資源下載地址:https://download.csdn.net/download/sheziqiong/85697758
資源下載地址:https://download.csdn.net/download/sheziqiong/85697758
分四個方面去闡述
數據處理
特征工程
選擇的模型
集成的方法
刪除與目標值無關的列,例如“SaleID”,“name”。這裡可以挖掘一下“name”的長度作為新的特征。
異常點處理,刪除訓練集特有的數據,例如刪除“seller”==1 的值。
缺失值處理,分類特征填充眾數,連續特征填充平均值。
其他特別處理,把取值無變化的列刪掉。
異常值處理,按照題目要求“power”位於 0~600,因此把“power”>600 的值截斷至 600,把"notRepairedDamage"的非數值的值替換為 np.nan,讓模型自行處理。
時間地區類 從“regDate”,“creatDate”可以獲得年、月、日等一系列的新特征,然後做差可以獲得使用年長和使用天數這些新特征。
“regionCode”沒有保留。
因為嘗試了一系列方法,並且發現了可能會洩漏“price”,因此最終沒保留該特征。
分類特征 對可分類的連續特征進行分桶,kilometer 是已經分桶了。
然後對"power"和"model"進行了分桶。
使用分類特征“brand”、“model”、“kilometer”、“bodyType”、“fuelType”與“price”、“days”、“power”進行特征交叉。
交叉主要獲得的是後者的總數、方差、最大值、最小值、平均數、眾數、峰度等等
這裡可以獲得非常多的新特征,挑選的時候,直接使用 lightgbm 幫我們去選擇特征,一組組的放進去,最終保留了以下特征。(注意:這裡是使用 1/4 的訓練集進行挑選可以幫助我們更快的鎖定真正 Work 的特征)
'model_power_sum','model_power_std','model_power_median', 'model_power_max','brand_price_max', 'brand_price_median','brand_price_sum', 'brand_price_std','model_days_sum','model_days_std','model_days_median', 'model_days_max','model_amount','model_price_max','model_price_median','model_price_min','model_price_sum', 'model_price_std', 'model_price_mean'連續特征 使用了置信度排名靠前的匿名特征“v_0”、“v_3”與“price”進行交叉,測試方法以上述一樣,效果並不理想。
因為都是匿名特征,比較訓練集和測試集分布,分析完基本沒什麼問題,並且它們在lightgbm 的輸出的重要性都是非常高的,所以先暫且全部保留。
