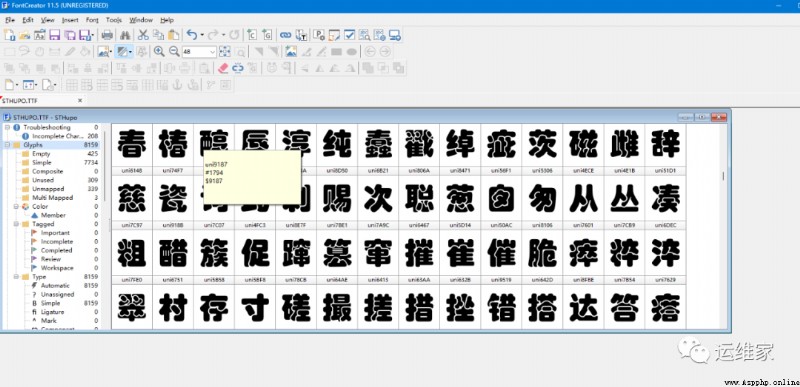
我們就可以看到有關於這個字體庫中,每一個字體的信息。
如果我們想創建一個字體,最簡單的方式就是改造已存在的,那就是雙擊改字體,出現類似界面:
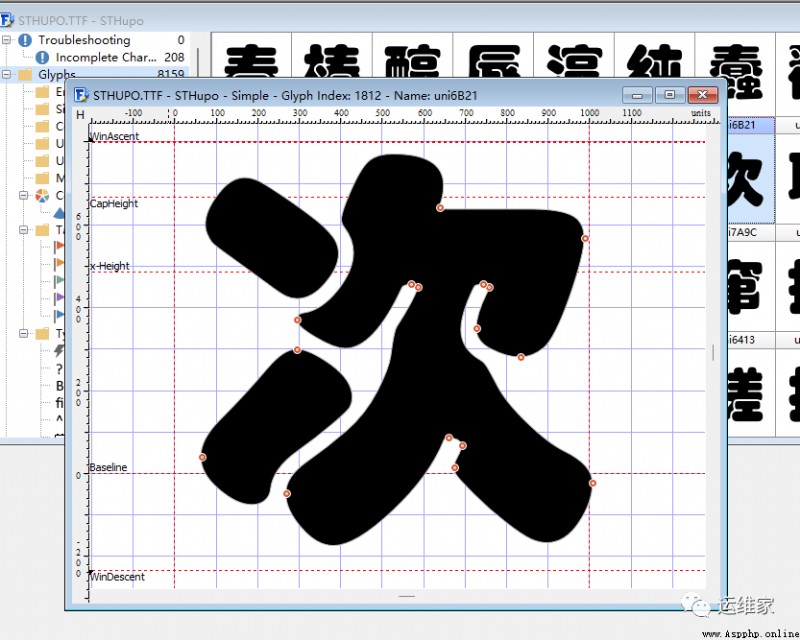
調試其中的錨點,再次保存之後,這個字體就是你獨有的了。
我們通過上面的認知之後,知道了字體是對應網站的開發者為了安全自己創建的字體了,那麼我們該如何解決這個問題呢。
這裡我們來認識四個概念;
就是說這個漢字或者數字本身的一個值;
就是說這個漢字的樣子是什麼,可以簡單的理解成一幅畫;
這個漢字在對應字體庫中的名字是什麼;
這個漢字的名字,對應的代碼是什麼;
我們在浏覽器頁面看到的,展示出來的是字體本身,查看源代碼的時候,顯示的**code*;
有兩種方法:
第一:直接生成一個新的字體庫,裡面的四要素是穩定的,不會產生變化的;
第二:每次請求都隨機生成一個新的字體庫;
針對第一種方法我們處理的時候比較簡單,直接解析好將值自行存儲起來即可;
第二種方法就比較復雜了,但是說復雜呢,也不是很復雜,因為四要素中,字體本身、形體、name,這三要素一般都不會變化,變化的僅僅是我們看到的code,那麼我們是不是可以反推出來呢?
本文只是理論知識,下一篇我們來手把手實操一下子。
支持,本文結束,相關內容每日更新。
更多內容請轉至VX公眾號 “運維家” ,獲取最新文章。
------ “運維家” ------
------ “運維家” ------
------ “運維家” ------
linux系統下,mknodlinux,linux目錄寫權限,大白菜能安裝linux嗎,linux系統創建文件的方法,領克linux系統怎麼裝軟件,linux文本定位;
ocr識別linux,linux錨定詞尾,linux系統使用記錄,u盤有linux鏡像文件,應屆生不會Linux,linux內核64位,linux自啟動管理服務;
linux計算文件夾大小,linux設備名稱有哪些,linux能用的虛擬機嗎,linux系統進入不了命令行,如何創建kalilinux,linux跟so文件一樣嗎。