個人主頁:黃小黃的博客主頁
️ 支持我: 點贊 收藏 關注
格言:一步一個腳印才能承接所謂的幸運本文來自專欄:Python基礎教程
歡迎點擊支持訂閱專欄 ️
本文對 Python 中的高級變量:列表、元組、字典進行了知識總結與講解。高級變量中的字符串由於內容比較多,博主將放在下篇:
【Python】高級變量通關教程下篇(字符串專題)
為大家講解,感興趣的同學可以訂閱專欄,或者關注一下我,不錯過第一時間的更新。好啦,閒話到此結束,開始高級變量的學習吧~~~
List 列表是 Python 中使用最頻繁的數據類型,在其他語言中通常為數組;[ ] 定義,數據之間使用 , 分隔;0 開始的下面我們來簡單定義一個列表,存儲三名學生的姓名,代碼如下:
students_name = ["黃小黃", "祢豆子", "我妻善逸"]
通過圖示,詳細了解列表的存儲結構:
列表的 查找值 只需要通過索引即可查找,如下代碼,結果見注釋:
students_name = ["黃小黃", "祢豆子", "我妻善逸"]
students_name[0] # 黃小黃
students_name[1] # 祢豆子
students_name[2] # 我妻善逸
需要注意的是,列表取值不能超過索引的最大值,即列表的長度 - 1,否則會報錯
如果需要 查找列表的索引, 則通過 index() 方法實現:
students_name = ["黃小黃", "祢豆子", "我妻善逸"]
students_name.index("黃小黃") # 0
students_name.index("祢豆子") # 1
students_name.index("我妻善逸") # 2
當然,如果傳遞的數據不在列表中,程序會報錯
修改列表數據 只需要通過索引直接修改:
students_name = ["黃小黃", "祢豆子", "我妻善逸"]
# 修改數據
students_name[1] = "大頭"
print(students_name) # ['黃小黃', '大頭', '我妻善逸']
如果希望 向列表中添加數據,則主要通過如下三個方法實現:
代碼示例如下:
students_name = [] # 先定義一個空列表
# 添加三條數據
students_name.append("黃小黃")
students_name.append("馬小淼")
students_name.append("大頭")
print(students_name) # ['黃小黃', '馬小淼', '大頭']
# 插入數據
students_name.insert(2, "小牛馬")
print(students_name) # ['黃小黃', '馬小淼', '小牛馬', '大頭']
# 拼接列表
my_list = ["小鵬", "幾何心涼"]
students_name.extend(my_list)
print(students_name) # ['黃小黃', '馬小淼', '小牛馬', '大頭', '小鵬', '幾何心涼']