補充特征工程 主要是對輸出重要度非常高的特征進行處理
特征工程一期:
對 14 個匿名特征使用乘法處理得到 14*14 個特征
使用 sklearn 的自動特征選擇幫我們去篩選,大概運行了半天的時間。大致方法如下:
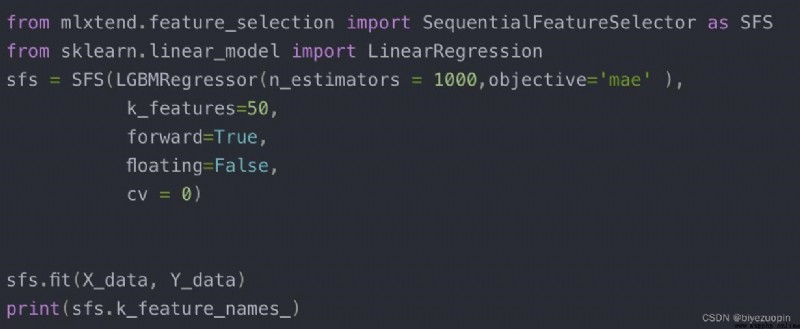
最終篩選得到:
'new3*3', 'new12*14', 'new2*14','new14*14' 特征工程二期:
對 14 個匿名特征使用加法處理得到 14*14 個特征
這次不選擇使用自動特征選擇了,因為運行實在太慢了,筆記本耗不起。
然後先嘗試了全部放進去 lightgbm 訓練是否有效,驚喜的發現效果很明顯,由於新生成的特征很多,因此要對一部分冗余的特征進行刪除。
使用的方法是刪除相關性高的變量,把要刪除的特征記錄下來大致方法如下:(剔除相關度>0.95 的)
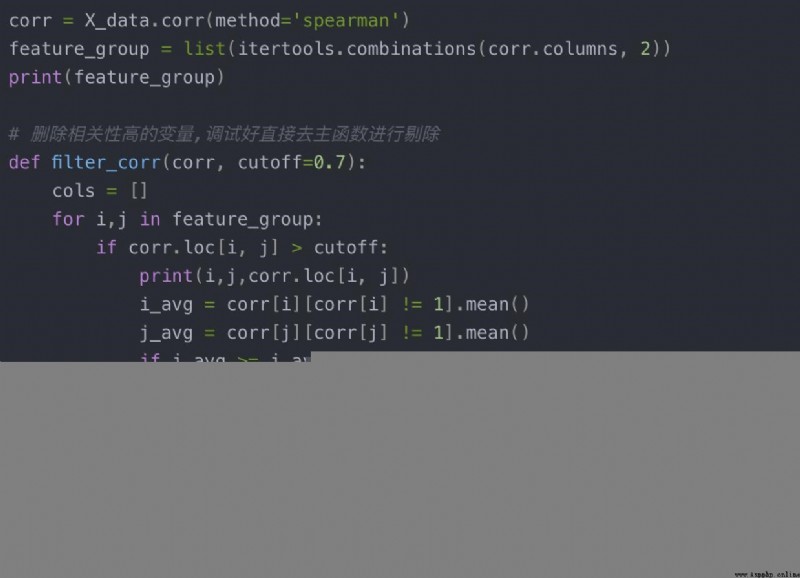
最終獲得的應該刪除的特征為:
['new14+6', 'new13+6', 'new0+12', 'new9+11', 'v_3', 'new11+10', 'new10+14','new12+4', 'new3+4', 'new11+11', 'new13+3', 'new8+1', 'new1+7', 'new11+14','new8+13', 'v_8', 'v_0', 'new3+5', 'new2+9', 'new9+2', 'new0+11', 'new13+7', 'new8+11','new5+12', 'new10+10', 'new13+8', 'new11+13', 'new7+9', 'v_1', 'new7+4', 'new13+4', 'v_7', 'new5+6', 'new7+3', 'new9+10', 'new11+12', 'new0+5', 'new4+13', 'new8+0', 'new0+7', 'new12+8', 'new10+8', 'new13+14', 'new5+7', 'new2+7', 'v_4', 'v_10','new4+8', 'new8+14', 'new5+9', 'new9+13', 'new2+12', 'new5+8', 'new3+12', 'new0+10','new9+0', 'new1+11', 'new8+4', 'new11+8', 'new1+1', 'new10+5', 'new8+2', 'new6+1','new2+1', 'new1+12', 'new2+5', 'new0+14', 'new4+7', 'new14+9', 'new0+2', 'new4+1','new7+11', 'new13+10', 'new6+3', 'new1+10', 'v_9', 'new3+6', 'new12+1', 'new9+3','new4+5', 