In the process of data analysis and modeling , Quite a lot of time is spent on data preparation : load 、 clear 、 Transform and reshape . These jobs will take up the analyst's time 80% Or more . Sometimes , The format of data stored in files and databases is not suitable for a particular task . Many researchers choose to use a general-purpose programming language ( Such as Python、Perl、R or Java) or UNIX Text processing tools ( Such as sed or awk) Specialized processing of data formats . Fortunately, ,pandas And built-in Python The standard library provides a set of advanced 、 agile 、 A quick tool , It allows you to easily organize the data into the desired format .
If you find a book or pandas There is no data operation mode in the library , Please check your mailing list or GitHub Proposed on the website . actually ,pandas Many of the design and implementation of is driven by the requirements of real applications .
In this chapter , I will talk about dealing with missing data 、 Duplicate data 、 String manipulation and other tools for analyzing data conversion . Next chapter , I will focus on merging in a number of ways 、 Reshape the data set .
In many data analysis work , Missing data often occurs .pandas One of our goals is to handle missing data as easily as possible . for example ,pandas All descriptive statistics of the object do not include missing data by default .
Missing data in pandas There are some imperfections in the way presented in , But for most users, it can guarantee normal functions . For numerical data ,pandas Use floating point values NaN(Not a Number) Indicates missing data . We call it sentry value , It can be easily detected :
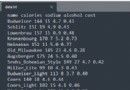
In [10]: string_data