Hello everyone , Here is @ Drink less cold water G! Recently, I have been doing Python The study of data analysis , So I write this article as a note , This article is the first in the notes series , Irregular update . If there are mistakes or omissions in your blog , I hope you can give me some advice , Thank you so much .
Pandas It's based on Numpy module and matplotlib module Above , Its code style and Numpy Very close to , But the biggest difference is ,Pandas For tabular data or heterogeneous data , and Numpy It is more suitable for processing homogeneous data , That is, data with the same data type .
Before we start , This article assumes that readers have a preliminary understanding of Python Basic knowledge of , Yes
Numpy modularHave a certain understanding .
It is because Pandas Is in Numpy Based on the realization of , Its core data structure is similar to Numpy Of ndarray Very similar . The main difference between the two is :
From the perspective of data structure :
From the function orientation point of view :
numpy Although it also supports other data types such as strings , But it is still mainly used for Numerical calculation , In particular, a large number of matrix calculation modules are integrated inside , For example, basic matrix operations 、 linear algebra 、fft、 Generating random numbers, etc
pandas It is mainly used for Data processing and analysis , Support includes data reading and writing 、 Numerical calculation 、 Data processing 、 Data analysis and data visualization complete process operation
The beginning of all things , introduce pandas package :
import pandas as pd
Pandas There are two fairly common data structures ( class ):Series and DataFram, This article mainly studies these two kinds of data structures .
Series from A set of data And a set of related Data labels ( Index ) form , Similar to a column in a table (column), contain index and values Two properties , You can select... By index Series A single or set of values in .
whatever Python Medium Sequence (sequence) Can be passed into Series The generating function of . The sequence is Python The most basic data structure in , Include list 、 Tuples 、 character string 、Unicode character string 、buffer Objects and xrange object . as follows :
pd.Series(list,index=[ ])
list For incoming sequence ,index Specify index for , The default is empty. . See below case :
>> obj = pd.Series([2,3,4,5])
>> obj
0 2
1 3
2 4
3 5
dtype: int64
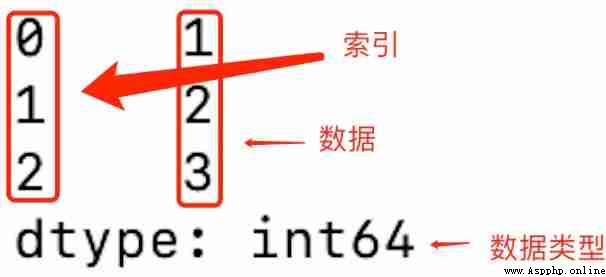
Series Is an ordered data type , In this case , The index is on the left , The value is on the right . We passed in a list ( Of course, it can also be introduced into Array (ndarray), Dictionaries , Tuples etc. ), If no index is specified , The index value is from 0 Start , We can read data according to the index value . Of course, we can also specify the index by ourselves , for example :
>> obj = pd.Series([2,3,4,5],index = ['a','b','c','a'])
>> obj
a 2
b 3
c 4
a 5
dtype: int64
Be careful ! As can be seen from the above example ,Series The index in is repeatable ! And even if the index is specified , We can still use from 0 Start the subscript index to read , Such as obj[1] = 3
visit Series Several properties of , These properties can be changed by assignment :
In: obj.index # Get index
obj.values # Get value
obj.dtype # Get data type
obj.name = 'text' # to obj The name
obj.index.name = 'INDEX' # to obj The name of the rope causes
Out:Index(['a', 'b', 'a', 'd'], dtype='object')
array([2, 3, 4, 5], dtype=int64)
dtype('int64')
Pandas be based on Numpy Development , So many of these operations have something in common . For example, in addition to using a subscript index to read , Boolean indexes can also be used for reading , At the same time, scientific calculation can be carried out .
# Subscript indices
>> obj[1:3]
b 3
a 4
dtype: int64
# Boolean index
>> obj[[True,False,False,True]]
a 2
d 5
dtype: int64
>> obj[obj>=3]
b 3
a 4
d 5
dtype: int64
DataFrame It's kind of like Excel Data table in , Both row index and column index , The value type of each column can be different ( The number , String, etc. ), Is a two-dimensional data type .
pandas.DataFrame(data, index, columns, dtype, copy)
Use the following example to illustrate DataFrame Create function of :
data = [ # You can also import two-dimensional ndarray、 Sequence, etc
[1,2,3],
[2,3,4],
[3,1,0],
[4,7,9]
]
# The second parameter is the row index , The third is the column index
frame = pd.DataFrame(data,range(1,5),['a','b','c'])
>> frame # Of course, if no index is specified, the default is from 0 Start
a b c
1 1 2 3
2 2 3 4
3 3 1 0
4 4 7 9
obtain DataFrame Properties of :
In: frame.index # Get index
frame.columns # To get the column name
frame.values # Get value
frame.shape # Get the number of columns
frame.dtypes # Get data type , Note the plural
frame.name = 'text' # to frame The name
frame.index.name = 'INDEX' # to frame The name of the rope causes
Out:RangeIndex(start=1, stop=5, step=1)
Index(['a', 'b', 'c'], dtype='object')
array([[1, 2, 3],
[2, 3, 4],
[3, 1, 0],
[4, 7, 9]], dtype=int64)
(4, 3)
a int64
b int64
c int64
dtype: object
Be careful ! The following operations are performed in the data view , Instead of copying , So right. DataFrame The operation of will change the data content
Before visit n That's ok :
>> frame.head(3) # You can only enter integers
a b c
1 1 2 3
2 2 3 4
3 3 1 0
Using indexes to access Columns :
>> frame[['b','c']] # Access single column as frame['b']
b c
1 2 3
2 3 4
3 1 0
4 7 9
# perhaps
>> frame.b # The effect same as above
Change all the values of an entire column , If column name does not exist , Then a new column is generated :
>> frame['d'] = (frame.c > 0)
frame
a b c d
1 1 2 3 True
2 2 3 4 True
3 3 1 0 False
4 4 7 9 True
Delete some lines / Column :
new_frame = frame.drop([2,3],axis = 0) # primary frame unchanged , Return new data , The second parameter is 0 Represents the operation line , by 1 Represents the operation column
Delete some columns :
del frame['d']
Delete some lines / Column :
new_frame = frame.drop([2,3],axis = 0) # primary frame unchanged , Return new data , The second parameter is 0 Represents the operation line , by 1 Represents the operation column
Delete some columns :
del frame['d']
Here are some operations about indexing :

Next time I should write Pandas Data reading and so on , But I don't know when the update is hhh.
Reprint Please mark the author and source link