Resource download address :https://download.csdn.net/download/sheziqiong/85719088
New technology in Visual Question Answering Application in
Abstract
Visual Question Answer (VQA) It is a natural language question and answer to visual images , As a visual understanding (Visual Understanding) A research direction of , Connecting vision and language . The format of the problem is to give a picture , And ask questions about this picture , Get the answer to this question .
Used BOW Word bag model and Word To Vector Word matrix technology to deal with label And the input word vector , And LSTM The Internet and Attention Mechanism ,VIS+LSTM Network structure , Set the VQA A new model of the problem . In our model , Have 3 individual LSTM The network processes : Text , Images , Text and images . In the visual output , The correct answer is Top5 The answer is highly likely .
key word : BOW Word To Vector LSTM Attention VIS+LSTM VQA
Catalog
1 Problem specification 1
1.1 The problem background 1
2 Problem analysis 1
3 guess 1
4 Model building 1
4.1 Model overview 3
4.1.1 Use of data sets 3
4.2 VGG19 Model 3
4.2.1 VGG19 Effect analysis 3
4.2.2 VGG19 Parametric analysis 3
4.3 LSTM Model 3
4.3.1 LSTM Effect analysis 3
4.3.2 LSTM Parametric analysis 3
4.4 Word To Vector Model 3
4.4.1 Word To Vector Effect analysis 3
4.5 Comprehensive model analysis 4
5 Effect of model 4
6 The improvement of the model 5
quote 6
1 Problem specification
1.1 The problem background
Visual Question Answer (VQA) It is a natural language question and answer to visual images , As a visual understanding (Visual Understanding) A research direction of , Connecting vision and language , Models need to be based on understanding images , Answer the specific questions .
With the continuous development of deep learning , We have to VQA The answer to the question has also made a leap . From the early VIS+LSTM Model [1] And its variants VIS+ two-way LSTM The Internet , Up to now attention Mechanism [2], There are also knowledge bases such as the outer chain and Word To Vector The development of , Undoubtedly, they have greatly promoted our research . This article will use several ideas including but not just the above , Design our own VQA Model , The innovation lies in , We have used many new technologies at the same time , It uses receptors in different dimensions to sense space and entity respectively , And cleverly integrate them .
2 Problem analysis
solve VQA Problems need to be solved NLP+CV Only through joint cooperation can , So our main frame is still closely around visual perception + The direction of naturallanguageprocessing .
among , We use a trained VGG19 Network as a visual sensor , And use LSTM The Internet deals with our problems . stay LSTM Before processing , We will use Word To Vector Model of , Use Wikipedia sentences to train word vectors , And build a dictionary , Map each English word to a 300 Dimensional vector space .
The data set we currently have is a very large data set COCO-QA, Its training set has 80000 More pictures , The test set has 80000 More pictures , Validation sets also have 40000 More pictures , Each picture has a number of problems , Each question has 10 answer , And the confidence level of each answer is marked .
3 guess
We conjecture that LSTM The result of the last output layer of the network contains the information of the problem, which can well generate the spatial sensor and the category sensor , Used to add attention Mechanism . This attention We loaded the image into VGG19 On the pool layer in front of the first full connection layer output after the network . We hope that these two receptors can sense the objects and spatial location information we want .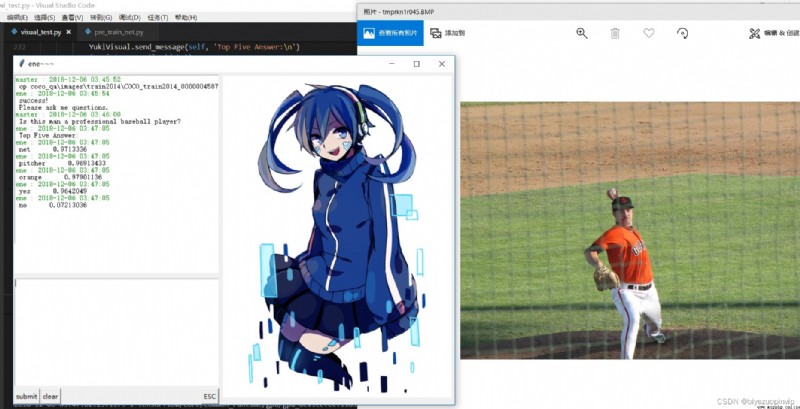



Resource download address :https://download.csdn.net/download/sheziqiong/85719088