1.Series
1.1通過列表創建Series
1.2通過字典創建Series
2.DataFrame
3.索引對象
4.查看DataFrame的常用屬性
前言:
Pandas有三種數據結構:Series、DataFrame和Panel。Series類似於數組;DataFrame類似於表格;Panel可視為Excel的多表單Sheet
1.SeriesSeries是一種一維數組對象,包含一個值序列,並且包含數據標簽,稱為索引(index),通過索引來訪問數組中的數據。
1.1通過列表創建Series例1.通過列表創建
import pandas as pdobj = pd.Series([1,-2,3,4]) #僅由一個數組構成print(obj)輸出:
0 1
1 -2
2 3
3 4
dtype: int64
輸出的第一列為index,第二列為數據value。如果創建Series時沒有指定index,Pandas會采用整型數據作為該Series的index。也可以使用Python裡的索引index和切片slice技術
例2.創建Series時指定索引
import pandas as pdi = ["a","c","d","a"]v = [2,4,5,7]t = pd.Series(v,index=i,name="col")print(t)out:
a 2
c 4
d 5
a 7
Name: col, dtype: int64
盡管創建Series指定了index,實際上Pandas還是有隱藏的index位置信息。所以Series有兩套描述某條數據手段:位置和標簽
例3.Series位置和標簽的使用
import pandas as pdval = [2,4,5,6]idx1 = range(10,14)idx2 = "hello the cruel world".split()s0 = pd.Series(val)s1 = pd.Series(val,index=idx1)t = pd.Series(val,index=idx2)print(s0.index)print(s1.index)print(t.index)print(s0[0])print(s1[10])print('default:',t[0],'label:',t["hello"])1.2通過字典創建Series如果數據被存放在一個Python字典中,也可以直接通過這個字典來創建Series
例4.通過字典創建Series
import pandas as pdsdata = {'Ohio':35000,'Texass':71000,'Oregon':16000,'Utah':5000}obj = pd.Series(sdata)print(obj)Ohio 35000
Texass 71000
Oregon 16000
Utah 5000
dtype: int64
如果只傳入一個字典,則結果Series中的索引就是原字典的鍵(有序排列)
例5.通過字典創建Series時的索引
import pandas as pdsdata = {"a":100,"b":200,"e":300}obj = pd.Series(sdata)print(obj)a 100
b 200
e 300
dtype: int64
如果字典中的鍵值和指定的索引不匹配,則對應的值時NaN
例6.鍵值和指定索引不匹配
import pandas as pdsdata = {"a":100,"b":200,"e":300}letter = ["a","b","c","e"]obj = pd.Series(sdata,index=letter)print(obj)a 100.0
b 200.0
c NaN
e 300.0
dtype: float64
對於許多應用而言,Series重要的一個功能是:它在算術運算中會自動對齊不同索引的數據
例7.不同索引數據的自動對齊
import pandas as pdsdata = {'Ohio':35000,'Texas':71000,'Oregon':16000,'Utah':5000}obj1 = pd.Series(sdata)states = ['California','Ohio','Oregon','Texas']obj2 = pd.Series(sdata,index=states)print(obj1+obj2)California NaN
Ohio 70000.0
Oregon 32000.0
Texas 142000.0
Utah NaN
dtype: float64
Series的索引可以通過賦值的方式就地修改
例8.Series索引的修改
import pandas as pdobj = pd.Series([4,7,-3,2])obj.index = ['Bob','Steve','Jeff','Ryan']print(obj)2.DataFrameBob 4
Steve 7
Jeff -3
Ryan 2
dtype: int64
DataFrame是一個表格型的數據結構,它含有一組有序的列,每列可以是不同類型的值(數值、字符串、布爾值等)。DataFrame既有行索引也有列索引,它可以被看作由Series組成的字典(共用同一個索引)。跟其他類型的數據結構相比,DataFrame中面向行和面向列的操作上基本上是平衡的
構建DataFrame的方式有很多,最常用的是直接傳入一個由等長列表或NumPy數組組成的字典來形成DataFrame
例9.DataFrame的創建
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data)print(df)name sex year city
0 張三 female 2001 北京
1 李四 female 2001 上海
2 王五 male 2003 廣州
3 小明 male 2002 北京
DataFrame會自動加上索引(跟Series一樣),且全部列會被有序排列。如果指定了列名序列,則DataFrame的列就會按照指定順序進行排列
例10.DataFrame的索引
