1、登錄官網下載所需的版本包
以window7為例:
右鍵下載包(Windows x86-64 executable installer)以管理員身份運行
#!/usr/bin/python3
在使用變量之前,需要對其先賦值。
變量名可以包括字母、數字、下劃線,不能以數字開頭
(\)轉義符 # 例: let\'s go
如果想打印路徑特殊字符比較多,字符串前加r即可。
例:D:\AIT\work\Software\xftp
可以使用
str = r‘D:\AIT\work\Software\xftp’
使用idle(Python的編輯器),ctrl+n新建一個編輯頁,f5運行
import random #隨機數
#print( random.randint(1,10) ) # 產生 1 到 10 的一個整數型隨機數
#print( random.random() ) # 產生 0 到 1 之間的隨機浮點數
#print( random.uniform(1.1,5.4) ) # 產生 1.1 到 5.4 之間的隨機浮點數,區間可以不是整數
#print( random.choice('tomorrow') ) # 從序列中隨機選取一個元素
#print( random.randrange(1,100,2) ) # 生成從1到100的間隔為2的隨機整數
secret = random.randint(1,3)
print("隨機數為",secret)
print('--------草莓A工作---------')
temp = input("猜數字,請寫下一個數字:")
guess = int(temp)
while guess != secret:
temp = input("猜錯了,請再次輸入:")
guess = int(temp)
if guess == secret:
print("你竟然蒙對了!\n" + "诶呦,猜對了也沒有用!")
else:
if guess >secret:
print("數字大了")
else:
print("數字小了")
print("結束^_^")
>>> assert 3>7 #(斷言:後面條件為假時,程序崩潰彈出異常AssertionError)
Traceback (most recent call last):
File "<pyshell#25>", line 1, in <module>
assert 3>4
AssertionError
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'a', 'fa', 'guess', 'i', 'list1', 'list2', 'list3', 'member', 'member2', 'random', 'secret', 'temp']
>>>
>>> dir(list)
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
>>>
dir() 函數不帶參數時,返回當前范圍內的變量、方法和定義的類型列表;帶參數時,返回參數的屬性、方法列表。
>>> member = [1, 3, '好', 'stree’']
>>> member.append('好的') #追加一個到末尾
>>> member
[1, 3, '好', 'stree', 'sdfasdf']
>>>
>>> member.extend(['哦','啊']) #追加列表到末尾
>>> member
[1, 3, '好', 'stree', 'sdfasdf', '哦', '啊']
>>>
>>> member.insert(1,'hei') #插入到什麼位置
>>> member
[1, 'hei', 3, '好', 'stree', 'sdfasdf', '哦', '啊']
>>>
>>> member[2]
3
>>>
`>>> member.remove('啊') #刪除一個值
>>> member
[1, 'hei', 3, '好', 'stree', 'sdfasdf', '哦']
>>> ``
>>> del member[1] #刪除某一位的值
>>> member
[1, 3, '好', 'stree', 'sdfasdf', '哦']
>>>
>>> member.pop() # 函數用於移除列表中的一個元素(默認最後一個元素),並且返回該元素的值。
'哦'
>>> member
[1, 3, '好', 'stree', 'sdfasdf']
>>> member.pop(0) #也可以指定移出
1
>>> member
[3, '好', 'stree', 'sdfasdf']
>>> member[1:3] #拷貝出1到3位置的值不包括3,也可以使用member[:3]、member[1:]、member[:]
['好', 'stree']
>>> member
[3, '好', 'stree', 'sdfasdf']
>>> member[:3]
[3, '好', 'stree']
>>> member[1:]
['好', 'stree', 'sdfasdf']
>>> member[:]
[3, '好', 'stree', 'sdfasdf']
>>> member2 = member[:] # 拷貝。如果使用member2 = member的話member2會因member的變動而變動。
>>> member2
[3, '好', 'stree', 'sdfasdf']
>>>
>>> list1 = [123]
>>> list2 = [234]
>>> list1 < list2
True
>>> list1 = [123, 456]
>>> list2 = [234, 345]
>>> list1< list2 #比較第0位
True
>>> list1 * 3
