utilize python Crawling website data is very convenient , Very efficient , But the most common is to use BeautifSoup、requests Match and combine to grab static pages ( That is, the data displayed on the web page can be displayed in html Source code found in , Not through the website js perhaps ajax Asynchronously loaded ), This type of website data is easy to climb up . But some websites use data through execution js Code to update , At this time, the traditional method is not so applicable . In this case, there are several methods :
Empty on Web page network Information , Update page , Watch the requests sent by the web page , Some websites can construct parameters in this way , To simplify reptiles . But the scope of application is not wide enough .
Use selenium Simulate browser behavior to update web pages to obtain updated data . This article then focuses on this method .
Simulation browser requires two tools :
1.selenium, Directly through pip install selenium Installation .
2.PhantomJS, This is an interface free , Scriptable WebKit Browser engine , Baidu search , Download it on its official website , No need to install after download , Put it under the specified path , When using, you only need to specify the path where the file is located .
The example of crawling website in this article is :http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346( The latest test found that the website could not be opened ,2021 year 5 month 25 Japan )
Please don't crawl too many pages when learning the examples , Just go through the process and know how to catch it .
After opening the website , You can see that the data to be crawled is a regular table , But there are many pages .
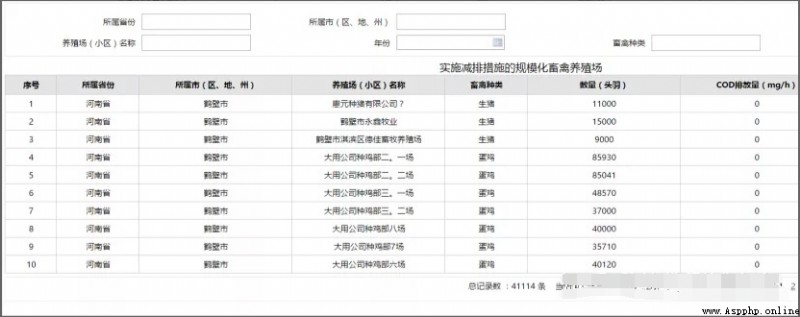
In this website , Click... On the next page url No change , By executing a paragraph js Code update page . Therefore, the idea of this paper is to use selenium Simulate the browser to click , Click on “ The next page ” Update the page data after , Get the updated page data . Here is the complete code :
# -*- coding:utf-8 -*- import requests from bs4 import BeautifulSoup import json import time from selenium import webdriver import sys reload(sys) sys.setdefaultencoding( "utf-8" ) curpath=sys.path[0] print curpath def getData(url): # Use the downloaded phantomjs, It's also used online firefox,chrome, But I didn't succeed , It's also very convenient to use this driver =webdriver.PhantomJS(executable_path="C:/phantomjs.exe") driver.set_page_load_timeout(30) time.sleep(3) html=driver.get(url[0]) # Use get Method request url, Because it's an analog browser , So no need headers Information for page in range(3): html=driver.page_source # Get the html data soup=BeautifulSoup(html,'lxml') # Yes html To analyze , If you are prompted lxml Not installed , direct pip install lxml that will do table=soup.find('table',class_="report-table") name=[] for th in table.find_all('tr')[0].find_all('th'): name.append(th.get_text()) # Get the field name of the table as the key of the dictionary flag=0 # Mark , When crawling field data is 0, Otherwise 1 for tr in table.find_all('tr'): # The first line is table field data , So skip the first line if flag==1: dic={
}
i=0
for td in tr.find_all('td'):
dic[name[i]]=td.get_text()
i+=1
jsonDump(dic,url[1])# Save the data
flag=1
# utilize find_element_by_link_text Method to get the location of the next page and click , After clicking, the page will automatically update , Just recapture driver.page_source that will do
driver.find_element_by_link_text(u" The next page ").click()
def jsonDump(_json,name):
"""store json data"""
with open(curpath+'/'+name+'.json','a') as outfile:
json.dump(_json,outfile,ensure_ascii=False)
with open(curpath+'/'+name+'.json','a') as outfile:
outfile.write(',\n')
if __name__ == '__main__':
url=['http://datacenter.mep.gov.cn:8099/ths-report/report!list.action?xmlname=1465594312346','yzc'] # yzc For the file name , If you enter Chinese here, an error will be reported , Add in front u Not good either. , You have to change the file name manually after saving ……
getData(url) # Call function
The location of the next page in this article is obtained through driver.find_element_by_link_text Method to achieve , This is because in this page , This tag has no unique identifier id, either class, If you pass xpath Positioning words , On page 1 and other pages xpath The path is not exactly the same , I need to add one if Judge . So straight through link Of text Parameter positioning .click() Function to simulate the click operation in the browser .
selenium It's very powerful , When used on reptiles, it can solve many problems that ordinary reptiles can't solve , It can simulate clicking 、 Mouse movement , You can submit forms ( Applications such as : Login email account 、 land wifi etc. , There are many examples online , I haven't tried yet ), When you encounter some unconventional website data, it is very difficult to climb up , Try it selenium+phantomjs.
Finally, thank everyone who reads my article carefully , The following online link is also a very comprehensive one that I spent a few days sorting out , I hope it can also help you in need !
These materials , For those who want to change careers 【 software test 】 For our friends, it should be the most comprehensive and complete war preparation warehouse , This warehouse also accompanied me through the most difficult journey , I hope it can help you ! Everything should be done as soon as possible , Especially in the technology industry , We must improve our technical skills . I hope that's helpful ……
If you don't want to grow up alone , Unable to find the information of the system , The problem is not helped , If you insist on giving up after a few days , You can click the small card below to join our group , We can discuss and exchange , There will be various software testing materials and technical exchanges .
Click the small card at the end of the document to receive itTyping is not easy , If this article is helpful to you , Click a like, collect a hide and pay attention , Give the author an encouragement . It's also convenient for you to find it quickly next time .
Zero basis transition software testing :25 Days from zero basis to software testing post , I finished today , Employment tomorrow .【 Include features / Interface / automation /python automated testing / performance / Test Development 】
Advanced automation testing :2022B The first station is super detailed python Practical course of automated software testing , Prepare for the golden, silver and four job hopping season , After advanced learning, it soared 20K