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city'])print(df)name year sex city
0 張三 2001 female 北京
1 李四 2001 female 上海
2 王五 2003 male 廣州
3 小明 2002 male 北京
跟Series一樣,如果傳入的列在數據中找不到,就會產生NaN值。
例11.DataFrame創建時的空缺值
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city','address'])print(df)name year sex city address
0 張三 2001 female 北京 NaN
1 李四 2001 female 上海 NaN
2 王五 2003 male 廣州 NaN
3 小明 2002 male 北京 NaN
DataFrame構造函數的columns函數給出列的名字,index給出label標簽
例12.DataFrame構建時指定列名
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city','address'],index = ['a','b','c','d'])print(df)3.索引對象name year sex city address
a 張三 2001 female 北京 NaN
b 李四 2001 female 上海 NaN
c 王五 2003 male 廣州 NaN
d 小明 2002 male 北京 NaN
Pandas的索引對象負責管理軸標簽和其他元數據(例如軸名稱等).構建Series或DataFrame時,所用到的任何數組或其他序列的標簽都會被轉換成一個Index
例13.顯示DataFrame的索引和列
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city','address'],index = ['a','b','c','d'])print(df)print(df.index)print(df.columns)name year sex city address
a 張三 2001 female 北京 NaN
b 李四 2001 female 上海 NaN
c 王五 2003 male 廣州 NaN
d 小明 2002 male 北京 NaN
Index(['a', 'b', 'c', 'd'], dtype='object')
Index(['name', 'year', 'sex', 'city', 'address'], dtype='object')
索引對象不能進行修改,否則會報錯。不可修改性非常重要,因為這樣才能使Index對象在多個數據結構之間安全共享
除了長的像數組,Index的功能也類似於一個固定大小的集合
例14.DataFrame的Index
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city','address'],index = ['a','b','c','d'])print('name'in df.columns)print('a'in df.index)True
True
每個索引都有一些方法和屬性,他們可用於設置邏輯並回答有關該索引所包含的數據的常見的問題。
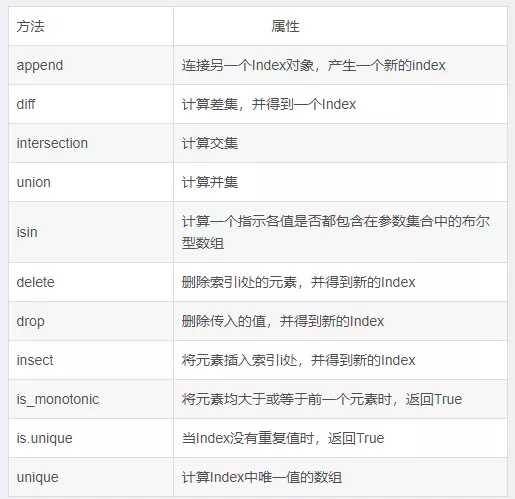
例15.插入索引值
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city','address'],index = ['a','b','c','d'])df.index.insert(1,'w')Index(['a', 'w', 'b', 'c', 'd'], dtype='object')4.查看DataFrame的常用屬性DataFrame的基礎屬性有value、index、columns、dtypes、ndim和shape,分別可以獲取DataFrame的元素、索引、列名、類型、維度和形狀。
例16.顯示DataFrame的屬性
import pandas as pddata = { 'name':['張三','李四','王五','小明'], 'sex':['female','female','male','male'], 'year':[2001,2001,2003,2002], 'city':['北京','上海','廣州','北京']}df = pd.DataFrame(data,columns = ['name','year','sex','city','address'],index = ['a','b','c','d'])print(df)print('信息表的所有值為:\n',df.values)print('信息表的所有列為:\n',df.columns)print('信息表的元素個數:\n',df.size)print('信息表的維度:\n',df.ndim)print('信息表的形狀:\n',df.shape) #//輸出 name year sex city addressa 張三 2001 female 北京 NaNb 李四 2001 female 上海 NaNc 王五 2003 male 廣州 NaNd 小明 2002 male 北京 NaN信息表的所有值為: [['張三' 2001 'female' '北京' nan] ['李四' 2001 'female' '上海' nan] ['王五' 2003 'male' '廣州' nan] ['小明' 2002 'male' '北京' nan]]信息表的所有列為: Index(['name', 'year', 'sex', 'city', 'address'], dtype='object')信息表的元素個數: 20信息表的維度: 2信息表的形狀: (4, 5)到此這篇關於Python Pandas 中的數據結構詳解的文章就介紹到這了,更多相關Python Pandas 內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!