[123, 456, 123, 456, 123, 456]
>>> 123 in list1
True
>>> 123 not in list1
False
>>> 1223 not in list1
True
>>>
>>> list3 = [123, ['你好', 123, 'hello'], 234]
>>> '你好' in list3
False
>>> '你好' in list3[1]
True
>>> list3[1]
['你好', 123, 'hello']
>>>
>>> list3[1][1]
123
>>>
>>> list3 *= 5
>>> list3
[123, ['你好', 123, 'hello'], 234, 123, ['你好', 123, 'hello'], 234, 123, ['你好', 123, 'hello'], 234, 123, ['你好', 123, 'hello'], 234, 123, ['你好', 123, 'hello'], 234]
>>> list3.count(123) #123在list中出現的次數
5
>>>
>>>
>>> list3 = [234, '你好', 123, 'hello']
>>> list3
[234, '你好', 123, 'hello']
>>>
>>> list3.reverse() #list中值反轉
>>> list3
['hello', 123, '你好', 234]
>>>
>>> list3.index(123) #返回參數在列表中的位置,取命中其中的第一個位置,默認所有范圍
1
>>>
>>> list3*=3
>>> list3
['hello', 123, '你好', 234, 'hello', 123, '你好', 234, 'hello', 123, '你好', 234]
>>> list3.index(123,3,7) # 查詢范圍3~7,中123的位置
5
>>>
>>> list4 = [0,2,3,5,4,7,6,3]
>>> list4.sort() # 排序從小到大
>>> list4
[0, 2, 3, 3, 4, 5, 6, 7]
>>> list4.sort(reverse=True) #逆序
>>> list4
[7, 6, 5, 4, 3, 3, 2, 0]
元組是不可改變的,不能增減排序
>>> tuple1 = (1,2,3,4,5,6,7,8)
>>> tuple1
(1, 2, 3, 4, 5, 6, 7, 8)
>>> tuple1[1]
2
>>> tuple1[3:]
(4, 5, 6, 7, 8)
>>> tuple2 = tuple1[:]
>>> tuple2
(1, 2, 3, 4, 5, 6, 7, 8)
>>>
>>> temp = (3,) #創建一個元組必須要有逗號
>>> type(temp) # 查看變量類型
<class 'tuple'>
>>>
>>> temp1 = (3)
>>> type(temp1)
<class 'int'>
>>>
>>> tuple1
(1, 2, 3, 4, 5, 6, 7, 8)
>>> tuple1 = tuple1[:2] + ('leo',) + tuple1[2:] #可以使用拼接進行更改,使用舊的元組拼接成新的元組(其實是更改tuple1指針位置,舊指針python過段時間會自動清理。)
>>> tuple1
(1, 2, 'leo', 3, 4, 5, 6, 7, 8)
>>>
>>> 8 * (8,) # 跟list一樣
(8, 8, 8, 8, 8, 8, 8, 8)
>>>
使用內置方法,原有的值不會變
>>> dir(str)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isascii', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
>>>
>>> str1 = 'I love you'
>>> str1.capitalize() # 首字母大寫
'I love you'
>>> str1.casefold() #
'i love you'
>>> str1.center(40)
' I love you '
>>> str1.count('o')
2
>>> str1
'I love you'
>>>
>
字符串內置方法
>>> "{0} love {1}.{2}".format("i","python","com")
'i love python.com'
>>> "{a} love {b}.{c}".format(a="i",b="python",c="com")
'i love python.com'
>>> "{
{1}}".format("不打印")
'{1}'
>>> '{0:.1f}{1}'.format(27.58,'GB') # 冒號標識格式化符號的開始,打印小數點後一位定點數
'27.6GB'
>>>
>>> '%c' '%c' '%c' % (97, 98, 99)
'abc'
>>> '%s' % 'i love you'
'i love you'
>>> '%d + %d - %d' % (5,5,1)
'5 + 5 - 1'
>>>
>>> '%o' % 10
'12'
>>> '%10d' % 10
' 10'
>>> '%010d' % 10
'0000000010'
>>> '%-010d' % 10
'10 '
>>>
字符串格式化符號含義
格式化操作符輔助命令
Python 的轉義字符及其含義
>>> b = 'I love you'
>>> b
'I love you'
>>> b = list(b)
>>> b
['I', ' ', 'l', 'o', 'v', 'e', ' ', 'y', 'o', 'u']
