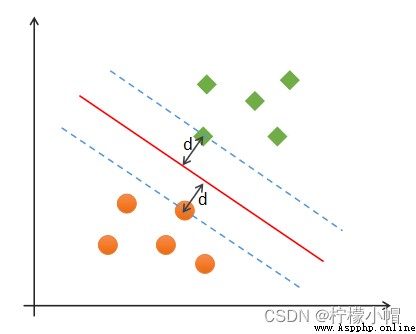
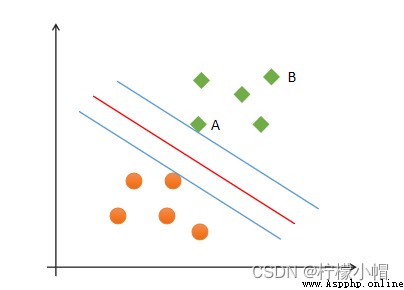
(1)正確性:對大部分樣本都可以正確劃分類別;
(2)安全性:支持向量,即離分類邊界最近的樣本之間的距離最遠;
(3)公平性:支持向量與分類邊界的距離相等;
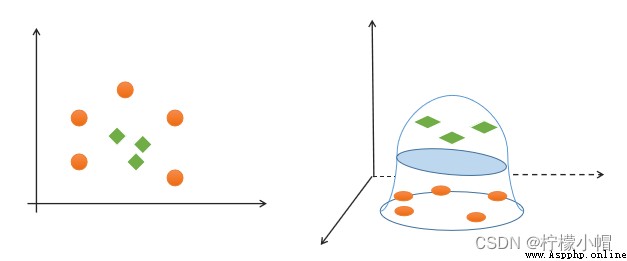
(4)簡單性:采用線性方程(直線、平面)表示分類邊界,也稱分割超平面。如果在原始維度中無法做線性劃分,那麼就通過升維變換,在更高維度空間尋求線性分割超平面. 從低緯度空間到高緯度空間的變換通過核函數進行。
如果一組樣本能使用一個線性函數將樣本正確分類,稱這些數據樣本是線性可分的。那麼什麼是線性函數呢?在二維空間中就是一條直線,在三維空間中就是一個平面,以此類推,如果不考慮空間維數,這樣的線性函數統稱為超平面。
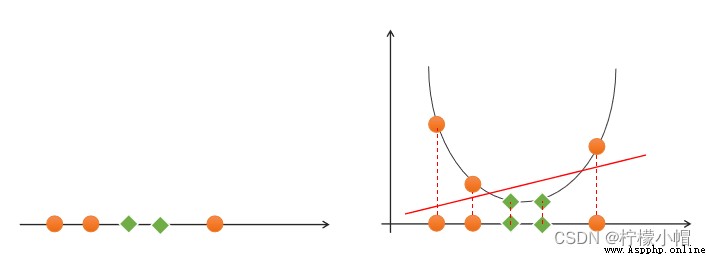
如果一組樣本,無法找到一個線性函數將樣本正確分類,則稱這些樣本線性不可分。以下是一個一維線性不可分的示例:

# 支持向量機示例
import numpy as np
import sklearn.model_selection as ms
import sklearn.svm as svm
import sklearn.metrics as sm
import matplotlib.pyplot as mp
x, y = [], []
with open("../data/multiple2.txt", "r") as f:
for line in f.readlines():
data = [float(substr) for substr in line.split(",")]
x.append(data[:-1]) # 輸入
y.append(data[-1]) # 輸出
# 列表轉數組
x = np.array(x)
y = np.array(y, dtype=int)
# 線性核函數支持向量機分類器
model = svm.SVC(kernel="linear") # 線性核函數
# model = svm.SVC(kernel="poly", degree=3) # 多項式核函數
# print("gamma:", model.gamma)
# 徑向基核函數支持向量機分類器
# model = svm.SVC(kernel="rbf",
# gamma=0.01, # 概率密度標准差
# C=200) # 概率強度
model.fit(x, y)
# 計算圖形邊界
l, r, h = x[:, 0].min() - 1, x[:, 0].max() + 1, 0.005
b, t, v = x[:, 1].min() - 1, x[:, 1].max() + 1, 0.005
# 生成網格矩陣
grid_x = np.meshgrid(np.arange(l, r, h), np.arange(b, t, v))