結果: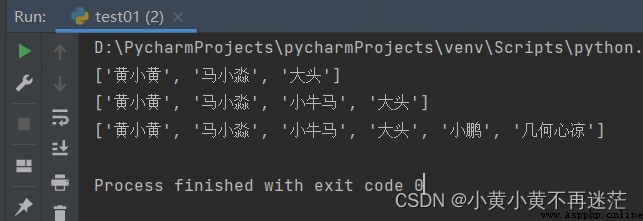
如果希望 從列表中刪除數據,則主要通過如下三個方法實現:
代碼示例如下:
mylist = ["黃小黃", "祢豆子", "漩渦鳴人", "草帽路飛"]
# 刪除指定數據
mylist.remove("黃小黃")
print(mylist) # ['祢豆子', '漩渦鳴人', '草帽路飛']
# 刪除末尾數據
mylist.pop()
print(mylist) # ['祢豆子', '漩渦鳴人']
# 清空
mylist.clear()
print(mylist) # []
結果: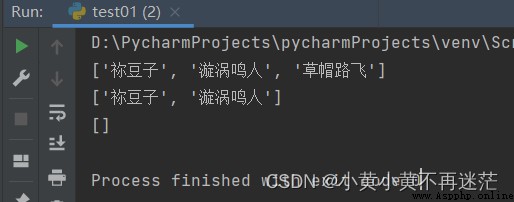
同時,刪除數據也可以通過 del 關鍵字實現,但是需要注意區別:使用 del 是從內存上刪除變量,後續的代碼就不能使用這個變量了
mylist = ["黃小黃", "祢豆子", "漩渦鳴人", "草帽路飛"]
del mylist[1]
print(mylist) # ['黃小黃', '漩渦鳴人', '草帽路飛']
del mylist
print(mylist) # NameError: name 'mylist' is not defined
常用的列表統計方法如下表:
參考代碼示例:
mylist = ["黃小黃", "祢豆子", "漩渦鳴人", "草帽路飛", "黃小黃"]
mylist_len = len(mylist)
print("列表的長度(元素個數): %d" % mylist_len) # 5
count = mylist.count("黃小黃")
print("黃小黃 出現的次數: %d" % count) # 2
結果: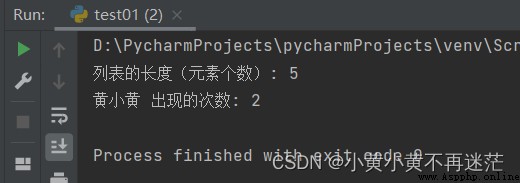
相關方法如下表:
需要注意的是,升序排序對於數字而言是從小到大;對於字符串和字符而言,是字典順序,比如 a 比 z 小
參考示例代碼:
words = ["abc", "Abc", "z", "dbff"]
nums = [9, 8, 4, 2, 2, 3]
# 升序排序
words.sort()
nums.sort()
print(words) # ['Abc', 'abc', 'dbff', 'z']
print(nums) # [2, 2, 3, 4, 8, 9]
# 降序排序
words.sort(reverse=True)
nums.sort(reverse=True)
print(words) # ['z', 'dbff', 'abc', 'Abc']
print(nums) # [9, 8, 4, 3, 2, 2]
# 反轉
nums.reverse()
print(nums) # [2, 2, 3, 4, 8, 9]
結果: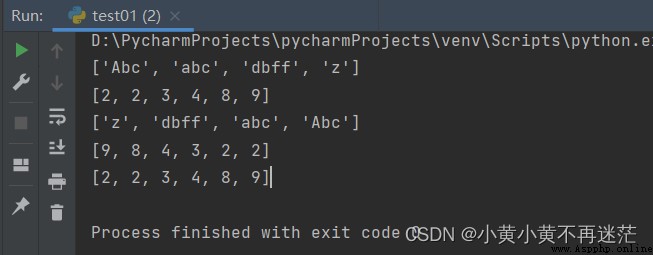
遍歷是指從頭到尾依次從列表中獲取數據,使用 for 循環就很容易實現,語法基礎格式如下:
# for 循環內部使用的變量 in 列表
for name in name_list:
# 循環內部對列表進行的操作
print(name) # 比如打印
示例代碼與結果:
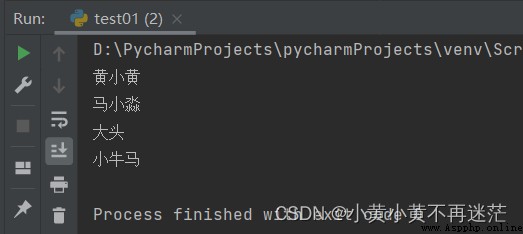
student_list = ["黃小黃", "馬小淼", "大頭", "小牛馬"]
# 迭代遍歷
for student in student_list:
print(student)
Tuple 元組與列表類似,最大的區別是元組的 元素不能修改, 分隔;( ) 定義,索引從 0 開始。示例1️⃣ 創建一個空元組
tuple = ()
示例2️⃣ 創建一個元組
tuple = ("黃小黃", "路飛", "娜美")
元組只包含一個元素時,需要在元素後面加 ,
由於元組中的元素是不可變的,因此 python 提供的元組方法通常為只讀,常用的有
index()和count()
示例代碼與結果:
my_tuple = ("黃小黃", "馬小淼", "草帽路飛", "黃小黃")
# 讀取索引
print(my_tuple.index("馬小淼")) # 1
# 統計出現次數
print(my_tuple.count("黃小黃")) # 2
與列表的遍歷類似,但是在實際開發中,我們並不常常遍歷元組,除非能夠確認 元組中元素的數據類型。
# for 循環內部使用的變量 in 元組
for name in name_touple:
# 循環內部對元組進行的操作
print(name) # 比如打印
小結:在 Python 中可以使用 for 循環遍歷所有非數字類型的變量:列表、元組、字符串以及字典
list 函數實現tuple 函數實現參考代碼:
temp_tuple = ("黃小黃", "馬小淼", "草帽路飛")
my_list = list(temp_tuple)
print(my_list)
print(type(my_list))
my_tuple = tuple(my_list)
print(my_tuple)
print(type(my_tuple))
結果: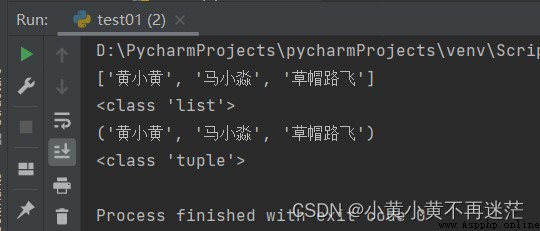
{} 定義,是 無序的對象集合;, 分隔;key 是索引,值 value 是數據;: 分隔;下面我們來簡單定義一個字典,代碼如下:
nezuko = {
"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
通過圖示,詳細了解字典的存儲結構: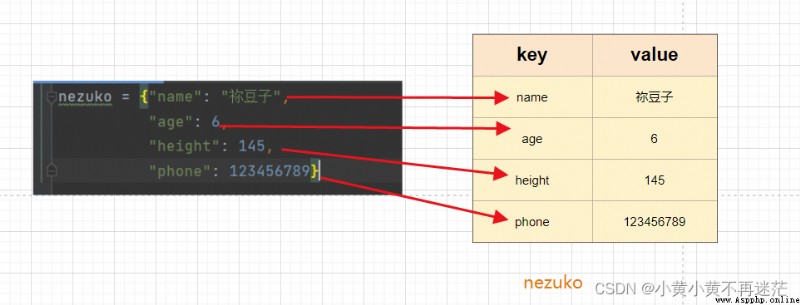
️ 通過對列表和元組的學習,想必已經對索引取值已經增添刪除數據有了一定的認識,這裡直接上代碼舉例:
1. 查找值
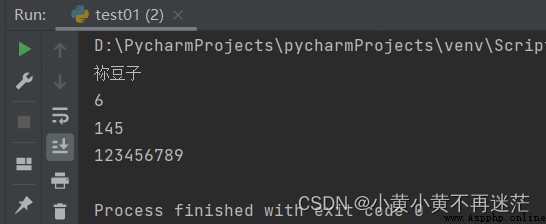
字典的取值同樣通過索引的方式來取值,只不過,字典的索引是key。需要注意的是,進行取值操作時,如果指定的key不存在,程序會報錯!