>>> c = (1,1,2,3,4,8,13,21,34) #元組
>>> c = list(c) # 元組轉為列表
>>> c
[1, 1, 2, 3, 4, 8, 13, 21, 34]
>>>
>>> max(c)
34
>>> min(c)
1
>>> sum(c)
87
>>>
>>> c.append(2) # 末尾追加2
>>> sorted(c) # 排序,不改變源c序列
[1, 1, 2, 2, 3, 4, 8, 13, 21, 34]
>>>
>>> c
[1, 1, 2, 3, 4, 8, 13, 21, 34, 2]
>>> reversed(c) # 反轉,返回的是一個迭代器的對象
<list_reverseiterator object at 0x0000000002D1E430>
>>> list(reversed(c)) # 轉化為列表
[2, 34, 21, 13, 8, 4, 3, 2, 1, 1]
>>>
>>> c
[1, 1, 2, 3, 4, 8, 13, 21, 34, 2]
>>> enumerate(c)
<enumerate object at 0x000000000303AE00>
>>> list(enumerate(c)) # 枚舉
[(0, 1), (1, 1), (2, 2), (3, 3), (4, 4), (5, 8), (6, 13), (7, 21), (8, 34), (9, 2)]
>>>
>>> b
[3, 4, 6, 7, 8]
>>> list(zip(b,c)) # 打包
[(3, 1), (4, 1), (6, 2), (7, 3), (8, 4)]
>>>
Python調用函數,如果上面沒有定義是無法調用的。
>>> def MyFirstFunction():
print('this is my first function')
print('再次表示感謝')
print('感謝CCTV')
>>> MyFirstFunction()
this is my first function
再次表示感謝
感謝CCTV
>>>
>>>
>>> def MySecondFunction(name, parameter):
'這個是函數文檔'
print(name + '我喜歡你的' + parameter)
>>> MySecondFunction.__doc__
'這個是函數文檔'
>>> MySecondFunction(name = 'leo', parameter='技術')
leo我喜歡你的技術
>>>
>>>
>>> def MySecondFunction(name='大家', parameter='能力'):
'這個是函數文檔'
print(name + '我喜歡你的' + parameter)
>>> MySecondFunction()
大家我喜歡你的能力
>>>
>>>
>>> def test(*params, exp = 8):
print('參數的長度是', len(params), exp);
print('第二位的參數是', params[1]);
>>> test(1,'leo',3,5,74)
參數的長度是 5 8
第二位的參數是 leo
>>>
例子1:
def MyFirstFunction(price , rate):
'這個是函數文檔'
old_price = 20
print('局部變量old_price:',old_price)
global count #定義全局變量
count = 10
final_price = price * rate
return final_price
old_price = float(input('請輸入原價:'))
print('全局變量old_price:',old_price)
rate = float(input('請輸入折扣率:'))
new_price = MyFirstFunction(old_price, rate) # 調用函數計算
print('打折後的價格是:', new_price)
print('自定義全局變量count使用global:',count)
例子1運行結果
====================== RESTART: F:/python-test/function.py =====================
請輸入原價:100
全局變量old_price: 100.0
請輸入折扣率:0.5
局部變量old_price: 20
打折後的價格是: 50.0
自定義全局變量count使用global: 10
>>>
>>> def fun1():
x = 5
def fun2():
nonlocal x # 令x變量全局化
x *=x
return x
return fun2()
>>> fun1()
25
>>>
range
>>>range(10) # 從 0 開始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 從 1 開始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 30, 5) # 步長為 5
[0, 5, 10, 15, 20, 25]
>>> range(0, 10, 3) # 步長為 3
[0, 3, 6, 9]
>>> range(0, -10, -1) # 負數
[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> range(0)
[]
>>> range(1, 0)
[]
以下是 range 在 for 中的使用,循環出runoob 的每個字母:
>>>x = 'runoob'
>>> for i in range(len(x)) :
... print(x[i])
...