flat_x = np.c_[grid_x[0].ravel(), grid_x[1].ravel()] # 合並
flat_y = model.predict(flat_x) # 根據網格矩陣預測分類
grid_y = flat_y.reshape(grid_x[0].shape) # 還原形狀
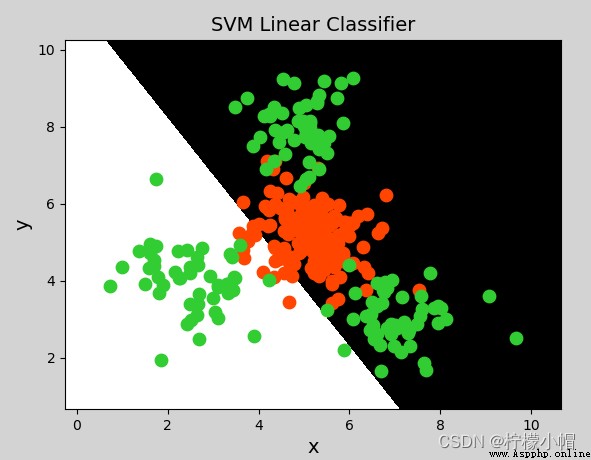
mp.figure("SVM Classifier", facecolor="lightgray")
mp.title("SVM Classifier", fontsize=14)
mp.xlabel("x", fontsize=14)
mp.ylabel("y", fontsize=14)
mp.tick_params(labelsize=10)
mp.pcolormesh(grid_x[0], grid_x[1], grid_y, cmap="gray")
C0, C1 = (y == 0), (y == 1)
mp.scatter(x[C0][:, 0], x[C0][:, 1], c="orangered", s=80)
mp.scatter(x[C1][:, 0], x[C1][:, 1], c="limegreen", s=80)
mp.show()
y = x 1 + x 2 y = x 1 2 + 2 x 1 x 2 + x 2 2 y = x 1 3 + 3 x 1 2 x 2 + 3 x 1 x 2 2 + x 2 3 y = x_1 + x_2\\ y = x_1^2 + 2x_1x_2+x_2^2\\ y=x_1^3 + 3x_1^2x_2 + 3x_1x_2^2 + x_2^3 y=x1+x2y=x12+2x1x2+x22y=x13+3x12x2+3x1x22+x23
model = svm.SVC(kernel="poly", degree=3) # 多項式核函數
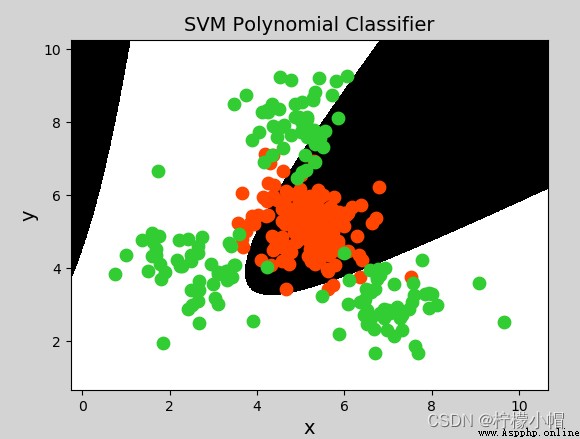
# 徑向基核函數支持向量機分類器
model = svm.SVC(kernel="rbf",
gamma=0.01, # 概率密度標准差
C=600) # 概率強度,該值越大對錯誤分類的容忍度越小,分類精度越高,但泛化能力越差;該值越小,對錯誤分類容忍度越大,但泛化能力強
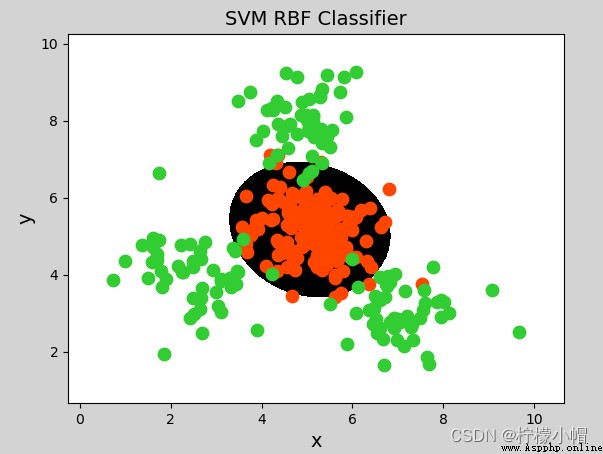
model = svm.SVC(kernel='linear')
model.fit(train_x, train_y)
# 基於線性核函數的支持向量機分類器
model = svm.SVC(kernel='poly', degree=3)
model.fit(train_x, train_y)
