Tightly coupled : The two parts communicate a lot , Can't exist alone
loose coupling : Less communication between the two parts , Can exist independently
chain : There is a recursive chain in the calculation process
Basic example : There are one or more base instances that do not need to recurse again
function + Branch statement
character string s Output after inversion
def rus(s):
if s=="":
return s
else:
return rvs(s[1:])+s[0]
Fibonacci sequence
def f(n):
if n==1 or n==2:
return 1
else:
return f(n-1)+f(n-2)
Hanoi
count=0
def hanoi(n,src,dst,mid):
global count
if n==1:
print("{}:{}->{}".format(1,src,dst))
count+=1
else:
hanoi(n-1,src,mid,dst)
print("{}:{}->{}".format(n,src,dst))
count+=1
hanoi(n-1,mid,dst,src)
Convert the source code to an executable 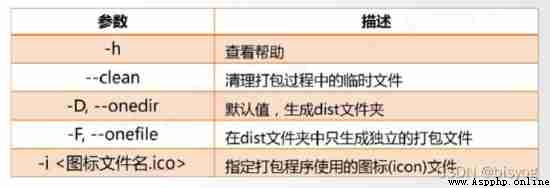
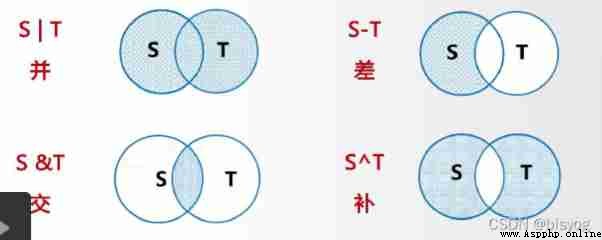
Collection types : There is no mutable data type
To create a collection type {} or set()
To create an empty collection type, you must use set()
Enhanced operators 
Set processing method 
S.clear() remove S All elements in
S.pop() Return immediately S An element of , to update S, if S Create... For nothing KeyError abnormal
S.copy() Back to the assembly S A copy of
len(S) Back to the assembly S Number of elements of
x in S Judge S Medium element x,x In collection S in , return True, Otherwise return to False
x not in S Judge S Medium element x,x Don't set S in , return True, Otherwise return to False
set(x) Put other types of variables x Change to set type
A={
"p","y",123}
for item in A:
print(item,end="")
try:
while True:
print(A.pop(),end="")
except:
pass
Data De duplication
A sequence is a group of elements with a sequence relationship , It's a one-dimensional element vector , Element types can be different ( Basic data type )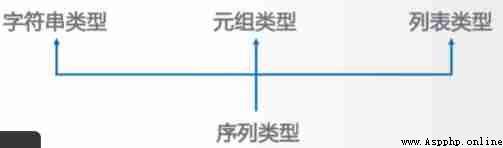
Serial number : Positive increase (0)& Reverse decrement (-1)
Sequence universal operator 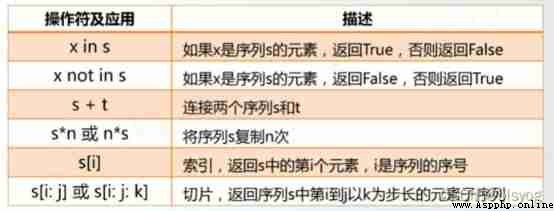
len(s) length min(s) The smallest element max(s) The biggest element
s.index(x) or s.index(x,i,j) Return sequence s from i Start to j The first element in the position x The location of
Tuples It's a sequence type , Once created, it cannot be modified
Use parentheses () or tuple() establish , Between elements , Separate
Brackets can be used or not
list Is an extension of the sequence type , Very often , It's a sequence type , After creation, it can be modified at will . Use 【】 or list() establish , Use commas... Between elements , Separate 
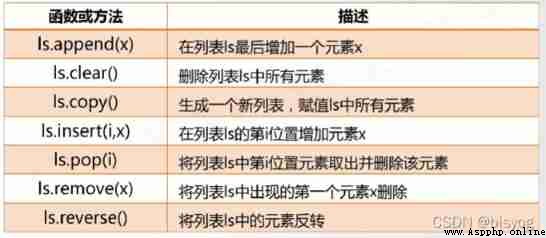
Basic statistics
Total number :len()
Sum up :for…in
def getNum():
nums=[]
iNumStr=input(" Please enter a number ( Enter exit ):")
while iNumStr!="":
nums.append(eval(iNumStr))
iNumStr=input(" Please enter a number ( Enter exit )")
return nums
def mean(numbers): # Calculate the average
s=0.0
for num in numbers:
s=s+num
return s/len(numbers)
def dev(numbers,mean): # Calculate variance
sdev=0.0
for num in numbers:
sdev=sdev+(num-mean)**2
return pow(sdev/(len(numbers)-1),0.5)
def median(numbers): # Calculate the median
sorted(numbers)
size=len(numbers)
if size % 2 ==0:
med = (numbers[size//2-1]+numbers[size//2]/2)
else:
med = numbers[size//2]
return med
Dictionary type definition
Mapping is a kind of key ( Indexes ) And the value ( data ) Corresponding
The mapping type is defined by the user for the data index
Key value pair : Key is an extension of data index
A dictionary is a collection of key value pairs , Disorder between key value pairs
Generate Dictionary : use {} or dict() establish , Key value pair : Express
< Dictionary variables >={< key 1>:< value 1>,< key 2>:< value 2>,…,< key n>:< value n>}
You can also give it a new key value correspondence
< value >=< Dictionary variables >[< key >]
< Dictionary variables >[< key >]=< value >
{} Empty default build dictionary type 

Accurate model : Cut the text apart exactly , There are no redundant words
All model : Scan out all possible words in the text , There's redundancy
Search engine model : On the basis of the precise model , Again shred long words 

Statistics of text word frequency
def getText():
txt=open("hamlet.txt","r").read()
txt=txt.lower()
for ch in "'!#$%^&*()_+=<>,.{}{}:;'\|/":
txt=txt.replace(ch,"")
return txt
hamletTxt=getText()
words=hamletTxt.split()
counts={
}
for word in words:
counts[word]=count.get(word,0)+1
items=list(count.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count=items[i]
print("{0:<10}{1:>5}".format(word ,count))