r
u
n
o
o
b
>>>
內置函數filter過濾出從 0 開始到 9,10個數字中為奇數的數
>>> range(10) # 從 0 開始到 9
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list(filter(None, [1, 0, False, True])) # 過濾出為不為None的
[1, True]
>>>
>>> temp = range(10)
>>> def odd(x):
return x % 2
>>> show = filter(odd, temp) # 過濾出為奇數的數字(不為偶數的數字)
>>> list(show)
[1, 3, 5, 7, 9]
>>>
>>> list(filter(lambda x : x % 2,range(10))) # 過濾出為奇數的數字(不為偶數的數字)。等同於上面的用法
[1, 3, 5, 7, 9]
>>>
內置函數map() 會根據提供的函數對指定序列做映射。
加工參數返回序列
>>> list(map(lambda x : x * 2, range(10)))
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>>
例子1:求5的階乘(迭代)迭代:是重復反饋過程的活動,其目的通常是為了逼近所需目標或結果。每一次對過程的重復稱為一次“迭代”,而每一次迭代得到的結果會作為下一次迭代的初始值。(循環)
def recursion(n):
result = n
for i in range(1, n):
result *= i
return result
number = int(input('請輸入一個正整數:'))
result = recursion(number)
print('%d 的階乘是:%d'% (number, result))
例子1的結果:
===================== RESTART: F:/python-test/recursion.py =====================
請輸入一個正整數:5
5 的階乘是:120
>>>
例子2:求5的階乘(遞歸)遞歸,就是在運行的過程中調用自己。
def factorial(n):
if n == 1:
return 1
else:
return n * factorial(n-1)
number = int(input('請輸入一個正整數:'))
result = factorial(number)
print('%d 的階乘是:%d'% (number, result))
例子2結果
===================== RESTART: F:/python-test/factorial.py =====================
請輸入一個正整數:5
5 的階乘是:120
>>>
迭代執行速度 > 遞歸執行速度
例子1:迭代實現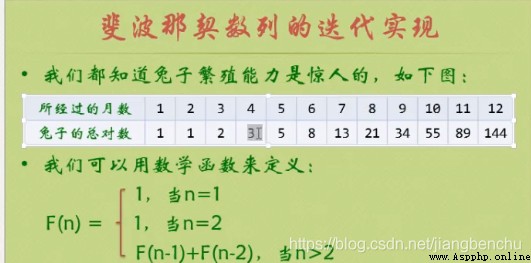
def fab(n):
n1 = 1
n2 = 1
n3 = 1
if n < 1:
print('輸入錯誤:')
return -1
while (n -2) > 0:
n3 = n2 + n1
n1 = n2
n2 = n3
n -= 1
return n3
num = int(input('請輸入數字:'))
result = fab(num)
if result != -1:
print('總共%d個小兔子' % result)
例子1結果:
======================= RESTART: F:/python-test/fab_1.py =======================
請輸入數字:30
總共有832040個小兔子誕生
>>>
例子2:遞歸實現(調用自身)數學函數思想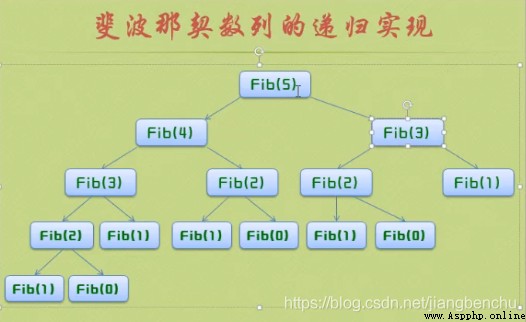
def fab(n):
if n < 1 :
print('輸入錯誤:')
return -1
if n==1 or n ==2:
return 1
else:
return fab(n-1) + fab(n-2)
num = int(input('請輸入數字:'))
result = fab(num)
if result != -1:
print('總共有%d個小兔子誕生' % result)
例子2:結果
======================= RESTART: F:/python-test/fab_2.py =======================
請輸入數字:30
總共有832040個小兔子誕生