# 基於徑向基核函數的支持向量機分類器
# C:正則強度
# gamma:'rbf','poly'和'sigmoid'的內核函數。伽馬值越高,則會精確擬合訓練數據集,有可能導致過擬合問題。
model = svm.SVC(kernel='rbf', C=600, gamma=0.01)
model.fit(train_x, train_y)
(1)支持向量機是二分類模型
(2)支持向量機通過尋找最優線性模型作為分類邊界
(3)邊界要求:正確性、公平性、安全性、簡單性
(4)可以通過核函數將線性不可分轉換為線性可分問題,核函數包括:線性核函數、多項式核函數、徑向基核函數
(5)支持向量機適合少量樣本的分類
import sklearn.model_selection as ms
params =
[{
'kernel':['linear'], 'C':[1, 10, 100, 1000]},
{
'kernel':['poly'], 'C':[1], 'degree':[2, 3]},
{
'kernel':['rbf'], 'C':[1,10,100], 'gamma':[1, 0.1, 0.01]}]
model = ms.GridSearchCV(模型, params, cv=交叉驗證次數)
model.fit(輸入集,輸出集)
# 獲取網格搜索每個參數組合
model.cv_results_['params']
# 獲取網格搜索每個參數組合所對應的平均測試分值
model.cv_results_['mean_test_score']
# 獲取最好的參數
model.best_params_
model.best_score_
model.best_estimator_
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv('multiple2.txt', header=None, names=['x1', 'x2', 'y'])
data.plot.scatter(x='x1', y='x2', c='y', cmap='brg')
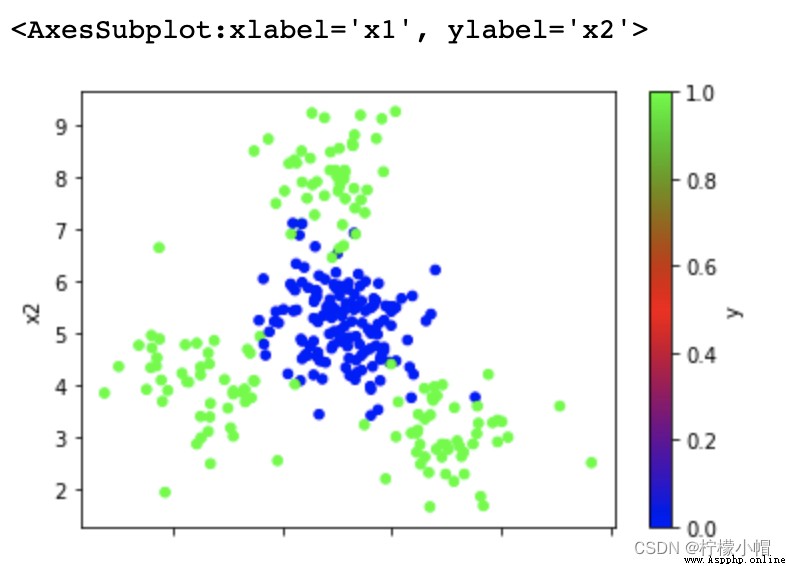
import sklearn.model_selection as ms
import sklearn.svm as svm
import sklearn.metrics as sm
# 整理數據集,拆分測試集訓練集
x, y = data.iloc[:, :-1], data['y']
train_x, test_x, train_y, test_y = ms.train_test_split(x, y, test_size=0.25, random_state=7)
model = svm.SVC(kernel='linear')
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
print(sm.classification_report(test_y, pred_test_y))
