由於日常開發場景中經常涉及到關於正則匹配,比如設備采集信息,篩選配置文件,過濾相關網頁元素等,所有針對Python中正則匹配的Re模塊,需要總結和梳理的地方挺多。這篇文章主要是歸納平時會經常使用到的一些函數,以及在使用過程中會遇到的坑。
正則匹配的使用心得:
關於正則表達式語法,不再贅述,可以參考網上的文檔,這裡具體不做總結;
re模塊是Python用來處理正則表達式匹配操作的模塊。
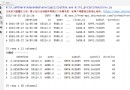
re.search(pattern, string, flags=0)
import re
text= "Hello, World!"
re.search("[A-Z]", text)
備注:
re.match(pattern, string, flags=0)
re.fullmatch(pattern, string, flags=0)
import re
text="Hello,World"
re.match("[a-z]", text)
re.fullmatch("\S+", text)
備注:
re.split(pattern, string, maxsplit=0, flags=0)
import re
text = "aJ33Sjd3231ssfj22323SSdjdSSSDddss"
re.split("([0-9]+)", text)
re.split("[0-9]+", text)
備注:
re.findall(pattern, string, flags=0)
re.finditer(pattern, string, flags=0)
import re
text = "aJ33Sjd3231ssfj22323SSdjdSSSDddss"
a = re.findall("[0-9]+", text)
print(a)
b = re.finditer("[0-9]+", text)
for i in b:
print(i.group())
備注:
匹配對象;
re.sub(pattern, repl, string, count=0, flags=0)
re.subn(pattern, repl, string, count=0, flags=0)
text = "aJ33Sjd3231ssfj22323SSdjdSSSDddss"
a = re.sub("[0-9]", "*", text)
b = re.subn("[0-9]", "*", text)
print(a)
print(b)
備注:
re.compile(pattern, flags=0)
import re
prog = re.compile("\<div[\s\S]*?class=\"([\s\S]*?)\"[\s\S]*?\>")
text = '<div class="tab" >'
prog.search(text)
prog.findall(text)
備注:
當常用函數或者正則表達對象匹配搜索返回的_sre.SRE_Match對象則稱為匹配對象
Match.group([gourp1,…])
Match.groups(default=None)
Match.groupdict(default=None)
import re
a = "Hello, World, root"
b = re.search("(\w+), (\w+), (?P<name>\w+)", a)
print(b.group(0))
print(b.group(1))
print(b.groups())
print(b.groupdict())
備注:
正則表達式的適用范圍還是十分廣泛的,希望這篇文章能對你學習Python有所幫助!