>>>
def hanoi(n, x , y, z):
if n == 1:
print(x, '-移動到->', z)
else:
hanoi(n-1, x, z, y) # 將前n-1個盤子從x移動到y上
print(x, '-移動到->', z) # 將最底下的最後一個盤子從x移動到z上
hanoi(n-1, y, x, z) # 將y上的n-1個盤子移動到z上
n = int(input('請輸入漢諾塔的層數:'))
hanoi(n, 'x左柱', 'y中柱', 'z右柱')
輸入4層結果:
====================== RESTART: F:/python-test/hannuota.py =====================
請輸入漢諾塔的層數:4
x左柱 -移動到-> y中柱
x左柱 -移動到-> z右柱
y中柱 -移動到-> z右柱
x左柱 -移動到-> y中柱
z右柱 -移動到-> x左柱
z右柱 -移動到-> y中柱
x左柱 -移動到-> y中柱
x左柱 -移動到-> z右柱
y中柱 -移動到-> z右柱
y中柱 -移動到-> x左柱
z右柱 -移動到-> x左柱
y中柱 -移動到-> z右柱
x左柱 -移動到-> y中柱
x左柱 -移動到-> z右柱
y中柱 -移動到-> z右柱
>>>
key value
>>> dict1 = {
'李寧':'一切皆有可能','耐克':'jus do IT','阿迪達斯':'imossible is nohing'}
>>> print('耐克的口號是:',dict1['耐克'])
耐克的口號是: jus do IT
>>>
>>> dict2 = {
1:'ont', 2:'two', 3:'three'} # 創建一個字典
>>> dict2[2]
'two'
>>> dict3 = {
} #創建一個空的字典
>>> dict3
{
}
>>>
>>> dict3 = dict((('f',70), ('i',99), ('3',80),('4',9))) # 創建一個字典
>>> dict3
{
'f': 70, 'i': 99, '3': 80, '4': 9}
>>>
>>> dict4 = dict(你好='全世界', 電影='真好看') # 創建一個字典
>>> dict4
{
'你好': '全世界', '電影': '真好看'}
>>>
>>> dict4['電影'] = '是什麼' # 修改key對應的值
>>> dict4
{
'你好': '全世界', '電影': '是什麼'}
>>>
>>> dict4['小甲魚'] = '又是什麼' # 添加字典key -value
>>> dict4
{
'你好': '全世界', '電影': '是什麼', '小甲魚': '又是什麼'}
>>>
>>> dict1 = {
}
>>> dict1
{
}
>>> dict1.fromkeys((1,2,3,4))
{
1: None, 2: None, 3: None, 4: None}
>>> dict1 = dict1.fromkeys(range(32), '贊')
>>> dict1
{
0: '贊', 1: '贊', 2: '贊', 3: '贊', 4: '贊', 5: '贊', 6: '贊', 7: '贊', 8: '贊', 9: '贊', 10: '贊', 11: '贊', 12: '贊', 13: '贊', 14: '贊', 15: '贊', 16: '贊', 17: '贊', 18: '贊', 19: '贊', 20: '贊', 21: '贊', 22: '贊', 23: '贊', 24: '贊', 25: '贊', 26: '贊', 27: '贊', 28: '贊', 29: '贊', 30: '贊', 31: '贊'}
>>> for eachkey in dict1.keys(): # 打印keys
print(eachkey)
0
1
2
3
……
30
31
>>> for eachkey in dict1.values(): # 打印values
print(eachkey)
贊
贊
……
贊
>>> for eachkey in dict1.items(): # 打印所有的內容
print(eachkey)
(0, '贊')
(1, '贊')
(2, '贊')
(3, '贊')
……
(31, '贊')
>>> print(dict1[31])
贊
>>> print(dict1[32])
Traceback (most recent call last):
File "<pyshell#49>", line 1, in <module>