""" precision recall f1-score support 0 0.69 0.90 0.78 40 1 0.83 0.54 0.66 35 accuracy 0.73 75 macro avg 0.76 0.72 0.72 75 weighted avg 0.75 0.73 0.72 75 """
data.head()
""" x1 x2 y 0 5.35 4.48 0 1 6.72 5.37 0 2 3.57 5.25 0 3 4.77 7.65 1 4 2.25 4.07 1 """
# 暴力繪制分類邊界線
# 從x的min-max,拆出100個x坐標
# 從y的min-max,拆出100個y坐標
# 一共組成10000個坐標點,預測每個坐標點的類別標簽,繪制散點
xs = np.linspace(data['x1'].min(), data['x1'].max(), 100)
ys = np.linspace(data['x2'].min(), data['x2'].max(), 100)
points = []
for x in xs:
for y in ys:
points.append([x, y])
points = np.array(points)
# 預測每個坐標點的類別標簽 繪制散點
point_labels = model.predict(points)
plt.scatter(points[:,0], points[:,1], c=point_labels, cmap='gray')
plt.scatter(test_x['x1'], test_x['x2'], c=test_y, cmap='brg')
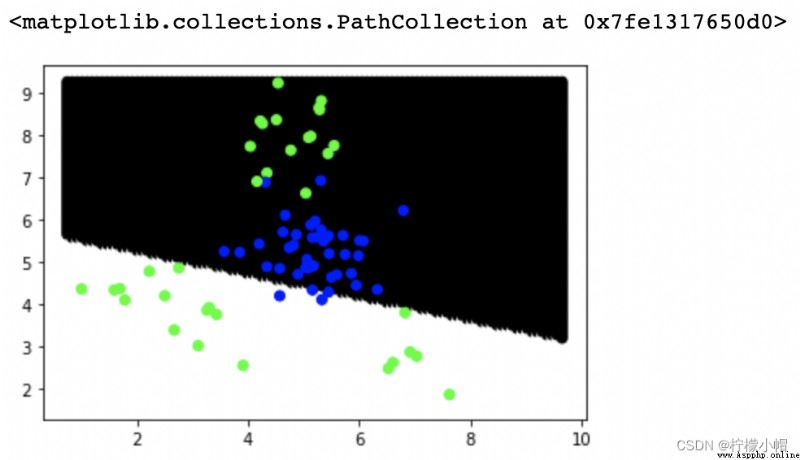
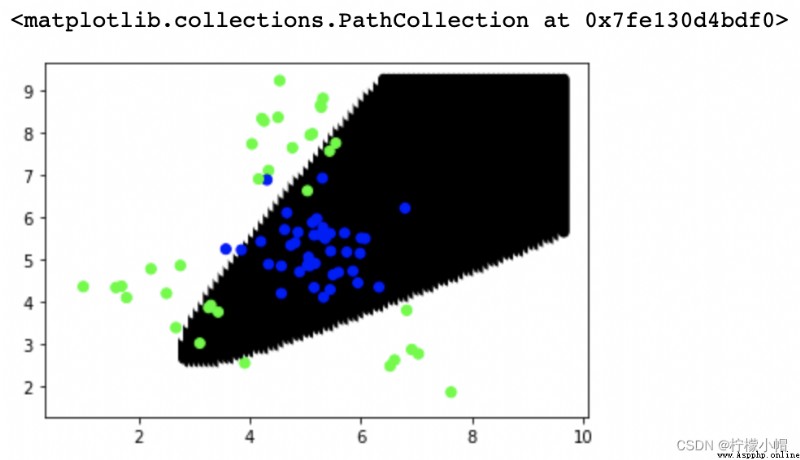
# 多項式核函數
model = svm.SVC(kernel='poly', degree=2)
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
print(sm.classification_report(test_y, pred_test_y))
# 預測每個坐標點的類別標簽 繪制散點
point_labels = model.predict(points)
plt.scatter(points[:,0], points[:,1], c=point_labels, cmap='gray')
plt.scatter(test_x['x1'], test_x['x2'], c=test_y, cmap='brg')
""" precision recall f1-score support 0 0.84 0.95 0.89 40 1 0.93 0.80 0.86 35 accuracy 0.88 75 macro avg 0.89 0.88 0.88 75 weighted avg 0.89 0.88 0.88 75 """
