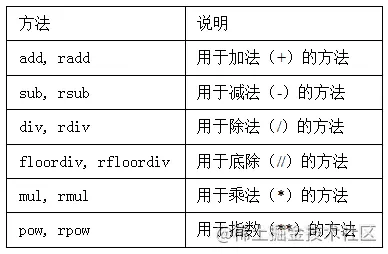
當我在2011年和2012年寫作本書的第一版時,可用的學習Python數據分析的資源很少。這部分上是一個雞和蛋的問題:我們現在使用的庫,比如pandas、scikit-learn和statsmodels,那時相對來說並不成熟。2017年,數據科學、數據分析和機器學習的資源已經很多,原來通用的科學計算拓展到了計算機科學家、物理學家和其它研究領域的工作人員。學習Python和成為軟件工程師的優秀書籍也有了。
因為這本書是專注於Python數據處理的,對於一些Python的數據結構和庫的特性難免不足。因此,本章和第3章的內容只夠你能學習本書後面的內容。
在我來看,沒有必要為了數據分析而去精通Python。我鼓勵你使用IPython shell和Jupyter試驗示例代碼,並學習不同類型、函數和方法的文檔。雖然我已盡力讓本書內容循序漸進,但讀者偶爾仍會碰到沒有之前介紹過的內容。
本書大部分內容關注的是基於表格的分析和處理大規模數據集的數據准備工具。為了使用這些工具,必須首先將混亂的數據規整為整潔的表格(或結構化)形式。幸好,Python是一個理想的語言,可以快速整理數據。Python使用得越熟練,越容易准備新數據集以進行分析。
最好在IPython和Jupyter中親自嘗試本書中使用的工具。當你學會了如何啟動Ipython和Jupyter,我建議你跟隨示例代碼進行練習。與任何鍵盤驅動的操作環境一樣,記住常見的命令也是學習曲線的一部分。
筆記:本章沒有介紹Python的某些概念,如類和面向對象編程,你可能會發現它們在Python數據分析中很有用。 為了加