print(dict1[32])
KeyError: 32
>>>
>>> print(dict4.get(32)) # get獲取值
None
>>> dict4.get(32)
>>> print(dict1.get(3, 'meiyou')) # 有值的話正常打印獲取的 值
贊
>>> print(dict1.get(32, 'meiyou')) # 可以如果不存在的情況下返回‘沒有’
meiyou
>>>
>>> 31 in dict1 # 使用in查找成員是否存在
True
>>> 32 in dict1
False
>>>
>>> dict1.clear() # 清空字典
>>> dict1
{
}
>>>
#使用clear會清空相關的字典表,如果直接置空其他關聯的表數據依然存在,以下是例子
>>> a = {
'name', 'leo'}
>>> b = a
>>> b
{
'leo', 'name'}
>>> a = {
}
>>> a
{
}
>>> b
{
'leo', 'name'}
>>> a = b
>>> a.clear()
>>> b
set()
>>> a
set()
>>> a = {
1:'noe', 2:'two', 3:'three'}
>>> b = a.copy() # 拷貝
>>> b
{
1: 'noe', 2: 'two', 3: 'three'}
>>> c = a # 賦值,只是在相同的數據上貼了一個標簽
>>> c
{
1: 'noe', 2: 'two', 3: 'three'}
>>>
>>> id(a)
50054720
>>> id(b)
50329216
>>> id(c)
50054720
>>>
>>> c[4] = 'four'
>>> c
{
1: 'noe', 2: 'two', 3: 'three', 4: 'four'}
>>> a
{
1: 'noe', 2: 'two', 3: 'three', 4: 'four'}
>>> b
{
1: 'noe', 2: 'two', 3: 'three'}
>>>
>>> a.pop(4) # 指定彈出一個key value
'four'
>>> a
{
1: 'noe', 2: 'two', 3: 'three'}
>>> a.popitem() # 隨機彈出一個key value
(3, 'three')
>>> a
{
1: 'noe', 2: 'two'}
>>> a.setdefault('xiaobai') # 添加一個key
>>> a
{
1: 'noe', 2: 'two', 'xiaobai': None}
>>> a.setdefault(3, 'five') # 添加一個key value
'five'
>>> a
{
1: 'noe', 2: 'two', 'xiaobai': None, 3: 'five'}
>>> b = {
'小白': 'dog'}
>>> a.update(b) # b映射更新到另一個字典a中去
>>> a
{
1: 'noe', 2: 'two', 'xiaobai': None, 3: 'five', '小白': 'dog'}
>>>
是無序的,無法索引某一個元素。
>>> set1 = set([1,2,3,4,5,5,5]) #創建一個集合自動剔除重復的值
>>> set1
{
1, 2, 3, 4, 5}
>>>
不可變的集合:
>>> num3 = frozenset([1,2,3,4,5]) # 定義一個不可變的集合
>>> num3.add(0)
Traceback (most recent call last):
File "<pyshell#148>", line 1, in <module>
num3.add(0)
AttributeError: 'frozenset' object has no attribute 'add'
>>>
內置方法:
>>> num2 = {
1,2,3,4,5,6,7,8}
>>> num2
{
1, 2, 3, 4, 5, 6, 7, 8}
>>> 1 in num2
True
>>> 9 in num2
False
>>> num2.add(9) # 添加
>>> num2
{
1, 2, 3, 4, 5, 6, 7, 8, 9}
>>>
>>> num2.remove(1) # 移除
>>> num2
{
2, 3, 4, 5, 6, 7, 8, 9}
>>>
例子:如果想剔除列表中重復的數[1,2,3,4,5,5,3,2,1,0]
方法一
for循環判斷
>>> num1 = [1,2,3,4,5,5,3,2,1,0]
>>> num1