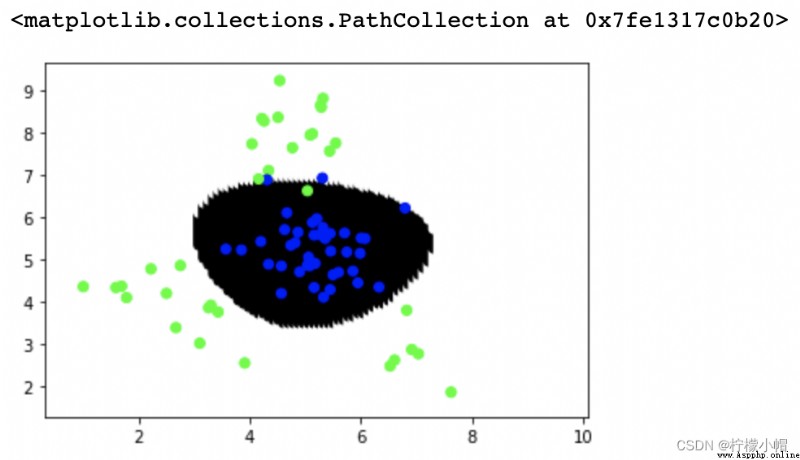
# 徑向基核函數
model = svm.SVC(kernel='rbf', C=1, gamma=0.1)
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
# print(sm.classification_report(test_y, pred_test_y))
# 預測每個坐標點的類別標簽 繪制散點
point_labels = model.predict(points)
plt.scatter(points[:,0], points[:,1], c=point_labels, cmap='gray')
plt.scatter(test_x['x1'], test_x['x2'], c=test_y, cmap='brg')
""" precision recall f1-score support 0 0.97 0.97 0.97 40 1 0.97 0.97 0.97 35 accuracy 0.97 75 macro avg 0.97 0.97 0.97 75 weighted avg 0.97 0.97 0.97 75 """
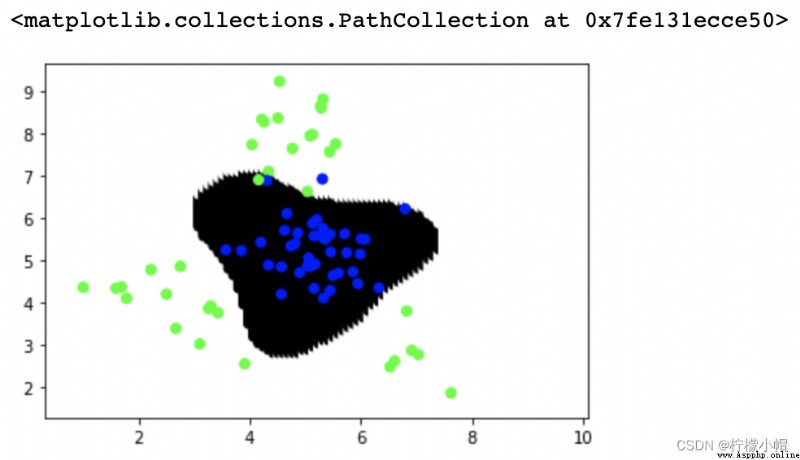
# 通過網格搜索尋求最優超參數組合
model = svm.SVC()
# 網格搜索
params = [{
'kernel':['linear'], 'C':[1, 10, 100]},
{
'kernel':['poly'], 'degree':[2, 3]},
{
'kernel':['rbf'], 'C':[1, 10, 100], 'gamma':[1, 0.1, 0.001]}]
model = ms.GridSearchCV(model, params, cv=5)
model.fit(train_x, train_y)
pred_test_y = model.predict(test_x)
# print(sm.classification_report(test_y, pred_test_y))
# 預測每個坐標點的類別標簽 繪制散點
point_labels = model.predict(points)
plt.scatter(points[:,0], points[:,1], c=point_labels, cmap='gray')
plt.scatter(test_x['x1'], test_x['x2'], c=test_y, cmap='brg')
print(model.best_params_)
print(model.best_score_)
print(model.best_estimator_)
""" {'C': 1, 'gamma': 1, 'kernel': 'rbf'} 0.9511111111111111 SVC(C=1, gamma=1) """