Recently, the national college entrance examination ended , The candidates are all in the middle of the grade , Since I have always had an idea , Crawling through the information of colleges and Universities , Convenient for candidates to choose , So I finished the following code , Climbed the whole country 2822 Colleges and universities , Including undergraduate and higher vocational colleges , The score line in each province .
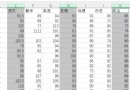
The following figure shows the universities in Hubei Province , After the ranking of soft subjects in Colleges and universities, nearly 3 Annual admission scores :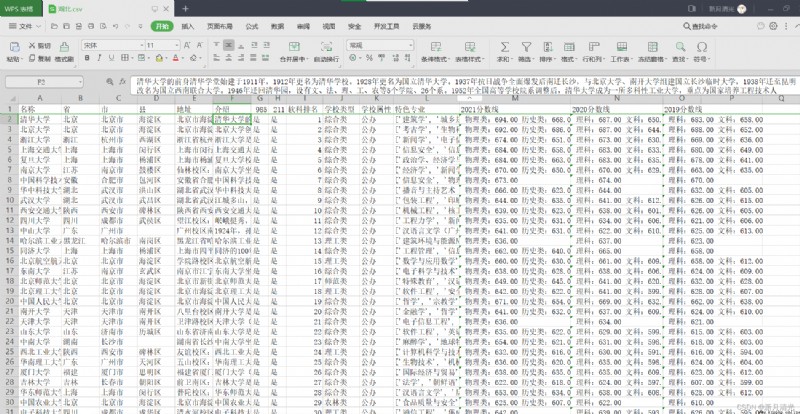
Complete data download address :
link :https://pan.baidu.com/s/1uohDZQk2SPSjI0htZBJd1g
Extraction code :z1db
The score column in the data , Blank space , It means that the school does not recruit students in the province .
Part of the code is as follows , Not optimized …
from ast import Str
from time import sleep
import requests
import json
import csv
from sqlalchemy import null
def save_data(s,data):
with open('./'+s+'.csv', encoding='UTF-8', mode='a+',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(data)
f.close()
print("#########"
" copyright : Yinzongmin & Data interface source -https://www.gaokao.cn/school/search & Thank you !"
"##########")
url = 'https://static-data.gaokao.cn/www/2.0/school/name.json'
html = requests.get(url).text
unicodestr=json.loads(html) # take string Turn into dict
dat = unicodestr["data"]
province_id=[{"name":11,"value":" Beijing "},{"name":12,"value":" tianjin "},{"name":13,"value":" hebei "},{"name":14,"value":" shanxi "},{"name":15,"value":" Inner Mongolia "},{"name":21,"value":" liaoning "},{"name":22,"value":" Ji Lin "},{"name":23,"value":" heilongjiang "},{"name":31,"value":" Shanghai "},{"name":32,"value":" jiangsu "},{"name":33,"value":" Zhejiang "},{"name":34,"value":" anhui "},{"name":35,"value":" fujian "},{"name":36,"value":" jiangxi "},{"name":37,"value":" Shandong "},{"name":41,"value":" Henan "},{"name":42,"value":" hubei "},{"name":43,"value":" hunan "},{"name":44,"value":" guangdong "},{"name":45,"value":" guangxi "},{"name":46,"value":" hainan "},{"name":50,"value":" Chongqing "},{"name":51,"value":" sichuan "},{"name":52,"value":" guizhou "},{"name":53,"value":" yunnan "},{"name":54,"value":" Tibet "},{"name":61,"value":" shaanxi "},{"name":62,"value":" gansu "},{"name":63,"value":" qinghai "},{"name":64,"value":" ningxia "},{"name":65,"value":" xinjiang "}]
for l in province_id:
header = [' name ', ' province ', ' City ', ' county ', ' Address ',' Introduce ' ,'985','211',' Soft science ranking ',' School type ',' School attribute ',' Specialty ',"2021 Fraction line ","2020 Fraction line ","2019 Fraction line "]
with open('./'+l["value"]+'.csv', encoding='utf-8-sig', mode='w',newline='') as f:
f_csv = csv.writer(f)
f_csv.writerow(header)
f.close()
for i in dat:
schoolid = i['school_id']
schoolname = i['name']
url1 = 'https://static-data.gaokao.cn/www/2.0/school/'+schoolid+'/info.json'
print(" Downloading "+schoolname)
html1 = requests.get(url1).text
unicodestr1=json.loads(html1) # take string Turn into dict
if len(unicodestr1) !=0:
dat1 = unicodestr1["data"]
name = dat1["name"]
content = dat1["content"]
f985 = dat1["f985"]
if f985 =="1":
f985 = " yes "
else:
f985 = " no "
f211 = dat1["f211"]
if f211 =="1":
f211 = " yes "
else:
f211 = " no "
ruanke_rank = dat1["ruanke_rank"]
if ruanke_rank=='0':
ruanke_rank =''
type_name= dat1["type_name"]
school_nature_name = dat1["school_nature_name"]
province_name = dat1["province_name"]
city_name = dat1["city_name"]
town_name = dat1["town_name"]
address = dat1["address"]
special =[]
for j in dat1["special"]:
special.append(j["special_name"])
pro_type_min=dat1["pro_type_min"]
fen2021=''
fen2020=''
fen2019=''
for k in pro_type_min.keys():
# print(k)
# print(l["name"])
if int(k) == l["name"]:
print(pro_type_min[k])
for m in pro_type_min[k]:
if m['year'] == 2021:
s = ' '
for j in m['type'].keys():
if j == '2073':
s = s+' Physics :'+m['type'][j] +' '
if j == '2074':
s = s+' History :'+m['type'][j] +' '
if j == '1':
s = s+' science :'+m['type'][j] +' '
if j == '2':
s = s+' Liberal arts :'+m['type'][j] +' '
if j == '3':
s = s+' comprehensive :'+m['type'][j] +' '
fen2021 = s
elif m['year'] == 2020:
s = ' '
for j in m['type'].keys():
if j == '2073':
s = s+' Physics :'+m['type'][j] +' '
if j == '2074':
s = s+' History :'+m['type'][j] +' '
if j == '1':
s = s+' science :'+m['type'][j] +' '
if j == '2':
s = s+' Liberal arts :'+m['type'][j] +' '
if j == '3':
s = s+' comprehensive :'+m['type'][j] +' '
fen2020 = s
else:
s = ' '
for j in m['type'].keys():
if j == '2073':
s = s+' Physics :'+m['type'][j] +' '
if j == '2074':
s = s+' History :'+m['type'][j] +' '
if j == '1':
s = s+' science :'+m['type'][j] +' '
if j == '2':
s = s+' Liberal arts :'+m['type'][j] +' '
if j == '3':
s = s+' comprehensive :'+m['type'][j] +' '
fen2019 = s
tap = (name,province_name,city_name,town_name,address,content,f985,f211,ruanke_rank,type_name,school_nature_name,special,fen2021,fen2020,fen2019)
save_data(l["value"],tap)