[1, 2, 3, 4, 5, 5, 3, 2, 1, 0]
>>> temp = []
>>> for each in num1:
if each not in temp:
temp.append(each)
>>> temp
[1, 2, 3, 4, 5, 0]
>>>
方法二
使用集合set函數自動剔除重復的數,但是集合是無序的,雖然剔除了重復的數但是結果是亂序的
>>> num1 = [1,2,3,4,5,5,3,2,1,0]
>>> num1
[1, 2, 3, 4, 5, 5, 3, 2, 1, 0]
>>> num1 = list(set(num1)) # 使用集合set函數自動剔除重復的數,但是集合是無序的,雖然剔除了重復的數但是結果是亂序的
>>> num1
[0, 1, 2, 3, 4, 5]
>>>
列表推導式
[x*y for x in range(1,5) if x > 2 for y in range(1,4) if y < 3]
他的執行順序是:
for x in range(1,5)
if x > 2
for y in range(1,4)
if y < 3
x*y
>>> # 列表推導式
>>> a = [i for i in range(100) if not(i % 2) and i % 3]
>>> a
[2, 4, 8, 10, 14, 16, 20, 22, 26, 28, 32, 34, 38, 40, 44, 46, 50, 52, 56, 58, 62, 64, 68, 70, 74, 76, 80, 82, 86, 88, 92, 94, 98]
>>> # 字典推導式
>>> b = {
i:i %2 ==0 for i in range(10)}
>>> b
{
0: True, 1: False, 2: True, 3: False, 4: True, 5: False, 6: True, 7: False, 8: True, 9: False}
>>> # 集合推導式
>>> c = {
i for i in [1, 1, 2, 3, 4, 5, 5, 6, 7, 3, 2, 1]}
>>> c
{
1, 2, 3, 4, 5, 6, 7}
文件打開模式:
文件對象方法:
>>> f = open('F:\\python-test\\文件\\心經.txt') # 打開文件
>>> f.read(5) # 讀取文件內容,如果不給定值讀取所有,指針放到最後
'心經原文 '
>>> f.tell() # 返回所在位置
9
>>> f.seek(2, 0) # 在文件中移動文件指針f.seek(offset, from)(0代表文件起始位置,1代表當前位置,2代表文件末尾)偏移offset個字節
2
>>> f.readline() # 從文件中讀取並返回一行
'經原文 \u3000 \n'
>>> f.seek(0,0) # 指針放到開始位置
0
# 可轉成列表形式讀取
>>> lines = list(f)
>>> for each_line in lines:
print(each_line)
心經原文
……
# 官方推薦直接迭代讀取(高效)
>>> f.seek(0,0)
0
>>> for each_lin in f:
print(each_lin)
心經原文
……
>>> f = open('F:\\python-test\\文件\\心經.txt','w')
>>> f.tell()
0
>>> f.write('I love hello wold') # 以寫入的方式打開文件,會覆蓋已存在的文件
17
>>> f.close()
>>>
>>> f = open('F:\\python-test\\文件\\心經.txt','a') # 以寫入模式打開,如果文件存在,則在末尾追加寫入
>>> f.read()
>>> f.write('I love hello wold')
17
>>> f.close()
test.txt
你好:I love hello wold1
不好:I love hello wold2
你好:I love hello wold3
不好:I love hello wold4
你好:I love hello wold5
=======================
不好:I love hello wold6
你好:I love hello wold7
不好:I love hello wold8
你好:I love hello wold9
=======================
不好:I love hello wold0
你好:I love hello wold~
不好:I love hello wold!