'new12+9', 'new3+8', 'new0+8', 'new1+8', 'new1+6', 'new10+9', 'new5+4', 'new13+1', 'new3+7', 'new6+4', 'new6+7', 'new13+0', 'new1+14', 'new3+11', 'new6+8', 'new0+9', 'new2+14', 'new6+2', 'new12+12', 'new7+12', 'new12+6', 'new12+14', 'new4+10', 'new2+4', 'new6+0', 'new3+9', 'new2+8', 'new6+11', 'new3+10', 'new7+0','v_11', 'new1+3', 'new8+3', 'new12+13', 'new1+9', 'new10+13', 'new5+10', 'new2+2','new6+9', 'new7+10', 'new0+0', 'new11+7', 'new2+13', 'new11+1', 'new5+11', 'new4+6', 'new12+2', 'new4+4', 'new6+14', 'new0+1', 'new4+14', 'v_5', 'new4+11', 'v_6', 'new0+4','new1+5', 'new3+14', 'new2+10', 'new9+4', 'new2+6', 'new14+14', 'new11+6', 'new9+1', 'new3+13', 'new13+13', 'new10+6', 'new2+3', 'new2+11', 'new1+4', 'v_2', 'new5+13','new4+2', 'new0+6', 'new7+13', 'new8+9', 'new9+12', 'new0+13', 'new10+12', 'new5+14', 'new6+10', 'new10+7', 'v_13', 'new5+2', 'new6+13', 'new9+14', 'new13+9','new14+7', 'new8+12', 'new3+3', 'new6+12', 'v_12', 'new14+4', 'new11+9', 'new12+7','new4+9', 'new4+12', 'new1+13', 'new0+3', 'new8+10', 'new13+11', 'new7+8','new7+14', 'v_14', 'new10+11', 'new14+8', 'new1+2']]特征工程三、四期 :
這兩期的效果不明顯,為了不讓特征冗余,所以選擇不添加這兩期的特征,具體的操作可以在 feature 處理的代碼中看到。
在對於其他缺失值的填充,在測試了效果後,發現填充眾數的效果比平均數更好,因此均填充眾數。
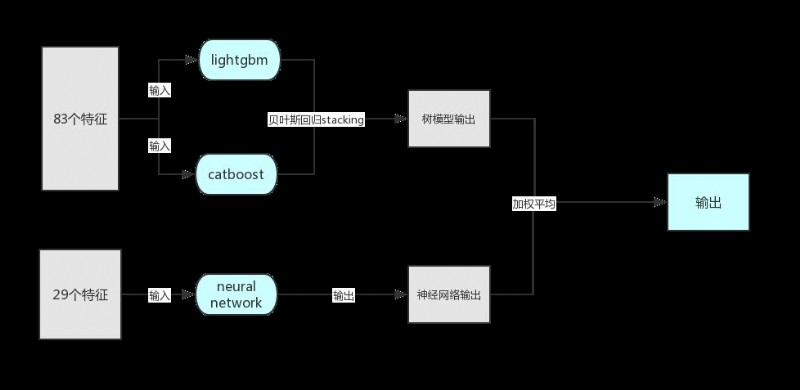