nezuko = {
"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 查找值,取值
print(nezuko["name"])
print(nezuko["age"])
print(nezuko["height"])
print(nezuko["phone"])
2. 增添及修改值
在 python 中增添與修改值很簡單,只需要使用索引添加或修改。如果key存在,則會修改數據;如果key不存在,則會新增鍵值對。
nezuko = {
"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 添加
nezuko["性別"] = "女"
# 修改
nezuko["age"] = 3
# 打印
print(nezuko)

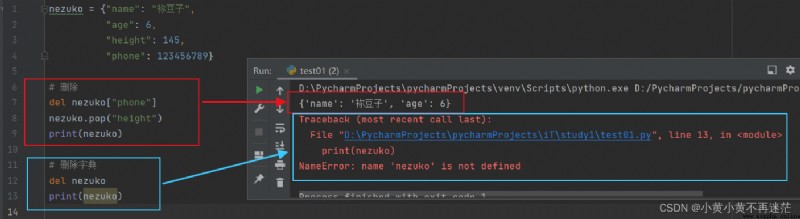
3. 刪除值與字典
刪除有兩種方式,使用 pop() 方法指定 key 刪除或者使用關鍵字 del 並指定 key 刪除。當然,也可以通過 del 關鍵字刪除字典。
nezuko = {
"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 刪除
del nezuko["phone"]
nezuko.pop("height")
print(nezuko)
# 刪除字典
del nezuko
print(nezuko)
涉及到的方法一覽表:
示例代碼:
nezuko = {
"name": "祢豆子",
"age": 6,
"height": 145,
"phone": 123456789}
# 統計鍵值對個數
nezuko_count = len(nezuko)
print("字典 nezuko 鍵值對個數為: %d" % nezuko_count)
# 合並兩個字典
nezuko_new = {
"性別": "女",
"愛好": "咬竹筒",
"age": 10}
nezuko.update(nezuko_new)
print("合並後" + str(nezuko))
# 清空列表元素
nezuko.clear()
print("清空後: " + str(nezuko))
結果:
在實際開發中,字典的遍歷需求並不多,因為我們無法確定字典中的每一個鍵值對保存的數據類型。
遍歷語法:
# for 循環內部使用的 key 變量 in 字典名
for k in dict:
# 具體操作
print("%s: %s" % (k, dict[k]))
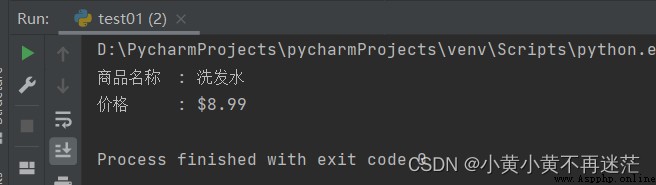
示例代碼及結果:
commodities = {
"商品名稱": "洗發水",
"價格": "$8.99"}
# 遍歷
for k in commodities:
print("%s \t: %s" % (k, commodities[k]))
示例代碼與結果:
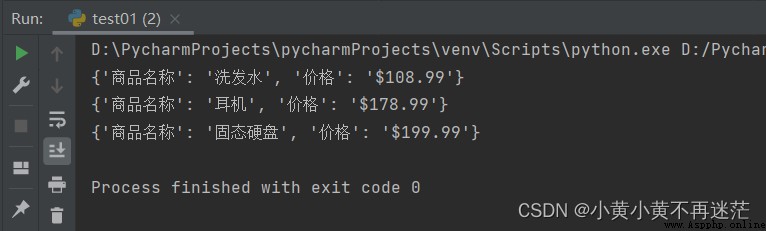
嘗試將物品信息存儲為字典,並將所有物品存儲到列表中進行遍歷修改
commodities_list = [
{
"商品名稱": "洗發水", "價格": "$8.99"},
{
"商品名稱": "耳機", "價格": "$78.99"},
{
"商品名稱": "固態硬盤", "價格": "$99.99"},
]
# 遍歷 給所有商品價格增加100 並打印
for commodity in commodities_list:
# 這裡使用了 lstrip 對字符串進行了首字符刪除 後面會講 先忽略
commodity["價格"] = "$" + str(float(commodity["價格"].lstrip("$")) + 100)
print(commodity)
以上便是本文的全部內容啦,後續內容將會持續免費更新,如果文章對你有所幫助,麻煩動動小手點個贊 + 關注,非常感謝 ️ ️ ️ !
如果有問題,歡迎私信或者評論區!
共勉:“你間歇性的努力和蒙混過日子,都是對之前努力的清零。”