你好:I love hello wold?
不好:I love hello wold。
按‘不好’、‘你好’:後的話分割存儲到不同的文件中,一個====分割成一個文件
F:/python-test/file.py
# 保存文件
def save_file(boy, girl ,count):
file_name_boy = 'F:\\python-test\\文件\\' + 'boy_' + str(count) + '.txt'
file_name_girl = 'F:\\python-test\\文件\\' + 'girl_' + str(count) + '.txt'
boy_file = open(file_name_boy, 'w') # 打開一個文件准備寫入
girl_file = open(file_name_girl, 'w')
boy_file.writelines(boy) #向文件寫入字符串“序列”
girl_file.writelines(girl)
boy_file.close()
girl_file.close()
# 分割文件
def split_file(file_name):
f = open(file_name)
boy = []
girl = []
count = 1
for each_line in f:
if each_line[:6] != '======':
# 我們這裡進行字符串分割
(role, line_spoken) = each_line.split(':', 1) # 分割一次,返回切片後的子字符串拼接的列表。
if role == '你好':
boy.append(line_spoken)
if role == '不好':
girl.append(line_spoken)
else:
# 文件分割保存,碰到'======'保存
save_file(boy, girl, count)
boy = []
girl = []
count += 1
save_file(boy, girl, count)
f.close()
split_file('F:\\python-test\\文件\\test.txt')
運行成功:
import os
簡單使用:
>>> import os
>>> os.getcwd() # 獲取當前工作目錄
'F:\\python-test'
>>> os.chdir('F:\\python-test\\working') # 更改工作目錄
>>> os.getcwd()
'F:\\python-test\\working'
>>> os.listdir()
['fab_1.py', 'fab_2.py', 'factorial.py', 'file.py', 'function.py', 'hannuota.py', 'print(ifelse).py', 'recursion.py']
>>> os.makedirs('F:\\python-test\\working\\A\\B')
>>> os.listdir()
['A', 'fab_1.py', 'fab_2.py', 'factorial.py', 'file.py', 'function.py', 'hannuota.py', 'print(ifelse).py', 'recursion.py']
>>> os.curdir
'.'
>>> os.listdir(os.curdir)
['fab_1.py', 'fab_2.py', 'factorial.py', 'file.py', 'function.py', 'hannuota.py', 'print(ifelse).py', 'recursion.py']
>>>
使用例子:
>>> os.path.basename('F:\\python-test\\working\\factorial.py')
'factorial.py'
>>> os.path.dirname('F:\\python-test\\working\\factorial.py')
'F:\\python-test\\working'
>>>
>>> os.listdir(os.path.dirname('F:\\python-test\\working\\'))
['fab_1.py', 'fab_2.py', 'factorial.py', 'file.py', 'function.py', 'hannuota.py', 'print(ifelse).py', 'recursion.py']
>>>
>>> os.path.split('F:\\python-test\\working\\factorial.py')
('F:\\python-test\\working', 'factorial.py')
>>>
>>> os.path.splitext('F:\\python-test\\working\\factorial.py')
('F:\\python-test\\working\\factorial', '.py')
>>> import time
>>> time.localtime(os.path.getatime('F:\\python-test\\working\\factorial.py'))
time.struct_time(tm_year=2020, tm_mon=11, tm_mday=5, tm_hour=15, tm_min=42, tm_sec=43, tm_wday=3, tm_yday=310, tm_isdst=0)
>>>
>>> os.path.exists('F:\\python-test\\working\\factorial.py')
True
>>> os.path.ismount('F:\\')
True
>>> os.path.ismount('F:\\python-test\\')
False
>>>
零基礎入門2
學習地址
資料地址
Pymongo