本次比賽,我選擇的是 lightgbm+catboost+neural network。
本來也想使用 XGBoost 的,不過因為它需要使用二階導,因此目標函數沒有 MAE,並且嘗試了逼近 MAE 的一些自定義函數效果也不理想,因此沒有選擇使用它。
經過上述的數據預處理以及特征工程:
樹模型的輸入有 83 個特征;神經網絡的輸入有 29 個特征。
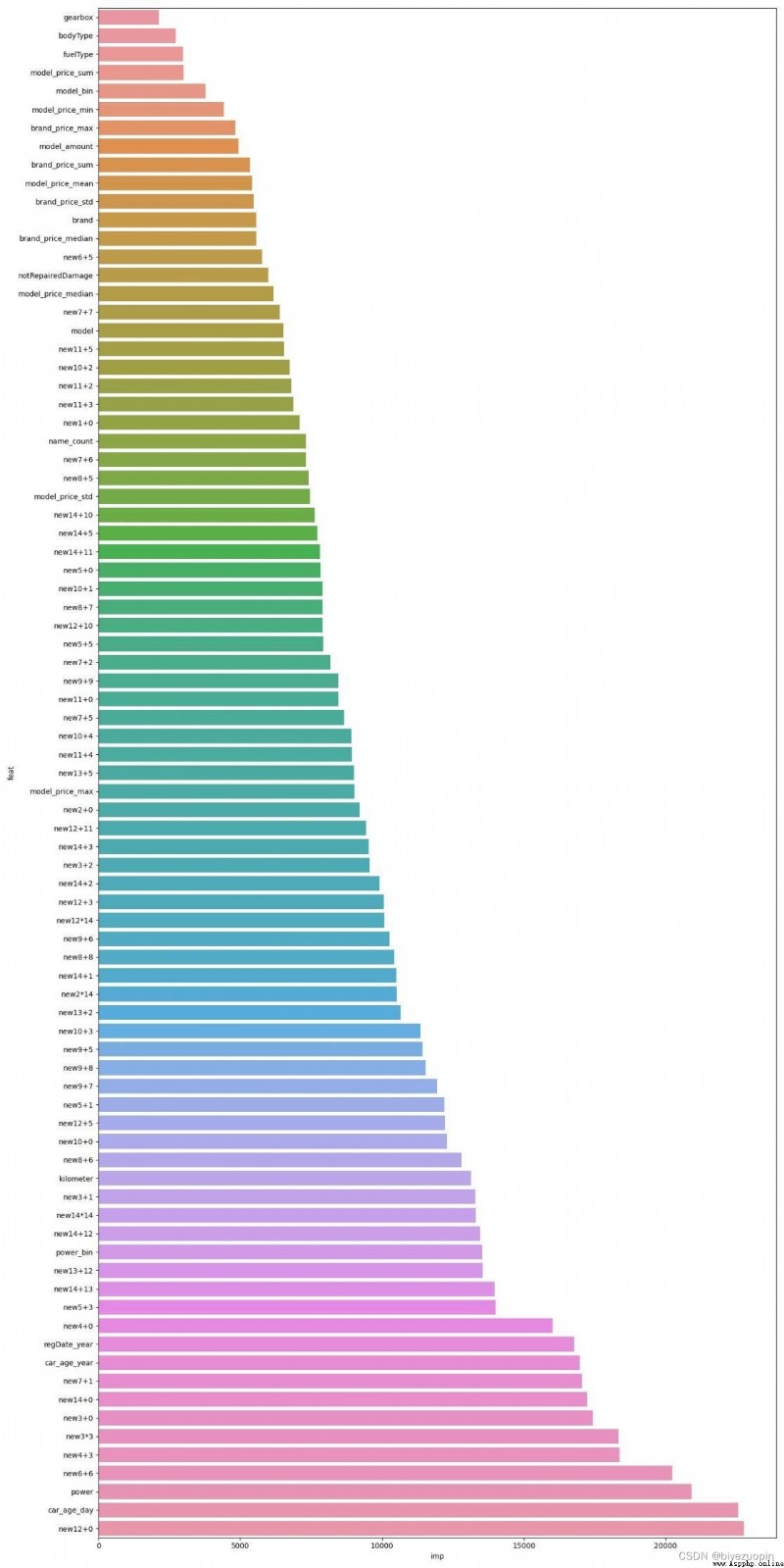
neural network:
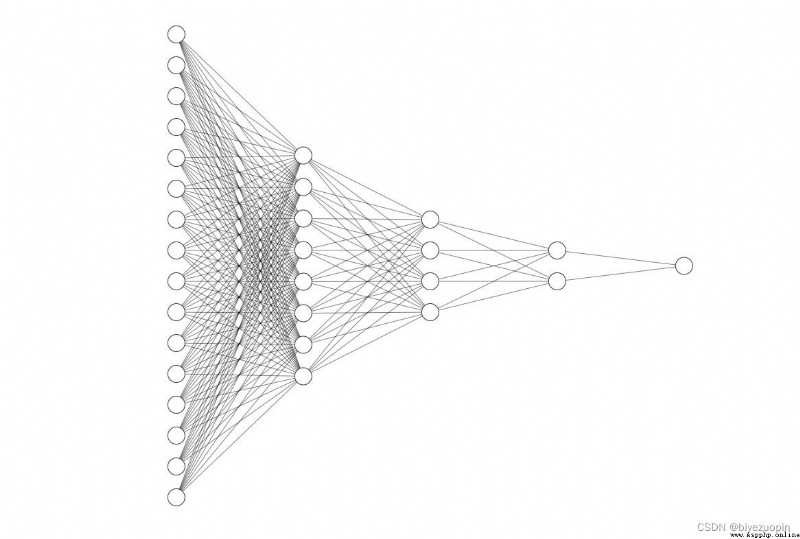
我針對該比賽,自己設計了一個五層的神經網絡,大致框架如上圖所示,但結點數由於太多只是展示部分結點畫圖。
以下為全連接層的結點個數設置,具體實現可參考代碼。

接下來對神經網絡進行具體分析:
第一:訓練模型使用小 batchsize,512,雖然在下降方向上可能會出現小偏差,但是對收斂速度的收益大,2000 代以內可以收斂。
第二:神經網絡對於特征工程這一類不用操心很多,就能達到與樹模型相差無幾的精度。
第三:調整正則化系數,使用正則化,防止過擬合。
第四:調整學習率,對訓練過程的誤差進行分析,選擇學習率下降的時機進行調整。
第五:使用交叉驗證,使用十折交叉驗證,減小過擬合。
第六:選擇梯度下降的優化器為 Adam,它是目前綜合能力較好的優化器,具備計算高效,對內存需求少等等優點。
由於兩個樹模型的訓練數據一樣且結構相似,首先對兩個樹模型進行 stacking,然後再與神經網絡的輸出進行 mix。
由於樹模型和神經網絡是完全不同的架構,它們得到的分數輸出相近,預測值差異較大,往往在 MAE 上差異為 200 左右,因此將他們進行 MIX 可以取到一個更好的結果,加權平均選擇系數選擇 0.5,雖然神經網絡的分數確實會比樹模型高一點點,但是我們的最高分是多組線上最優輸出的結合,因此可以互相彌補優勢。
給出的代碼是一次輸出的結果,如若完美復現線上結果,得多輸出幾次選取Top-3求平均。
由於後期上分選擇了十折交叉驗證和非常小的學習率,運行較慢,大家可以先使用五折和較大學習率測試效果~
|--data訓練集、測試集,可從比賽官網下載
|--user_data代碼中途生成的一些文件,比賽過程中方便觀察
|--prediction_result輸出的提交文本
|--feature|--model |--code 執行:(進入該目錄,執行以下命令即可產生一份預測數據) python main.py PS:其實 main 是我把 feature 和 model 的代碼全都復制扔了進去。
資源下載地址:https://download.csdn.net/download/sheziqiong/85697758
資源下載地址:https://download.csdn.net/download/sheziqiong/85697758
作者:biyezuopin
游戲編程,一個游戲開發收藏夾~
如果圖片長時間未顯示,請使用Chrome內核浏覽器。